







简介:本压缩包文件“ACM_Code”包含了一系列实现代码,旨在帮助程序员理解和应用计算几何、特殊数据结构和组合数学等关键编程知识领域。计算几何涵盖了点、线、平面等几何对象的操作,特殊数据结构包括B树、红黑树等高效数据组织方式,而组合数学则涉及了离散数学的计数原理和最优化问题。这些代码为ACM编程竞赛和算法设计提供了实用工具,通过学习这些代码,开发者能够提高解决复杂问题的能力和编程效率。 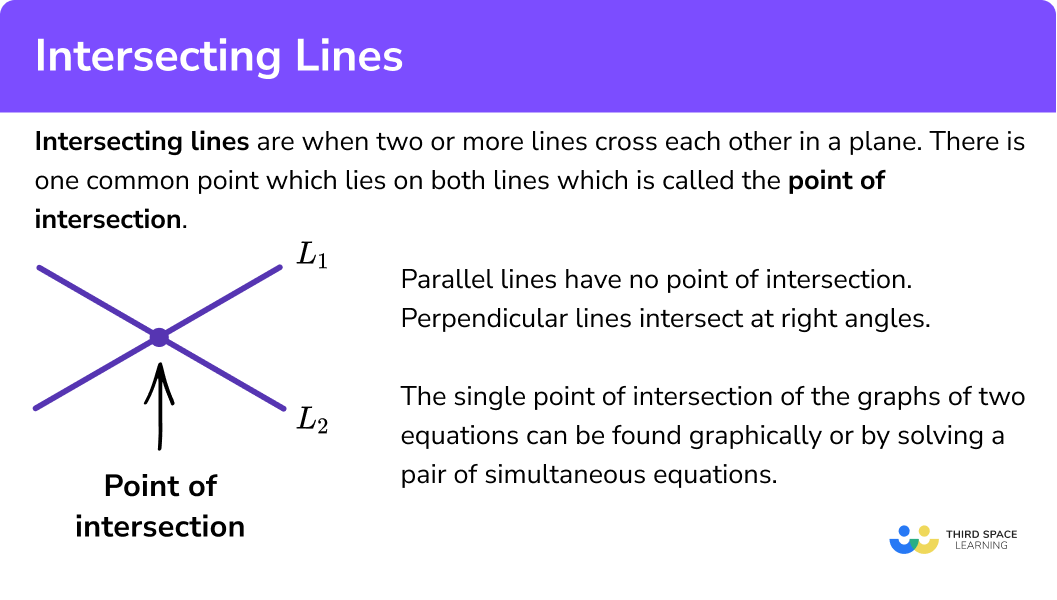
1. 计算几何基础与算法实现
计算几何是计算机科学中一个核心分支,它运用算法处理几何问题。本章将带你入门计算几何的基础知识,解析关键的几何算法,并说明它们在不同场景下的应用。我们会从基础概念开始,逐步深入至具体算法的实现与应用。
1.1 几何问题的计算机表示
在计算几何中,首先我们需要理解几何对象如何在计算机上表示。例如,线段、圆和多边形等形状,它们都可以用一系列数学公式和数据结构来描述。理解这些基础概念是解决几何问题的第一步。
# 示例:Python中表示二维点
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
def __repr__(self):
return f"Point({self.x}, {self.y})"
通过上述代码,我们可以创建一个简单的二维点类,并在需要时对这些点进行操作。这只是计算几何中的一个微小部分,但在实现更复杂算法之前,这是不可或缺的基础。
1.2 算法实现的步骤和注意事项
在实现计算几何算法时,步骤和注意事项必须被仔细考虑。这些算法往往涉及复杂的数学知识,因此正确理解问题和选择合适的数学工具是关键。算法的正确实现应确保高效性和精确性,避免因浮点数误差或几何结构的特殊性质导致的错误。
# 示例:计算两点之间的距离(欧几里得距离)
def distance(p1, p2):
return ((p1.x - p2.x) ** 2 + (p1.y - p2.y) ** 2) ** 0.5
上述代码展示了如何计算两个点之间的欧几里得距离,体现了计算几何中简洁的数学运算。通过本章的学习,读者将掌握更多类似的基础几何算法及其实现。
2. 特殊数据结构应用与优化
2.1 常见的高级数据结构
数据结构是计算机存储、组织数据的方式,它可以帮助我们以更高效的方式处理数据。在解决问题时,选用合适的数据结构可以显著提升算法的性能。本章将介绍几种常见的高级数据结构,以及它们在问题解决中的应用。
2.1.1 树状数组
树状数组(Binary Indexed Tree,BIT),又称为Fenwick树,是一种用于高效处理前缀和、区间和等问题的数据结构。它的核心思想是将一个线性序列通过特殊的方式组织成树形结构,以此来达到快速查询和更新的目的。
# 树状数组的初始化与更新操作
class FenwickTree:
def __init__(self, size):
self.size = size
self.tree = [0] * (size + 1)
def update(self, index, value):
while index <= self.size:
self.tree[index] += value
index += index & -index # 向上移动到下一个需要更新的索引
def query(self, index):
result = 0
while index > 0:
result += self.tree[index]
index -= index & -index # 向上移动到下一个需要查询的索引
return result
在上述代码中, update 函数负责在树状数组中更新给定索引的值,而 query 函数用于查询从数组开始到给定索引的累加和。 index & -index 的操作确保了每次更新或查询都是移动到下一个需要参与运算的索引位置。
树状数组适用于那些需要频繁更新单个元素,并且需要频繁计算前缀和或区间和的场景。例如,在处理一维区间求和问题时,树状数组可以在对数时间内完成更新和查询操作,相比于线性扫描,可以大大提高效率。
2.1.2 斐波那契堆
斐波那契堆(Fibonacci Heap)是一种可以提供一系列操作的堆数据结构,主要应用在图论和网络流算法中。斐波那契堆特别适合那些需要多次合并堆的场合,因为它的合并操作是常数时间,而其他堆结构如二叉堆的合并操作是线性时间。
斐波那契堆通过延迟执行实际的堆操作来达到合并堆的常数时间,这被称为懒惰求值。然而,这种优势并非没有代价,斐波那契堆的其他操作,例如增加节点、删除节点、寻找最小值等可能需要更长的时间。
# 斐波那契堆的相关操作较为复杂,这里仅提供一个简化的接口实现
class FibonacciHeapNode:
def __init__(self, key):
self.key = key
self.mark = False
self.parent = None
self.child = None
self.left = self
self.right = self
class FibonacciHeap:
def __init__(self):
self.min = None
def insert(self, key):
# 插入操作,创建新节点,链接到最小堆的根列表中,并更新最小节点
pass
def decrease_key(self, x, new_key):
# 减小节点键值操作,更新节点值,并进行链表重新链接
pass
def extract_min(self):
# 提取最小节点操作,将最小节点移除堆,并通过级联切割操作维持堆结构
pass
# 其他操作省略...
斐波那契堆的应用场景较少,且实现复杂度较高,因此在实际编程中使用较少。它的优势主要在于提供了最优的合并操作,使得一些图算法如Dijkstra算法在最坏情况下的时间复杂度大大降低。
2.1.3 后缀数组
后缀数组是用于处理字符串相关问题的一种数据结构,它将一个长字符串的所有后缀进行排序,并存储到数组中。后缀数组能够高效解决字符串匹配、重复子串查找等问题。
构建后缀数组的时间复杂度为O(n log n),可以通过倍增法、DC3算法等多种策略实现。在构建完成后,可以使用后缀数组解决各种字符串相关的复杂问题。
# 后缀数组的构建过程略过具体实现细节
# 假设我们有一个后缀数组的实现
suffix_array = build_suffix_array(string)
# 使用后缀数组解决实际问题
def find_longest_repeated_substring(s, sa):
# 使用后缀数组查找重复子串
pass
后缀数组对于字符串处理算法来说是一种非常强大的工具,尤其是在需要对字符串的子串或模式进行高效查询和分析的场合。
2.2 数据结构在问题解决中的作用
数据结构是算法的基础,它们在解决问题的过程中扮演着至关重要的角色。不同的数据结构适用于不同的场景,而合理的选择数据结构可以大大提高问题解决的效率。
2.2.1 理解不同数据结构的适用场景
在选择数据结构之前,必须先理解问题的具体需求。例如,如果需要频繁地查找元素,那么哈希表可能是最佳选择;如果需要维护元素的顺序,链表或数组可能更为合适;如果需要快速合并和分割数据集,那么树状结构如AVL树或红黑树可能是更好的选择。
在解决问题时,不仅需要考虑单一数据结构的适用性,还应当考虑组合使用多个数据结构,以达到最优化的效果。
2.2.2 空间和时间复杂度的权衡
在选择数据结构时,需要在空间复杂度和时间复杂度之间做出权衡。例如,链表提供了灵活的插入和删除操作,但在访问元素时效率较低;数组访问速度快,但插入和删除操作的开销较大。
有时,为了达到最优的时间复杂度,我们可能需要使用更多的空间,反之亦然。在实际问题解决中,需要根据问题的具体需求和资源限制,综合考虑如何平衡这两者的关系。
2.2.3 实例分析:数据结构在特定问题中的应用
以图的最短路径问题为例。如果使用邻接矩阵表示图,则可以方便地查询任意两点之间的路径,但空间复杂度较高;如果使用邻接表,则空间复杂度较低,但查询路径时效率不高。如果图是有向无环图(DAG),那么可以使用拓扑排序和动态规划的方法来高效解决问题。
在具体实现时,可以构建一个数据结构来记录每个节点的前驱节点,这样在找到最短路径之后,可以迅速回溯得到具体路径。
# 最短路径问题的实现,这里仅提供伪代码
def find_shortest_path(graph):
# 对图进行拓扑排序
sorted_nodes = topological_sort(graph)
# 动态规划计算每个节点的最短路径
shortest_paths = [float('inf')] * len(graph.nodes)
shortest_paths[sorted_nodes[0]] = 0
for node in sorted_nodes[1:]:
for prev_node, weight in graph[node].items():
if shortest_paths[prev_node] != float('inf'):
new_path = shortest_paths[prev_node] + weight
shortest_paths[node] = min(shortest_paths[node], new_path)
# 回溯得到最短路径
path = []
current = end_node # 假设end_node为终点
while current is not None:
path.insert(0, current)
for prev, weight in graph[current].items():
if shortest_paths[current] == shortest_paths[prev] + weight:
current = prev
break
return path
2.3 数据结构优化技术
数据结构的优化是提升算法性能的关键。优化可以从时间和空间两个维度入手,针对具体的数据结构进行调整和改进。
2.3.1 空间优化:内存管理与复用
对于数据结构的内存管理,我们可以采用对象池技术,避免频繁地创建和销毁对象,从而减少内存碎片和垃圾回收的开销。对于字符串等数据,使用引用计数和垃圾回收机制可以有效管理内存。
# 对象池技术的简化示例
class StringPool:
def __init__(self):
self.pool = {}
def get_string(self, value):
# 如果字符串已经存在于池中,则返回引用,否则创建新字符串并加入池中
pass
def release(self, value):
# 当字符串不再使用时,从池中移除
pass
string_pool = StringPool()
2.3.2 时间优化:快速查找和更新
快速查找和更新主要依赖于哈希表等数据结构,它们能够在平均情况下以常数时间完成查找和更新操作。在一些特定情况下,比如字符串匹配,可以使用后缀数组或后缀树来实现快速查找。
# 哈希表的快速查找和更新操作
hash_table = {}
def insert(key, value):
# 插入键值对到哈希表
pass
def get(key):
# 从哈希表中获取对应的值
pass
2.3.3 算法融合与优化策略
算法融合是指将两种或以上的算法结合使用,以达到互相补充的效果。例如,在搜索问题中,可以将深度优先搜索(DFS)和广度优先搜索(BFS)结合起来,利用DFS的剪枝能力和BFS的最优路径搜索能力。
优化策略的选择需要根据具体问题和应用场景来定。例如,对于大数据量处理,可以采用分治、并行计算等策略;对于实时性要求较高的场景,则可采用增量计算等策略。
# DFS与BFS融合的伪代码示例
def dfs_and_bfs(graph):
# 先用DFS找到一个可能的解,并进行剪枝
path = dfs(graph)
if not path:
return None
# 使用BFS找到最优解
return bfs(graph, path起点)
在实际编程中,融合算法时需要特别注意算法之间的兼容性和交互方式,确保在提高效率的同时不引入新的错误。
通过上述章节的介绍,我们了解了高级数据结构的概念、应用以及在问题解决中的优化策略。下一章,我们将探讨组合数学的基础理论及其在编程中的应用。
3. 组合数学概念及其在编程中的应用
组合数学作为数学的一个分支,它主要研究离散量的组合方式,包括组合数学的基本理论和组合数学在编程中的应用。这门科学在计算机科学和信息论中扮演了重要角色,尤其是在算法设计、数据分析、密码学等领域。
3.1 组合数学的基本理论
组合数学的一些基础概念,如排列、组合和二项式定理等,是解决数学问题和编写相关算法的基石。
3.1.1 排列与组合
排列与组合是组合数学中研究的基本问题,它们描述的是如何从给定的集合中选择元素或对元素进行排列的计数问题。
排列
排列是指从n个不同元素中取出m(m≤n)个元素的所有可能的不同排列的数目。排列的公式为:
[ P(n, m) = \frac{n!}{(n-m)!} ]
其中 n! 表示n的阶乘,即 n * (n-1) * (n-2) * ... * 1 。
组合
组合是指从n个不同元素中取出m(m≤n)个元素的所有可能的不同组合的数目,与元素的排列顺序无关。组合的公式为:
[ C(n, m) = \frac{P(n, m)}{m!} = \frac{n!}{m! \cdot (n-m)!} ]
代码示例 - 计算排列和组合的函数实现:
import math
def factorial(n):
"""计算n的阶乘"""
if n == 0:
return 1
else:
return n * factorial(n-1)
def permutation(n, m):
"""计算n个元素中取出m个的排列数"""
return factorial(n) // factorial(n - m)
def combination(n, m):
"""计算n个元素中取出m个的组合数"""
return permutation(n, m) // factorial(m)
# 示例计算
print(permutation(5, 3)) # 输出: 60
print(combination(5, 3)) # 输出: 10
在上述代码中, factorial 函数用于计算阶乘,而 permutation 和 combination 函数分别用于计算排列数和组合数。通过递归调用的方式计算阶乘,并通过除以不相关的阶乘来计算排列和组合数。
3.1.2 二项式定理与多项式展开
二项式定理是代数学中的一个基本定理,它描述了二项式的幂可以如何展开为一个多项式。二项式定理的一般形式是:
[ (a + b)^n = \sum_{k=0}^{n} {n \choose k} a^{n-k} b^k ]
其中 {n \choose k} 是组合数,表示从n个不同元素中取出k个元素的组合数。
代码示例 - 二项式定理的实现:
def binomial_coefficient(n, k):
"""计算组合数 nCk"""
if k > n - k: # 优化:由于组合数对称性,只计算一半
k = n - k
res = 1
for i in range(k):
res = res * (n - i) // (i + 1)
return res
def binomial_theorem(n, a, b):
"""计算(a + b)^n的二项式展开"""
res = []
for k in range(n+1):
res.append(binomial_coefficient(n, k) * (a**(n-k)) * (b**k))
return res
# 示例计算
print(binomial_coefficient(5, 2)) # 输出: 10
print(binomial_theorem(5, 2, 3)) # 输出: [96, 120, 60, 15, 1]
上述代码中 binomial_coefficient 函数用于计算组合数,而 binomial_theorem 函数则根据二项式定理进行多项式展开。需要注意的是,二项式展开结果中,索引 k 代表项的指数,并非是组合数 {n \choose k} 。
3.1.3 容斥原理及其应用
容斥原理是组合数学中解决包含-排除问题的重要原理。它提供了一种计算至少满足一个条件的元素数量的方法。
容斥原理的基本形式为:
[ |A_1 \cup A_2 \cup \dots \cup A_n| = \sum_{i} |A_i| - \sum_{i<j} |A_i \cap A_j| + \sum_{i<j<k} |A_i \cap A_j \cap A_k| - \dots + (-1)^{n+1} |A_1 \cap A_2 \cap \dots \cap A_n| ]
在编程中,容斥原理可以帮助我们解决重叠集合计数的问题。
代码示例 - 容斥原理的简单应用:
def intersection_size(A, B):
"""计算两个集合A和B的交集大小"""
return len(set(A) & set(B))
def union_size(A, B):
"""计算两个集合A和B的并集大小"""
return len(set(A) | set(B))
def principle_of_inclusion_exclusion(sets):
"""
容斥原理计算多个集合的并集大小。
sets: 一个包含多个集合的列表
"""
N = len(sets)
result = 0
for i in range(1, 1 << N):
subset = [sets[j] for j in range(N) if i & (1 << j)]
result += intersection_size(subset[0], subset[1])
for j in range(2, len(subset)):
result -= intersection_size(subset[0], subset[j])
return abs(result)
# 示例计算
A = [1, 2, 3]
B = [2, 3, 4]
C = [3, 4, 5]
print(principle_of_inclusion_exclusion([A, B, C])) # 输出: 5
在这个例子中, principle_of_inclusion_exclusion 函数实现了容斥原理,用于计算多个集合的并集大小。这里利用了位运算来生成所有可能的非空子集,并使用交集和并集的计算来获得最终结果。
容斥原理在编程中的应用非常广泛,如解决计数问题,特别是在元素有重叠时,该原理能够有效地帮助我们得到正确的计数结果。
3.2 组合数学在编程中的实现
组合数学在编程中有着广泛的应用,尤其是在解决实际问题时,如优化算法性能、简化代码逻辑等。
3.2.1 递归与动态规划解决组合问题
递归和动态规划是解决组合问题的常用算法技术。递归通过自调用简化问题,而动态规划则通过记录子问题的解来避免重复计算,以达到优化性能的目的。
递归
递归方法是解决组合问题的一种直观方法,它通过将问题规模缩小,从而简化问题。
代码示例 - 使用递归解决组合问题:
def recursive_combination(n, k):
"""
使用递归方法计算组合数C(n, k)
n: 总元素数
k: 选择元素数
"""
if k == 0 or n == k:
return 1
else:
return recursive_combination(n-1, k-1) + recursive_combination(n-1, k)
print(recursive_combination(5, 3)) # 输出: 10
在这个递归函数中,我们没有直接计算组合数的公式,而是使用了递归的方式来简化问题。
动态规划
动态规划避免了递归中的重复计算,提高了算法效率。
代码示例 - 使用动态规划解决组合问题:
def dynamic_programming_combination(n, k):
"""
使用动态规划方法计算组合数C(n, k)
n: 总元素数
k: 选择元素数
"""
comb = [[0 for _ in range(k+1)] for _ in range(n+1)]
for i in range(n+1):
comb[i][0] = 1
for i in range(1, n+1):
for j in range(1, min(i, k)+1):
comb[i][j] = comb[i-1][j] + comb[i-1][j-1]
return comb[n][k]
print(dynamic_programming_combination(5, 3)) # 输出: 10
在这个动态规划实现中,我们使用了一个二维数组来存储中间结果,避免了重复计算,并最终得到了组合数。
3.2.2 实例分析:编程中的组合问题
在编程中,组合问题广泛存在。例如,在游戏中需要计算出所有可能的移动组合,在软件测试中需要对所有可能的输入组合进行测试。
3.2.3 组合数学与其他算法的交叉应用
组合数学与其他算法,如图论、概率论等,可以交叉应用,解决更复杂的问题。
3.3 组合数学在算法竞赛中的应用
在算法竞赛中,组合数学是经常考察的知识点,常用于解决实际问题。
3.3.1 竞赛题目中的组合数学问题分析
组合数学问题在算法竞赛中经常以各种形式出现,如概率问题、排列组合问题等。
3.3.2 组合数学解题技巧
了解和掌握一些组合数学的基本解题技巧对于解决竞赛中的相关问题非常有帮助。
3.3.3 组合数学与概率统计的结合
组合数学与概率统计的结合可以解决很多复杂的问题,如赌博问题、统计问题等。
结语
组合数学作为计算机科学和算法竞赛中的重要工具,其原理和应用不仅对于理论研究有着重大意义,而且在实际编程和问题解决中有着广泛的应用。掌握组合数学的基础知识以及其在编程中的实现技巧,对于提升编程和算法能力具有重要的价值。
4. 算法竞赛与项目中的代码实践
在IT领域,算法竞赛不仅是一种智力的角逐,也是技术能力展示的舞台。本章节将深入探讨算法竞赛的准备策略、解题过程和在实际项目中算法的应用实例。我们将从准备和策略开始,逐步深入到解题思路与代码实现,最后通过项目案例分析来展示算法在解决实际问题中的作用。
4.1 算法竞赛的准备和策略
在参加算法竞赛之前,制定一个合理的准备和策略至关重要。这不仅涉及对算法和数据结构的深入理解,还包括高效的训练方法。
4.1.1 算法竞赛的分类和规则
算法竞赛按照参与对象可以分为国际级、国家级和校园级等不同层次。它们有不同的组织机构和竞赛规则。例如,ACM-ICPC(国际大学生程序设计竞赛)强调团队合作,而Codeforces或LeetCode竞赛则更注重个人能力。了解并熟悉所参加竞赛的规则是成功的先决条件。
4.1.2 常用算法和数据结构的掌握
掌握常用的算法和数据结构是算法竞赛的核心。例如,排序算法、搜索算法、动态规划、图论、数论等都是竞赛中的常客。此外,对于特定算法的应用场景和优缺点有深刻理解,能够灵活应用和变通,也是提升解题速度的关键。
4.1.3 高效学习和刷题的方法
在准备算法竞赛过程中,高效的刷题方法是提高解题能力的重要手段。建立自己的刷题计划,针对性地选择题目类型进行训练。同时,总结经验,复盘每一道题目,无论是解对的还是解错的,都要确保从每道题中获得知识和启示。
4.2 竞赛题目的解题思路与实现
在面对具体的算法竞赛题目时,如何快速准确地找到解题思路,并高效实现是关键。
4.2.1 题目分析与算法选择
首先需要对题目进行详细分析,明确问题的实际需求和限制条件。通过分析问题特点,选择适合的算法和数据结构。例如,对于需要快速查找的问题,优先考虑二分查找、哈希表等数据结构;而对于求解最优解问题,动态规划和贪心算法可能是更好的选择。
4.2.2 代码实现与调试
确定算法和数据结构后,接下来是编写代码的过程。在这个阶段,要注重代码的可读性和可维护性。同时,编写测试用例进行调试也非常重要,确保代码能够正确处理边界情况。
# 示例:使用 Python 实现二分查找算法
def binary_search(arr, x):
low = 0
high = len(arr) - 1
mid = 0
while low <= high:
mid = (high + low) // 2
if arr[mid] < x:
low = mid + 1
elif arr[mid] > x:
high = mid - 1
else:
return mid
return -1
# 参数说明:
# arr: 待搜索的有序数组
# x: 要查找的元素值
# 代码逻辑:
# 通过不断二分,逐渐缩小搜索区间,最终确定元素位置或者确定不存在。
4.2.3 时间和空间复杂度的优化
在竞赛中,时间复杂度和空间复杂度的优化是提升解题效率的关键。在算法实现后,需要对代码进行优化,比如减少不必要的计算、使用位运算替代算术运算、避免重复计算等。此外,数据结构的选择也直接影响到空间复杂度。
4.3 项目中的算法应用实例
在实际项目中,算法的应用是解决问题、提升效率的核心手段。下面将通过实例分析算法在项目中的应用。
4.3.1 实际项目中的算法需求分析
在项目开发过程中,需求分析是算法应用的前提。例如,在搜索引擎项目中,算法需求可能包括文本处理、排序、索引构建等。针对不同的需求,选择合适的算法实现是至关重要的。
4.3.2 算法在项目中的集成与优化
算法在项目中的集成和优化是提升项目性能的关键。在集成算法时,需要考虑与现有系统的兼容性,以及算法的效率和扩展性。对于性能瓶颈,需要进行针对性的算法优化。
4.3.3 项目案例分析:算法在解决实际问题中的作用
以搜索引擎为例,通过运用数据挖掘、机器学习、自然语言处理等算法,搜索引擎能够准确快速地返回相关搜索结果。在广告投放系统中,推荐算法能够根据用户的行为和偏好,高效地推荐相应的广告,提升用户体验和广告点击率。
graph TD
A[用户发起搜索请求] --> B[分词与预处理]
B --> C[查询索引]
C --> D[算法筛选与排序]
D --> E[返回搜索结果]
以上流程图展示了搜索引擎中算法的应用过程。首先,对用户的查询请求进行分词和预处理,然后查询索引数据库,接下来通过相关性排序算法对结果进行排序,最后返回给用户最相关的搜索结果。
通过上述实例分析,我们了解到算法在实际项目中所起到的至关重要的作用。无论是在提高性能、优化用户体验,还是在提升数据处理效率方面,算法都扮演着不可或缺的角色。
5. 代码库对提升算法能力的作用
5.1 算法代码库的重要性
5.1.1 代码库的定义和作用
代码库是软件开发中的一种资源,它包含了可以被重用的代码集合。在算法学习和应用中,代码库的作用尤为重要。它不仅能够提供现成的解决方案,缩短开发周期,还能够作为学习的工具,供开发者了解如何实现特定的算法,并在必要时进行定制或优化。算法代码库通常包含一系列针对特定问题或任务的高效算法实现,这些实现经过了反复测试和优化,能够为开发者提供可靠的支持。
5.1.2 算法代码库在学习和工作中的重要性
在学习阶段,算法代码库能帮助开发者快速理解算法的工作原理和实现细节。通过分析优秀的代码实现,新手可以逐步提升自己对算法的理解,并逐渐培养出良好的编程习惯。在工作中,算法代码库可以提供有效的技术支持,减少从零开始编写代码的时间,使开发者能够专注于解决更复杂的问题。此外,算法代码库中的算法通常都经过了优化,可以在性能要求较高的应用场景中发挥作用,提高产品的竞争力。
5.2 常用的算法代码库介绍
5.2.1 LeetCode、Codeforces等在线评测平台
LeetCode 和 Codeforces 是算法竞赛和编程学习中最受欢迎的在线评测平台之一。它们提供了大量的题目和测试用例,覆盖了从基础算法到复杂系统设计的各种问题。LeetCode 的题库分为多个难度级别,并提供了丰富的分类,如数组、字符串、动态规划等。Codeforces 除了提供题库外,还有定期举行的在线竞赛,对于提升算法能力和实战经验大有帮助。这些平台上的问题多数有官方或社区提供的优秀解决方案,是学习和提升算法能力的宝贵资源。
5.2.2 GitHub上的开源算法项目
GitHub 是一个面向开源及私有软件项目的托管平台,上面拥有大量的开源算法项目。这些项目通常由社区成员维护,更新频繁,并且涵盖了从基础数据结构到复杂算法实现的各个层次。开源项目的好处在于它们通常具有很好的注释和文档,使得理解代码逻辑变得更加容易。例如,一些著名的算法库如 "TheAlgorithms" 就提供了多种编程语言的算法实现,为学习者提供了学习和实验的平台。
5.2.3 企业内部的算法资源库
除了公共的在线资源和开源项目,许多企业内部也会维护自己的算法资源库。这些资源库通常包含为了解决特定业务问题而定制的算法,或者是对企业产品有关键作用的算法实现。企业算法资源库的价值在于它们紧密地结合了实际应用场景,为员工提供了与业务结合紧密的算法学习材料。此外,内部算法库也经常是企业培训的重要组成部分,有助于统一团队算法知识水平,提升团队解决问题的能力。
5.3 利用代码库提升算法能力的方法
5.3.1 分析和学习优秀代码库的代码
提升算法能力的一个重要途径就是对优秀代码库中的代码进行深入分析和学习。这包括理解算法的逻辑流程、代码结构以及数据结构的选择等。对于复杂的算法实现,我们可以从整体框架开始,逐步深入到具体的函数或方法中,直到可以清晰地了解每一行代码的含义和作用。为了更好地吸收知识,建议通过编写注释、绘制流程图或制作学习笔记的方式来辅助理解。
5.3.2 模仿和重构代码库中的算法实现
模仿是学习的一种重要手段。我们可以尝试模仿代码库中的算法实现,然后在此基础上进行适当的改进或重构。通过这种方式,我们可以逐渐培养出自己解决问题的方法和编程风格。同时,重构代码也是一个提升代码质量的过程,它有助于我们更加深入地理解算法的内部机制以及代码的可读性和可维护性。
5.3.3 代码库在解决实际问题中的应用技巧
在实际项目中应用算法代码库时,我们需要注意如何根据具体问题选择合适的算法,并将其有效地集成到项目中。这一过程中,需要考虑算法的时间和空间效率,以及与现有代码的兼容性。此外,还应该注意不断对使用的算法进行评估和调整,确保它们在实际应用中能够达到预期的效果。为了更好地应用算法代码库,我们可以建立一个索引机制,便于快速检索和匹配适合的算法实现。
6. 高级数据结构在实际问题中的应用
6.1 树状数组的深入应用
树状数组(Binary Indexed Tree,BIT),也称作Fenwick树,是一种可以高效处理动态频繁区间查询和修改的数据结构。尽管其结构复杂度较高,但在处理区间求和等需要频繁修改的场景中,树状数组相比普通数组有显著的优势。
6.1.1 树状数组基本原理与实现
树状数组的核心思想在于将数据存储在一个数组中,但其索引具有特定的规律,允许我们用很低的复杂度来更新元素和计算前缀和。
# 树状数组实现
class FenwickTree:
def __init__(self, n):
self.sums = [0] * (n + 1)
def update(self, i, delta):
while i < len(self.sums):
self.sums[i] += delta
i += i & -i
def query(self, i):
result = 0
while i > 0:
result += self.sums[i]
i -= i & -i
return result
# 使用示例
tree = FenwickTree(10)
tree.update(3, 5) # 增加索引3的值5
print(tree.query(3)) # 查询索引3的前缀和
6.1.2 树状数组在动态数据处理中的优势
树状数组在处理如区间求和、最大/最小值查询、动态求逆元等动态数据问题中有着独特的优势。以区间求和为例,如果在一个数据序列上频繁进行修改和查询操作,树状数组可以实现接近O(1)的查询复杂度。
6.2 斐波那契堆的高级应用
斐波那契堆(Fibonacci Heap)是一种优先队列数据结构,它是堆结构的一种,与二叉堆不同,它具有更好的理论时间复杂度。斐波那契堆主要用于实现如Dijkstra算法和Prim算法等图论算法中。
6.2.1 斐波那契堆的结构和操作
斐波那契堆由多个堆有序树构成,这些堆有序树通过兄弟和子节点指针连接。斐波那契堆的操作主要包括:合并、插入、最小值查找、删除最小值和减少键值。
# 斐波那契堆实现中关键的节点结构
class FibonacciHeapNode:
def __init__(self, key):
self.key = key
self.mark = False
self.degree = 0
self.parent = None
self.child = None
self.left = self
self.right = self
class FibonacciHeap:
def __init__(self):
self.min = None
# 其他斐波那契堆操作方法实现
6.2.2 斐波那契堆在算法中的应用实例
斐波那契堆在算法中的一个典型应用是在单源最短路径算法Dijkstra中。使用斐波那契堆可以将Dijkstra算法的时间复杂度降低到接近O(E + V logV)。
6.3 后缀数组及其在字符串处理中的作用
后缀数组(Suffix Array)是处理字符串问题的高级数据结构之一,它通过排序字符串的后缀并将它们存储在数组中的方式,简化了大量字符串操作。
6.3.1 后缀数组的基本原理
后缀数组实质上是对字符串所有后缀的有序排列。通过后缀数组,可以快速解决许多字符串问题,如最长公共前缀、最长重复子串等问题。
# 后缀数组的构建示例
def build_suffix_array(s):
n = len(s)
suffixes = [(s[i:], i) for i in range(n)]
suffixes.sort()
return [suff[1] for suff in suffixes]
# 使用后缀数组解决一些字符串问题
suffix_array = build_suffix_array('banana')
print(suffix_array)
6.3.2 后缀数组在实际问题中的应用
在实际问题中,后缀数组广泛应用于生物信息学中基因序列的分析,以及在压缩、查找和文本编辑等领域中的字符串搜索和匹配问题。
6.4 高级数据结构在问题解决中的作用总结
高级数据结构如树状数组、斐波那契堆和后缀数组是解决复杂问题时不可或缺的工具。它们分别在处理动态区间查询、优化优先队列操作、以及高效处理字符串问题方面展现了强大的能力。熟练掌握并应用这些数据结构可以帮助我们更有效地分析和解决各种算法和编程问题。
在下一章节中,我们将继续探讨高级数据结构在实际问题中的应用,并分析如何结合实际案例进行更深入的优化和实践。
简介:本压缩包文件“ACM_Code”包含了一系列实现代码,旨在帮助程序员理解和应用计算几何、特殊数据结构和组合数学等关键编程知识领域。计算几何涵盖了点、线、平面等几何对象的操作,特殊数据结构包括B树、红黑树等高效数据组织方式,而组合数学则涉及了离散数学的计数原理和最优化问题。这些代码为ACM编程竞赛和算法设计提供了实用工具,通过学习这些代码,开发者能够提高解决复杂问题的能力和编程效率。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









