




 Apache NIFI是一个强大的数据处理和分发工具,以其易用性、强大功能和可靠性著称。它提供了一系列开箱即用的处理器,用于处理各种数据源和格式,适用于数据多样性的场景。NIFI通过直观的图形界面构建数据pipeline,简化了复杂的数据流程,同时具备数据血缘和追踪机制,确保数据可靠性。在微服务和物联网时代,NIFI在数据路由和集成方面扮演重要角色,帮助组织理解和管理复杂的数据流程。
Apache NIFI是一个强大的数据处理和分发工具,以其易用性、强大功能和可靠性著称。它提供了一系列开箱即用的处理器,用于处理各种数据源和格式,适用于数据多样性的场景。NIFI通过直观的图形界面构建数据pipeline,简化了复杂的数据流程,同时具备数据血缘和追踪机制,确保数据可靠性。在微服务和物联网时代,NIFI在数据路由和集成方面扮演重要角色,帮助组织理解和管理复杂的数据流程。
Apache NIFI入门(读完即入门)
编辑人(全网同名):酷酷的诚 邮箱:zhangchengk@foxmail.com
我将在本文中介绍:
- 什么是ApacheNIFI,应在什么情况下使用它,理解在NIFI中的关键概念。
我不会介绍的内容:
-NIFI集群的安装,部署,监视,安全性和管理。
什么是ApacheNIFI?
在ApacheNIFI项目的官网上,可以找到以下定义:
一个易于使用,功能强大且可靠处理和分发数据的系统。
接下来我们分析一下关键字。
NIFI定义
处理和分发数据
这是NIFI的要旨。它可以在系统中移动数据,并为你提供处理该数据的工具。
NIFI可以处理各种各样的数据源和不同格式的数据。你可以从一个源中获取数据,对其进行转换,然后将其推送到另一个目标存储地。
易于使用
Processors-boxes-通过连接器链接-箭头创建流程。NIFI提供了一个基于流的编程体验。
NIFI让我们一眼就能理解一组数据流操作,而这或许将需要数百行源代码来实现。
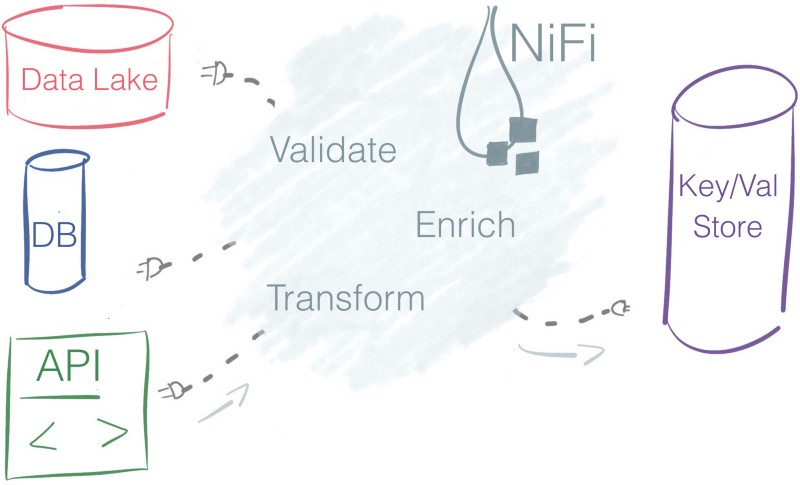
考虑下面的pipeline:
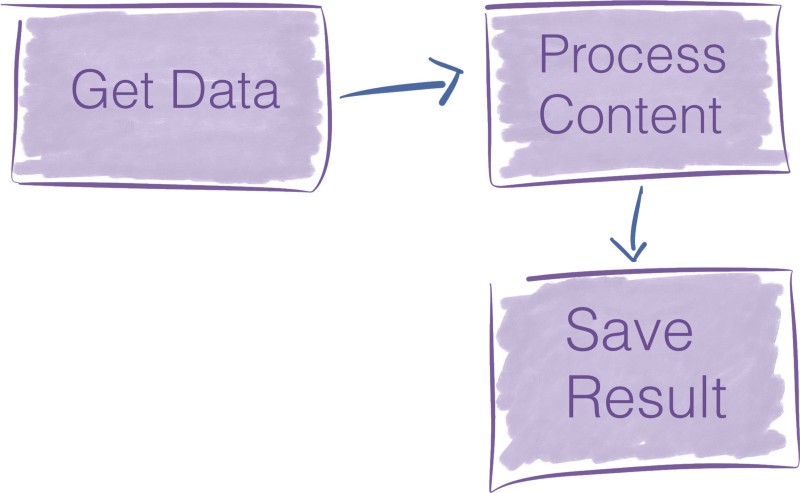
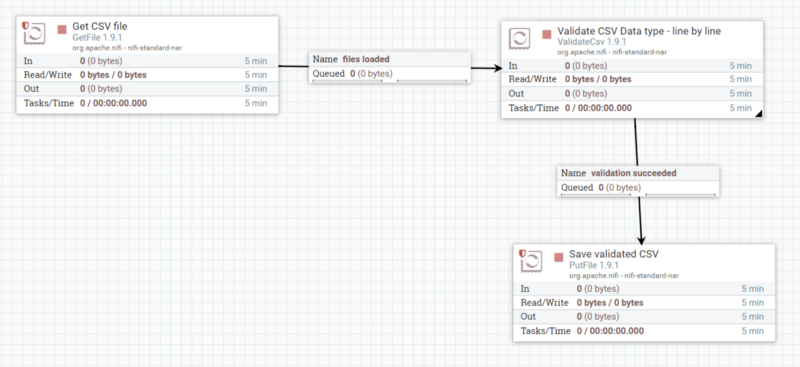
如果要在NIFI中实现转换上述的数据流,只需在NIFI图形用户界面,将三个组件拖放到画布中,然后连接做配置。也就需要个两分钟。
而如果你编写代码来执行相同的操作,则可能需要数百行才能达到相似的结果。
NIFI在构建数据pipeline方面更具表现力,我们不需要写代码,而NIFI就是为此而设计的。
强大
NIFI提供了许多开箱即用的处理器。使用者其实是站在巨人的肩膀上。这些标准处理器可以处理你可能遇到的绝大多数需求。
NIFI是高度并发的,但其内部封装了相关的复杂性。我们看到的处理器是一个高级抽象,它掩盖了并行编程固有的复杂性。我们可以多个处理器一起运行,一个处理器也可以有多个线程运行。
并发是你不希望打开的计算型Pandora盒。NIFI使得pipeline构建器免受并发复杂性的影响。
可靠
NIFI的设计实现具有扎实的理论基础。与SEDA之类的模型相似(SEDA全称是:stage event driver architecture,中文直译为“分阶段的事件驱动架构”,它旨在结合事件驱动和多线程模式两者的优点,从而做到易扩展,解耦合,高并发。各个stage之间的通信由event来传递,event的处理由stage的线程池异步处理。)。
对于数据流系统,要解决的主要问题之一就是可靠性。你想确保发送到某处的数据得到了有效接收。
NIFI通过多种机制在任何时间点跟踪系统状态,从而实现了高度的可靠性。这些机制是可配置的,因此你可以在延迟和应用程序所需的吞吐量之间进行适当的权衡。
NIFI利用lineage和provenance特征来跟踪每条数据的历史记录。它使得知道每条信息发生了什么转变。
Apache NIFI提出的数据血缘解决方案被证明是审核数据pipeline的出色工具。在诸如欧盟这样的跨国参与者提出支持准确数据处理的准则的背景下,数据血缘功能对于增强人们对大数据和AI系统的信心至关重要。
为什么要使用NIFI?
在确定解决方案时,请记住大数据的四个特点。

- Volume — 你有多少数据?在数量级上,你接近几GB还是几百个PB?
- Variety — 你有多少个数据源?你的数据是否结构化?如果是,结构是否经常变化?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









