







 本文深入探讨Apache NIFI的调度策略,包括Timer driven、CRON driven和Event driven。Timer driven是默认模式,处理器定时运行;Event driven由事件触发,目前实验性;CRON driven按预设时间调度。文章通过疑问解答形式,详细解析了不同策略的工作原理和配置细节,如时间间隔、调度检查等。
本文深入探讨Apache NIFI的调度策略,包括Timer driven、CRON driven和Event driven。Timer driven是默认模式,处理器定时运行;Event driven由事件触发,目前实验性;CRON driven按预设时间调度。文章通过疑问解答形式,详细解析了不同策略的工作原理和配置细节,如时间间隔、调度检查等。
简介:本文主要讲解Apache NIFI的调度策略,对象主要是针对Processor组件。本文假定读者已经对Apache NIFI有了一定的了解和使用经验,同时作者也尽可能的去讲解的更透彻,使得本文尽可能让对NIFI接触不深的读者也能够看懂。
NIFI的调度策略
打开任意一个Processsor,在其配置页面SCHEDULING页签我们可以配置它的调度策略,如下图所示:
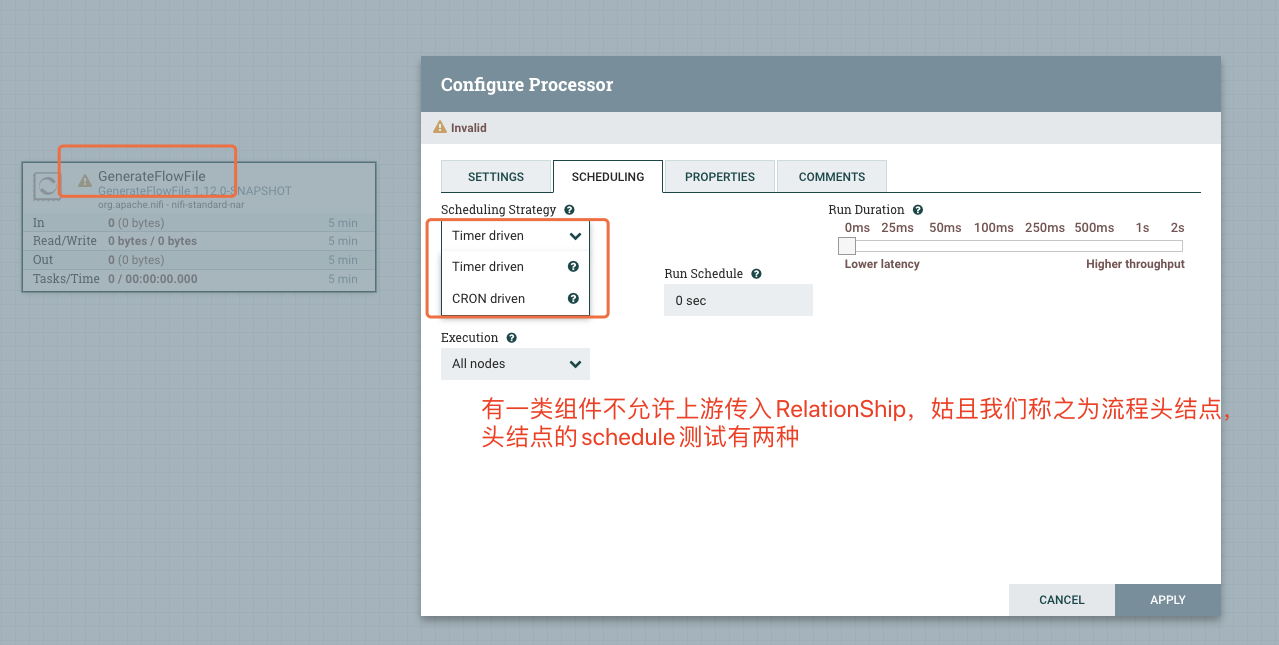
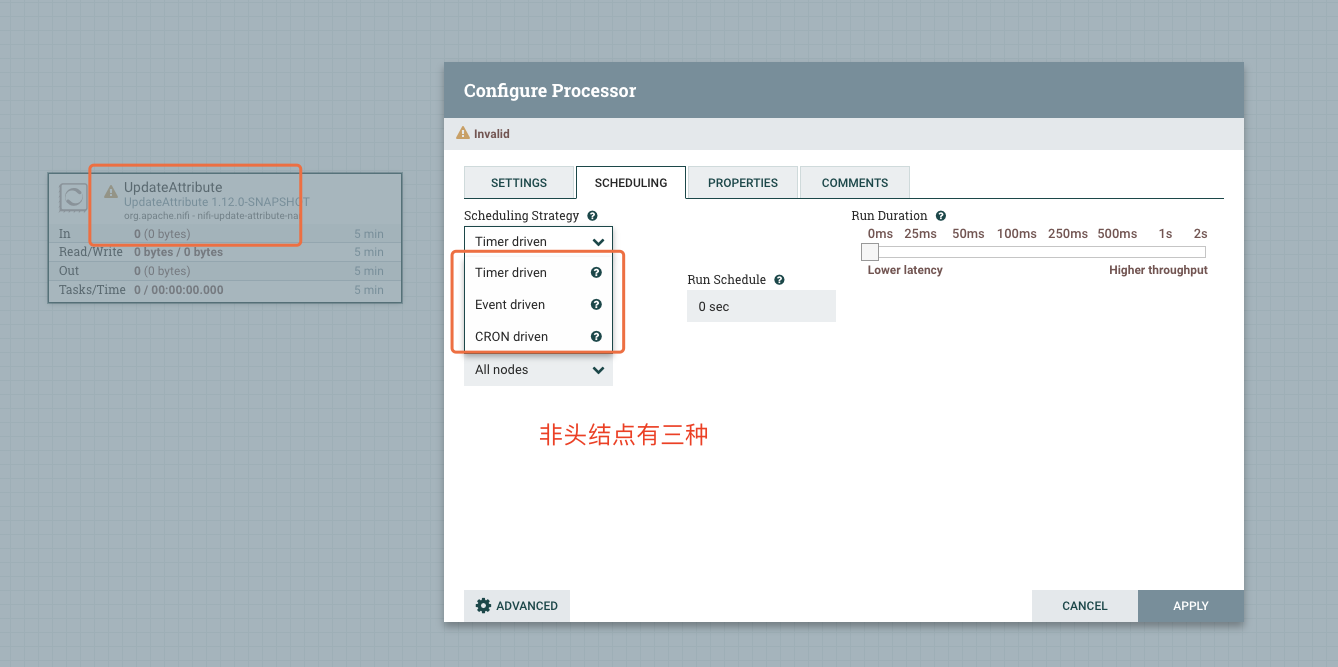
在流程中有一类的Processor的实例是不允许传入FlowFIle的,我们姑且可以称之为流程源结点(第一个节点)。这类Processor实例的调度策略只有两种,而其他的Processor实例的调度策略有三种。(注意,这里强调的是Processor实例,有些Processor在源组件位置时是两种调度策略,没有Event策略,而当这些Processor不处于源组件位置时,它会有三种调度策略)
-
Timer driven: 这是调度策略的默认模式。处理器会定期运行。处理器运行的时间间隔由
Run schedule选项定义。 -
Event driven: 如果选择此模式,则由event触发处理器运行,并且该event在FlowFiles进入到该处理器的上游Connection时发生。该模式当前被认为是实验性的,
并非所有处理器都支持(Processor类使用@EventDriven注解标注的组件是支持Event driven的)。选择此模式后,Run schedule选项不可配置,因为不会触发处理器定期运行,而是由event触发。此外,这是可以将Concurrent tasks选项设置为0的唯一模式。在这种情况下,线程数仅受Event-Driven Thread Pool的大小限制。 -
CRON driven: 当使用CRON驱动的调度模式时,处理器被调度为定期运行(比如每天凌晨调度运行),
类似于计时器驱动的调度模式,CRON驱动模式以增加配置复杂性为代价提供了更大的灵活性。 CRON驱动的调度值是由六个必填字段和一个可选字段组成的字符串,每个字段之间用空格分隔。
好了,以上就是本文全部内容。
全剧终。。。
好吧,上面所述都是理论知识,在官方文档里都能看到,下面我们进一步对这些调度策略进行探索总结。
Timer driven
Timer driven是我们最常用的调度策略了,简单易懂,10 sec就是每隔10秒调度一次。
可识别的后缀如下所示:
- 纳秒:“ns”, “nano”, “nanos”, “nanosecond”, “nanoseconds”
- 毫秒:“ms”, “milli”, “millis”, “millisecond”, “milliseconds”
- 秒:“s”, “sec”, “secs”, “second”, “seconds”
- 分钟:“m”, “min”, “mins”, “minute”, “minutes”
- 小时:“h”, “hr”, “hrs”, “hour”, “hours”
- 天:“d”, “day”, “days”
- 周:“w”, “wk”, “wks”, “week”, “weeks”
疑问1
那么第一个问题来了,比如说每隔10秒调度一次,是什么意思?是从0秒开始,10秒,20秒,30秒。。。这样的每次去执行调度嘛?还是每次任务结束后开始计时?
下面我们来实际求证一下。
新拉取一个ExecuteGroovyScript组件,选择Timer driven并设置2秒运行一次,然后在Script Body配置中添加Groovy代码
//创建一个流文件
flowFile = session.create()
//添加一个属性,在FlowFIle中记录一个时间,姑且把这个时间当做本次调度开始时间
flowFile = session.putAttribute(flowFile, 'Time', String.valueOf(System.currentTimeMillis()))
//然后休眠3秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//将FlowFIle传输到success
session.transfer(flowFile, REL_SUCCESS)
点击运行后生成了三个流文件
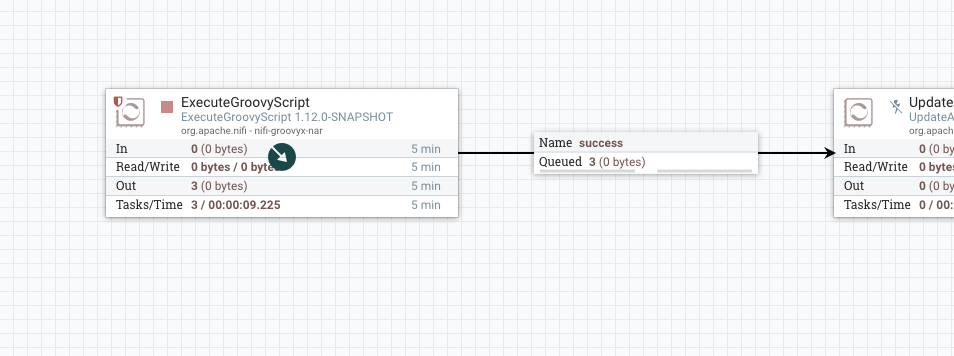
我们分别来看一下这3个流文件的Time属性
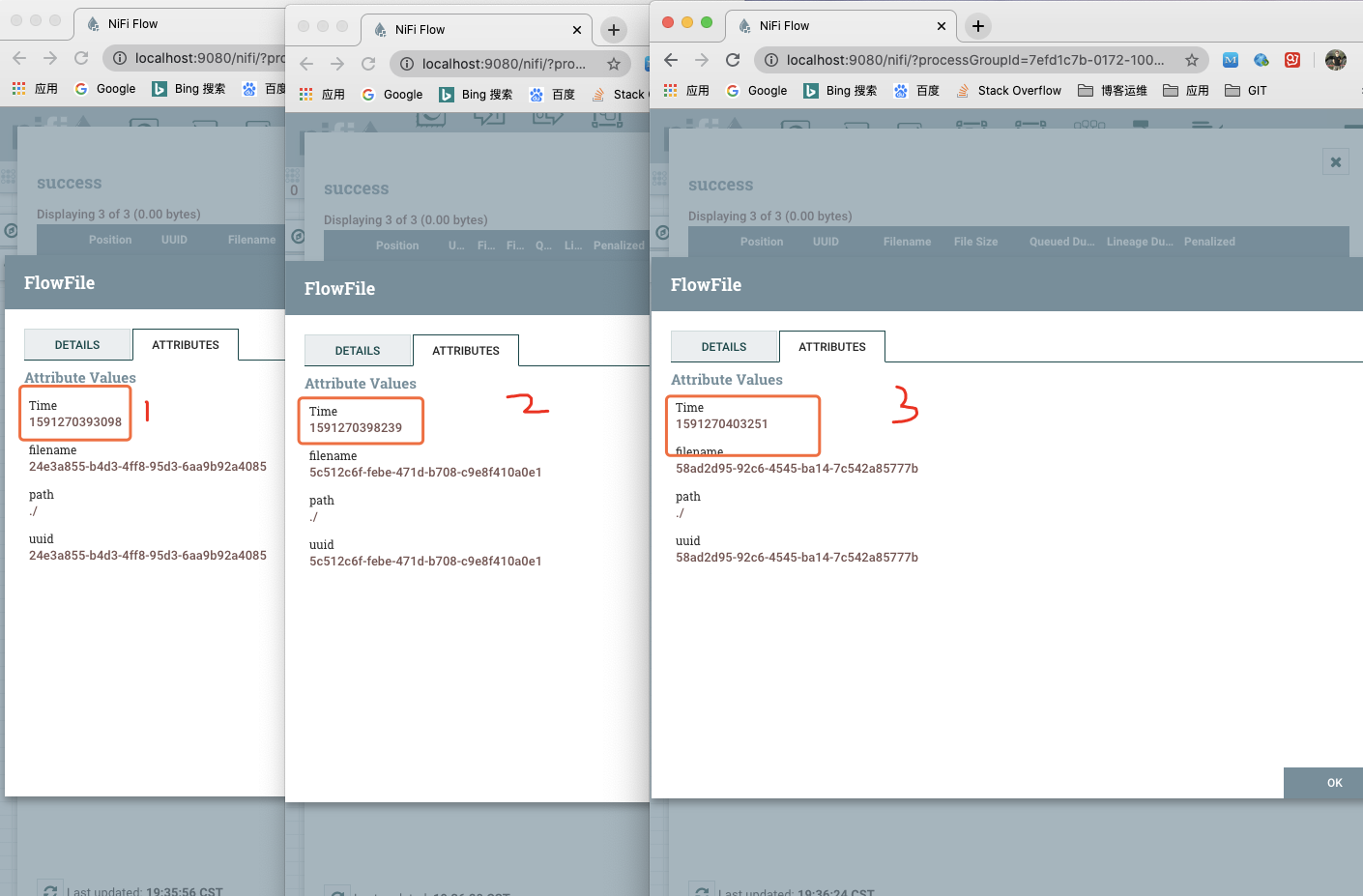
1591270393098
+5141 大约是5秒
1591270398239
+5012 大约是5秒
1591270403251
所以,结果显而易见了,这里是每次任务结束后开始计时(后面疑问5里会提到源码,源码里就是上一次任务结束后计时,时间一过,然后开始下次任务)。
疑问2
第二个问题 如果我们安排处理器每0秒运行一次(默认情况下),会发生什么?它会一直运行,消耗大量资源吗?
答案显然是不会的!(如果这点都做不好,还搞啥子Apache顶级项目嘛)
在NIFI安装目录conf下的nifi.properties中有如下配置,队列中没有数据的时候也就是Processor没有可处理的数据,那么我们在这里配置隔多久再去调度检查一次组件是否有可做的有工作。
# If a component has no work to do (is "bored"), how long should we wait before checking again for work?
nifi.bored.yield.duration=10 millis
假如我们使用的是默认配置,那么意思是说虽然我们配置了处理器每0秒运行一次,但当Processor没有工作要做时(可以简单理解为上游Connection是空的),它会等10 millis然后再调度一次检查组件是否有工作要做(在后面的疑问5里会有源码说明到这个10ms)。
疑问3
看到这里使用过Apache NIFI的人可能会有疑问了,怎么会这样,我们在运行流程的时候,比如下图UpdateAttribute设置的每0秒运行一次,它的上游Connection是空的,我们观察它并没有被调度啊?(组件方块右上角根本没有显示任何数字)
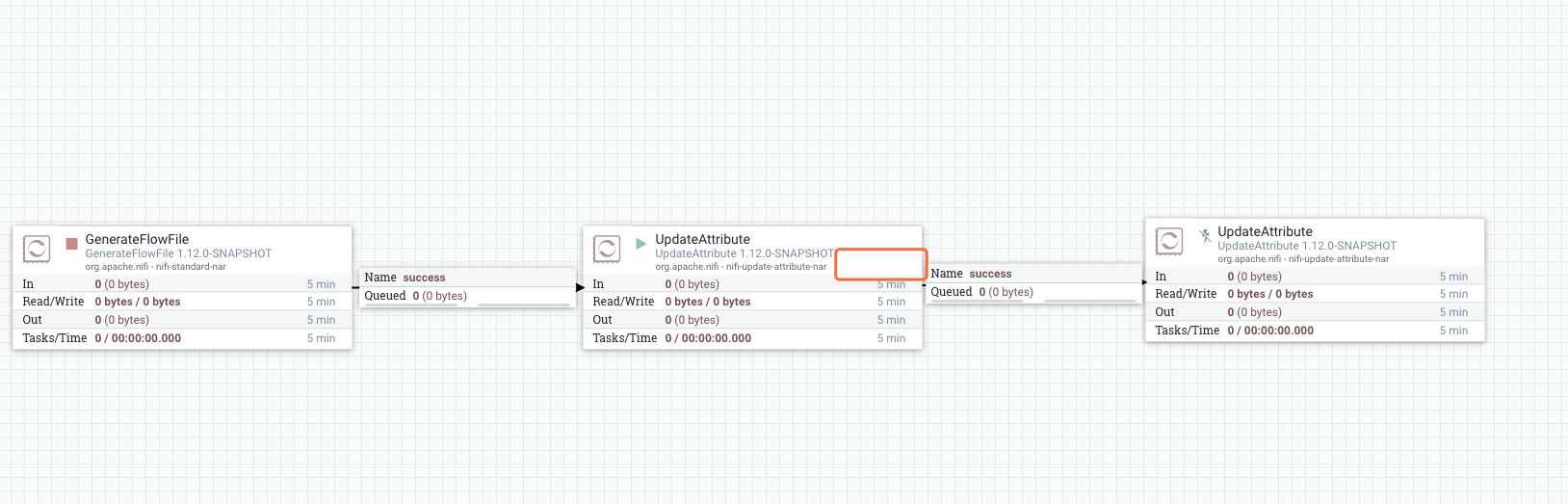
然后我们要明确一点,Processor右上角的那个数字的含义是Active Tasks

Active Tasks:该处理器当前正在执行的任务数(有几个任务在调用Processor的onTrigger方法)。此数字受Processor配置对话框的Scheduling选项卡中的Concurrent tasks设置约束。在这里,我们可以看到处理器当前正在执行一项任务。如果NiFi实例是集群的,则此值表示集群中所有节点上当前正在执行的任务数。
额外说一些,那么显示出来的这个Acrive Task是怎么来的呢?首先在Apache NIFI中有一个对象StandardProcessorNode(可以简单这么理解,我们对于一个组件的调度、并发等等配置以及对这个组件的监控、跟踪等等信息都是存储在这个对象里,每个Processor实例都会对应一个StandardProcessorNode实例),ProcessorNode是线程安全的。在StandardProcessorNode中有这么这么几段代码:
@Override
public void onTrigger(final ProcessContext context, final ProcessSessionFactory sessionFactory) {
//获取ProcessorNode所指向的Processor
final Processor processor = processorRef.get().getProcessor();
//Active Task +1
activateThread();
try (final NarCloseable narCloseable = NarCloseable.withComponentNarLoader(getExtensionManager(), processor.getClass(), processor.getIdentifier())) {
//这里调用的是Processor的onTrigger方法逻辑
processor.onTrigger(context, sessionFactory);
} finally {
//Active Task -1
deactivateThread();
}
}
而activateThread()方法
private final Map<Thread, ActiveTask> activeThreads = new HashMap<>(48);
private synchronized void activateThread() {
final Thread thread = Thread.currentThread();
final Long timestamp = System.currentTimeMillis();
activeThreads.put(thread, new ActiveTask(timestamp));
}
而在NIFI Web Api里,在生成一个Processor的状态信息时会调用public synchronized List<ActiveThreadInfo> getActiveThreads()方法,进而就能够获取到Acrive Task数值,这里就不展开源码说了,感兴趣的读者直接顺着上面说的方法查看调用就可以找到了。
那我们来手动证明一次,当Processor没有需要处理的数据时,不会触发Processor的onTrigger方法,我们复用上面的groovy组件,加一行打印日志的代码
// 打印警告日志
log.warn('我被调度了')
//创建一个流文件
flowFile = session.create()
//添加一个属性,在FlowFIle中记录一个时间,姑且把这个时间当做本次调度开始时间
flowFile = session.putAttribute(flowFile, 'Time', String.valueOf(System.currentTimeMillis()))
//然后休眠3秒
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//将FlowFIle传输到success
session.transfer(flowFile, REL_SUCCESS)
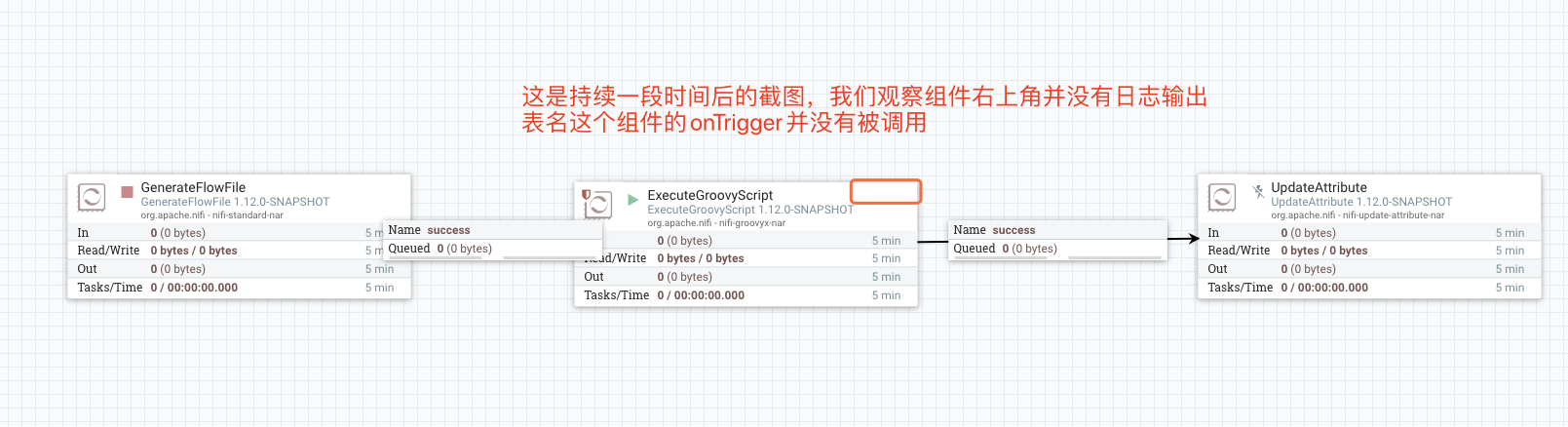
然后在ExecuteGroovyScript上游添加一个组件GenerateFlowFile用于生成流文件。这是持续一段时间后的截图,我们观察组件右上角并没有日志输出表明这个组件的onTrigger并没有被调用
作为对比,我们发送一个流文件,就能观察到日志输出:
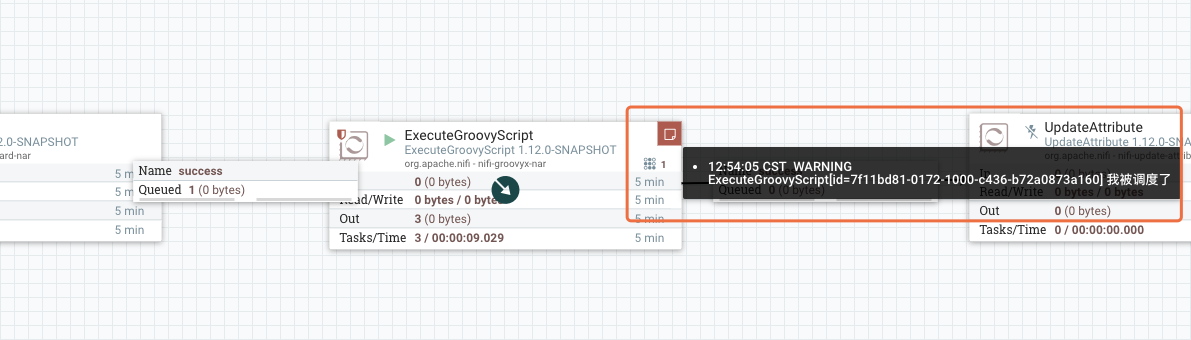
总结一下:我们配置了处理器每0秒运行一次,但当Processor没有工作要做时,它会等10 millis然后再检查一次是否有工作要做,是不会触发Processor运行任务的(不会调Processor的onTrigger方法)。
这里我们说的比较清楚,Processor没有工作要做导致了没有Active Task(不会触发Processor的onTrigger方法),而不是说没有线程运行或者没有调度发生。
疑问4
那么怎么判断Processor是否有工作要做?
首先我们看到,一个叫ConnectableTask的实例会去调用StandardProcessorNode的onTrigger方法,执行的地方叫invoke()
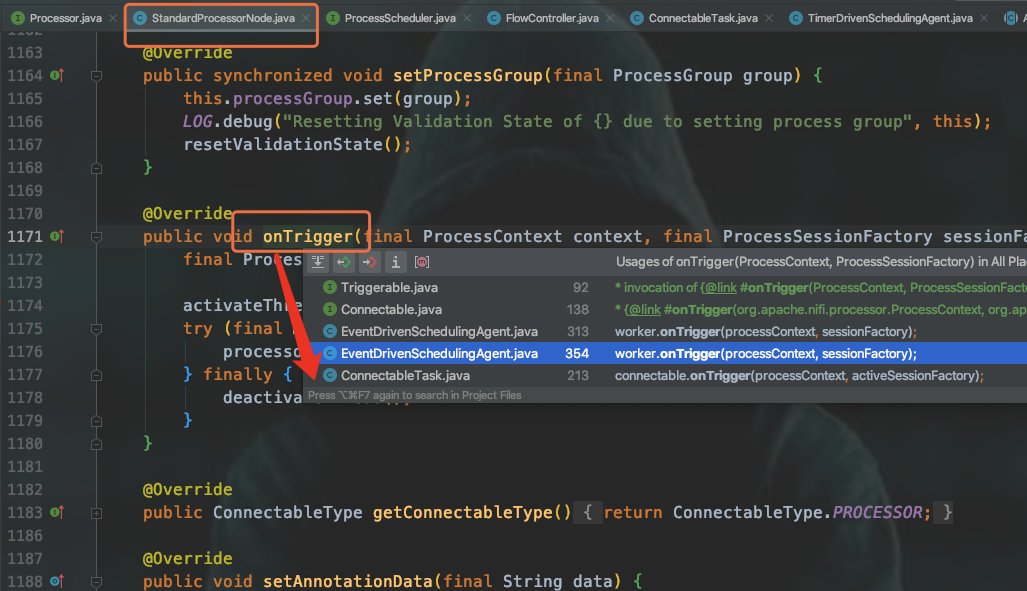
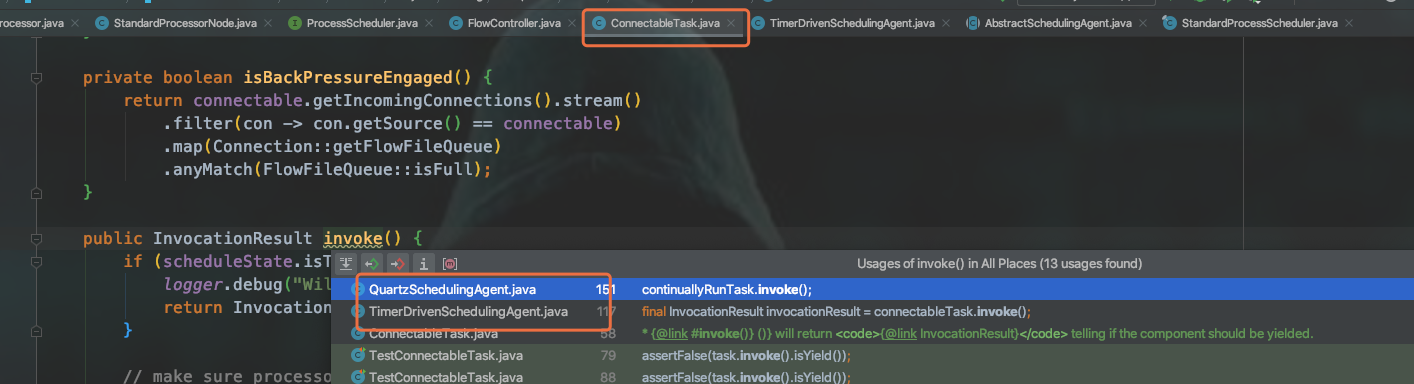
而调用ConnectableTask的invoke()方法的有两个agent:QuartzSchedulingAgent对应CRON driven TimerDrivenSchedulingAgent对应Timer driven。先不管agent,在invoke()方法会调用isWorkToDo()来判断这个组件实例是否有工作要做。
private boolean isWorkToDo() {
//Connectables意思是可以连接的组件,这里判断当前的connectable的所有上游的Connection是否都是来自于它自己
boolean hasNonLoopConnection = Connectables.hasNonLoopConnection(connectable) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6585
6585

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









