






最近读了 @王喆 师兄的《深度学习推荐系统》,书中关于Embedding的阐述十分受用,在此稍作总结。
Embedding是什么
Embedding,中文直译是“嵌入”,更好懂的译法是“向量映射”,简单来说就是用向量来表示实体。这里所说是实体,可以是人,也可以是物品,用于表示不同实体的向量一般是不同的。
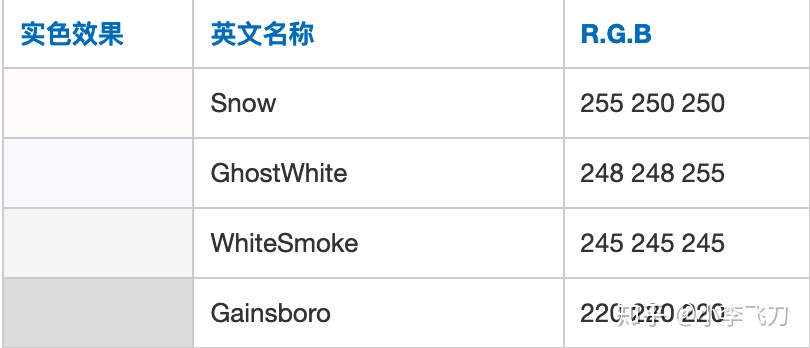
借用邱老师在《神经网络与深度学习》中的例子,用RGB三个维度可以表示一种颜色,RGB这个三维向量就是Embedding,颜色就是实体,每个颜色有唯一的RGB值,就好比每个实体有自己的Embedding。
为什么需要Embedding
不论采用什么方式建模,都是基于数学运算,所以我们需要把实体表示成数字,这是我们需要Embedding的根本原因。
在实际问题中,我们很难获得像RGB这样物理意义明确的Embedding,此时我们只能退而求其次,用一种笨笨的方法来生成Embedding——One(Multi) Hot Embedding。比如在推荐系统里,商家有5件商品,Embedding就是5维向量,第一个商品的Embedding就是[1,0,0,0,0]。
与RGB稍作比较,就会发现One Hot的不足。首先,One Hot的每一维只表示某个商品的有无,信息量太少;其次,One Hot的维度会随着商品数量的增加而增加,可能造成维度爆炸,计算复杂度过高。
因此,我们需要找到一个类似RGB的稠密向量来表示一个商品,这个稠密向量就是我们在深度学习领域常说的Embedding。
如何生成Embedding
生成Embedding的方法可以归类为三种,分别是矩阵分解,无监督建模和有监督建模。
矩阵分解
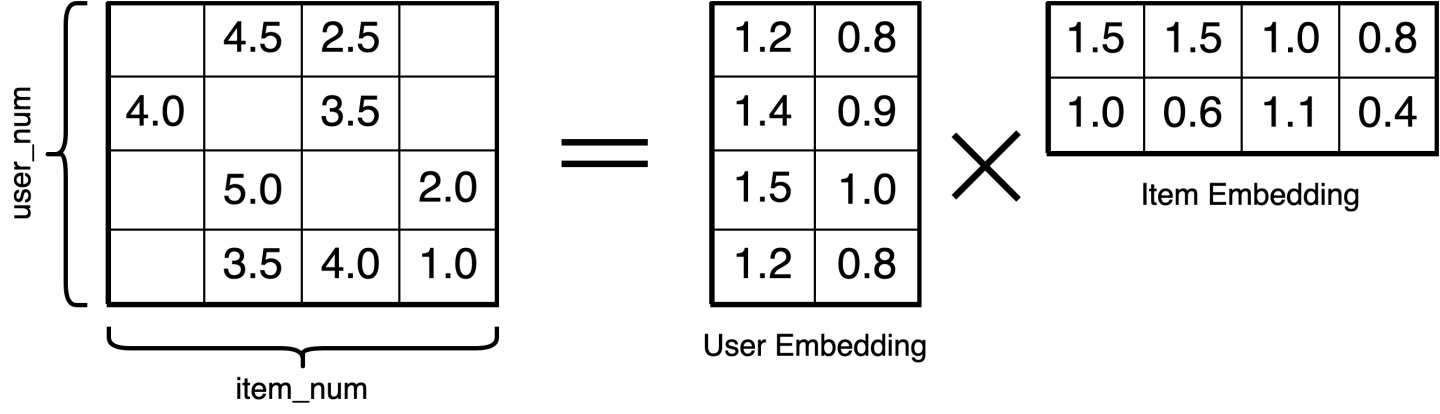
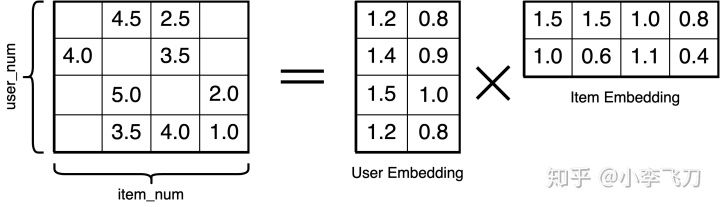
矩阵分解是将两种实体间的关系矩阵分解为两个Embedding矩阵,得到每一种实体的Embedding,比如在推荐系统里,我们已知用户与商品的共现矩阵,通过矩阵分解可以得到每个用户的Embedding和每个商品的Embedding。
这种求解Embedding的方法最直接有效,但是只能用于求解用户和商品的共现矩阵,无法处理用户的属性(比如性别、年龄)和商品的属性(比如价格、类别)。
无监督建模
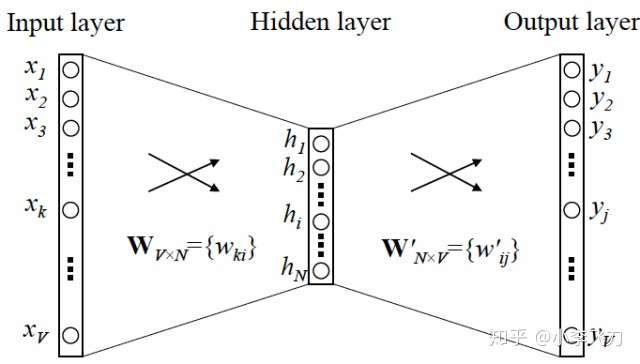
无监督建模是生成Embedding的常用方法,按组织方式可以将数据分为序列和图两类,针对序列数据生成Embedding常采用word2vec或类似算法(item2vec, doc2vec等),针对图数据生成Embedding的算法称为Graph Embedding,这类算法包括deepwalk、node2vec、struc2vec等,它们大多采用随机游走方式生成序列,底层同样也是word2vec算法。关于word2vec算法的实现细节,此处不再赘述。
有监督建模
有监督建模也可以用于生成Embedding,主要分为两类,一类是因子分解机及其衍生算法,包括FM、FFM、DeepFM等,另一类是图卷积算法,包括GCN、GraphSAGE、GAT等,这些模型中都包含Embedding层,在建模有监督问题时,每个实体在Embedding层的输出向量可以作为这个实体的Embedding使用。
理解Embedding
Embedding最重要的属性是:越“相似”的实体,Embedding之间的距离越小。以word2vec模型为例,如果两个词的上下文几乎相同,就意味着它们的输出值几乎相同,在模型收敛的前提下,两个词在Embedding层的输出值一定非常相近。在推荐系统里,可以计算实体间的余弦相似度,召回相似度高的商品作为备选推荐商品,这是Embedding内在属性的一种简单的应用。
此外,相比RGB,Embedding最大的劣势是无法解释每个维度的含义,这也是复杂机器学习模型的通病。
欢迎点赞、喜欢、收藏~
在求知的路上,你永不独行~
最后安利一下师兄的大作:














 817
817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









