






LLM 基础知识
1. 机器学习之数学基石
在踏足机器学习的殿堂之前,深入理解其背后的数学原理至关重要。
-
线性代数:它如同桥梁,连接着算法与数据世界。向量、矩阵、行列式、特征值与特征向量、向量空间及线性变换等概念,均为深度学习中的算法提供坚实的支撑。
-
微积分:在连续函数的优化旅程中,导数、积分、极限与级数如同灯塔,指引我们前行。同时,多变量微积分与梯度的概念亦不可忽视。
-
概率与统计:它们让模型从数据中汲取智慧,预见未来。概率论、随机变量、概率分布、期望、方差、协方差、相关性、假设检验、置信区间、最大似然估计及贝叶斯推理,这些概念如同星辰,点亮了我们的预测之路。
📚 资源推荐:
-
3Blue1Brown - 线性代数的本质:几何视角下,线性代数的真谛尽收眼底。
-
StatQuest 与 Josh Starmer - 统计基础知识:简单明了,统计学的奥秘触手可及。
-
Aerin 女士的 AP 统计直觉:深入浅出,概率分布背后的逻辑跃然纸上。
-
沉浸式线性代数:视觉盛宴,线性代数的另一种解读方式。
-
Khan Academy - 线性代数:直观易懂,初学者的首选。
-
可汗学院 - 微积分:深入浅出,微积分的基础知识一网打尽。
-
可汗学院 - 概率与统计:清晰易懂,概率与统计的知识轻松掌握。
2. Python:机器学习的得力助手
Python,这门强大而灵活的编程语言,因其在数据科学领域的卓越表现,成为机器学习的得力助手。
-
Python基础:从基本语法、数据类型、错误处理到面向对象编程,每一步都是通往数据科学殿堂的必经之路。
-
数据科学库:NumPy助你一臂之力,实现高效的数值运算;Pandas让你轻松驾驭数据的海洋;Matplotlib与Seaborn则为你绘制出数据的美丽图景。
-
数据预处理:特征缩放、标准化、缺失数据处理、异常值检测、分类数据编码以及数据集的拆分,每一步都为模型的训练与测试打下坚实基础。
-
机器学习库:Scikit-learn是你手中的利剑,监督学习、非监督学习,多种算法任你挑选。从线性回归、逻辑回归、决策树、随机森林到K最近邻、K均值聚类,每一个算法都蕴含着数据背后的智慧。降维技术如PCA和t-SNE则助你一臂之力,将高维数据可视化,洞察其本质。
📚 资源推荐:
- Real Python:Python学习的宝藏之地,从基础到进阶,应有尽有。
1. 深度学习启程 - Python语言
踏入freeCodeCamp - 学习 Python的长廊,一部详尽的视频将引领您逐步揭开Python核心概念的神秘面纱。而Python 数据科学手册,则如同一本珍贵的数字宝典,让您轻松掌握pandas、NumPy、Matplotlib和Seaborn的奥秘。
2. 机器学习之旅
对于机器学习的初学者,freeCodeCamp - 适合所有人的机器学习为您打开了一扇窗,让您一窥不同机器学习算法的风采。而Udacity - 机器学习简介则是一门免费的课程,深入浅出地为您解析PCA等关键概念。
3. 神经网络的深邃世界
神经网络,作为众多机器学习模型的核心,尤其在深度学习中扮演着重要的角色。为了驾驭这一利器,我们需全面了解其设计与运作机制。
-
基础知识:洞悉神经网络的结构,包括层、权重、偏差以及激活函数(sigmoid、tanh、ReLU等)。
-
训练与优化:熟悉反向传播和各类损失函数,如均方误差(MSE)和交叉熵,掌握梯度下降、随机梯度下降、RMSprop和Adam等优化算法。
-
抵御过度拟合:了解过度拟合的实质,学会应用dropout、L1/L2正则化、提前停止和数据增强等技术,为模型筑起坚固的防线。
-
实战多层感知器(MLP):运用PyTorch构建MLP,也称全连接网络,让您亲手体验神经网络的力量。
📚 资源宝库:
-
3Blue1Brown - 但什么是神经网络?:这部视频为您直观呈现神经网络的内部工作原理,让您一目了然。
-
freeCodeCamp - 深度学习速成课程:快速概览深度学习的核心概念,让您在知识的海洋中畅游。
-
Fast.ai - 实用深度学习:专为具备编程基础的深度学习爱好者打造,让您轻松入门。
-
Patrick Loeber - PyTorch 教程:系列视频助您轻松掌握PyTorch的奥秘,开启深度学习之旅。
4. 自然语言处理的魔法
自然语言处理(NLP),人工智能的璀璨分支,它致力于弥合人类语言与机器理解之间的鸿沟。从简单的文本处理到深入的语言细微差别理解,NLP在翻译、情感分析、聊天机器人等领域展现出巨大的潜力。
-
文本预处理:掌握分词、词干提取、词形还原、停用词删除等关键技术,为NLP应用打下坚实基础。
-
特征提取技术:熟悉词袋(BoW)、词频-逆文档频率(TF-IDF)和n-gram等方法,将文本数据转化为机器学习算法可识别的格式。## 词嵌入的艺术
词嵌入,作为一种独特的词表示形式,赋予了具有相近内涵的词汇相似的形态,使它们在语义空间中彼此亲近。在众多杰出方法中,Word2Vec、GloVe 和 FastText 无疑是其中的佼佼者。
递归神经网络的魅力
递归神经网络(RNN)不仅揭示了其独特的工作原理,更展现了它处理序列数据的卓越能力。在LSTM和GRU这两种RNN的杰出变体中,我们看到了模型学习长期依赖关系的强大能力。
📚 精选资源推荐
-
RealPython - NLP与spaCy在Python中的探索:spaCy库在Python中NLP任务的详尽指南,助您轻松驾驭自然语言处理。
-
Kaggle - NLP学习指南:用Python实践NLP的宝贵笔记本和资源库。
-
Jay Alammar - Word2Vec图解:深入了解Word2Vec架构的绝佳参考。
-
Jake Tae - 从零开始的PyTorch RNN:PyTorch中RNN、LSTM和GRU模型的实用与简洁实现。
-
colah的博客 - LSTM网络的理解:关于LSTM网络的深度理论剖析。
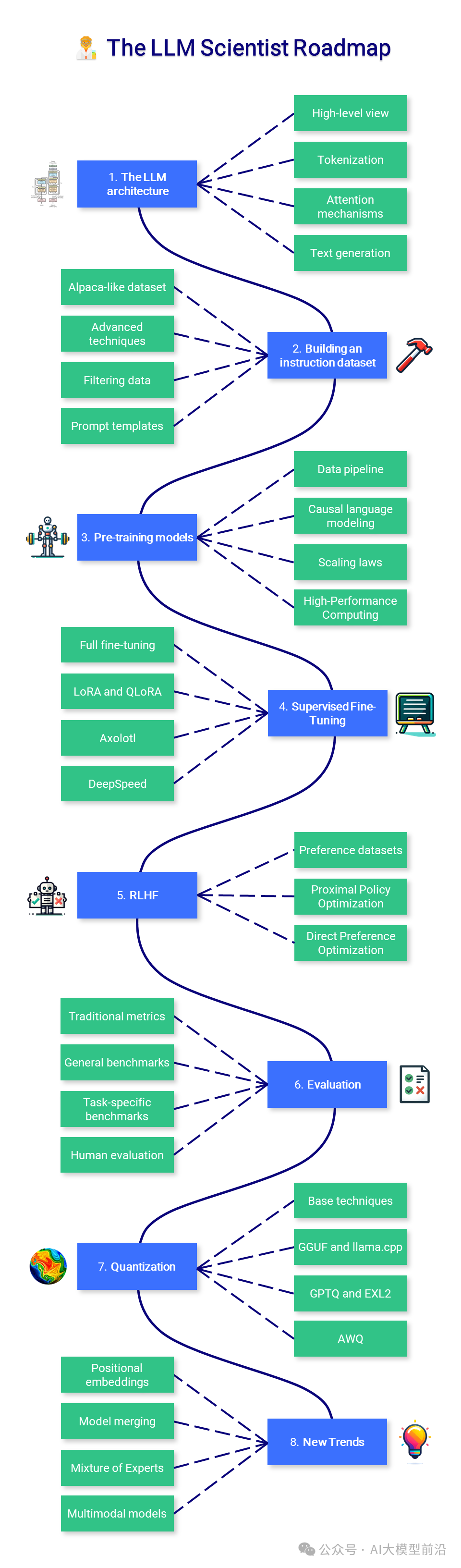
LLM科学家之旅
1. 深入LLM架构
尽管Transformer架构的细节不必一一掌握,但了解其输入(令牌)和输出(logits)却至关重要。普通的注意力机制作为其核心组件,更是我们学习的关键,其改进版本也将随后揭晓。
-
高级视角:让我们重新审视编码器-解码器Transformer架构,特别是GPT架构,这一仅含解码器的架构已在现代LLM中广泛应用。
-
标记化:将原始文本数据转化为模型能理解的格式,是了解如何将文本拆分为标记(通常是单词或子词)的关键。
-
注意力机制:深入探索注意力机制背后的理论,如自注意力和缩放点积注意力,它们使模型在生成输出时能够聚焦于输入的不同部分。
-
文本生成:探索模型生成输出序列的多种策略,包括贪婪解码、波束搜索、top-k采样和核采样等。
📚 参考资料
-
Jay Alammar的Transformer图解:直观理解Transformer模型的绝佳资源。
-
Jay Alammar的GPT-2图解:专注于GPT架构,与Llama有着异曲同工之妙。
-
Brendan Bycroft的LLM可视化:以惊人的3D可视化方式,展示LLM内部的运作奥秘。这个链接可能存在安全风险,为了保护您的设备和数据安全,请避免访问此链接。这个链接可能存在安全风险,为了保护您的设备和数据安全,请避免访问此链接。### 怀旧学者揭秘Chinchilla的深邃寓意
-
怀旧学者对Chinchilla的疯狂暗示:深入剖析缩放定律,并探讨它们对LLM(大型语言模型)领域的普遍影响。
探索BigScience的BLOOM奥秘
- BigScience的BLOOM:这里是一份详尽的概念页面,详细描述了BLOOM模型的构建过程,包括工程细节与所遇挑战,为您提供丰富的技术洞察。
Meta的OPT-175:从日志中窥见智慧
- Meta的OPT-175日志:这份研究日志详细记录了模型开发中的问题和解决方案。对于有志于预训练大型语言模型(如本例中的175B参数模型)的研究者而言,它是一份极具价值的参考资料。
LLM 360:开源框架引领创新
- LLM 360:这是一个开源的LLM框架,汇聚了培训、数据准备、评估指标和模型资源。无论您是研究者还是开发者,都能在此找到所需的工具和灵感。
4. 监督微调:模型个性化的艺术
预训练模型往往专注于基础的下一个标记预测任务,因此难以直接应用于实际场景。而SFT(监督微调)技术,则允许您根据特定需求调整模型,使其能够响应复杂的指令。更重要的是,您可以基于私有数据或GPT-4无法触及的数据集来微调模型,无需支付高昂的API费用。
-
全微调:这是一种涉及所有参数的微调方法,尽管效率有限,但往往能获得较为理想的结果。
-
LoRA:这是一种高效的参数高效技术(PEFT),通过仅训练低阶适配器而非整个模型,实现了更快速、更经济的微调过程。
-
QLoRA:作为LoRA的进阶版本,它不仅基于低阶适配器进行微调,还将模型权重量化为4位,并结合分页优化器以管理内存峰值。配合Unsloth使用,您甚至可以在免费的Colab笔记本上轻松运行。
-
Axolotl:这是一个用户友好的微调工具,支持多种最先进的开源模型,为您的模型调整工作提供强大支持。
-
DeepSpeed:专为多GPU和多节点设置设计的LLM预训练和微调框架,在Axolotl等项目中得到了成功应用。
📚参考资料:
-
Alpin的新手LLM培训指南:为初学者提供了微调LLM时所需的基本概念、参数设置和实用技巧。
-
Sebastian Raschka的LoRA见解:为您深入解读LoRA技术,并提供选择最佳参数的实用建议。### 🔍 精细调整Llama 2模型,探索语言模型的无限潜能
-
自定义Llama 2模型之旅:借助Hugging Face库,走进微调Llama 2模型的奇妙世界。
-
解密大型语言模型填充之道:Benjamin Marie为我们揭示了因果LLM填充训练样本的精湛技巧。
-
LLM 微调新手指南:Axolotl如何助您微调CodeLlama模型,轻松开启LLM之旅。
5. 强化学习:倾听人类之声,塑造智慧模型
在监督微调之后,RLHF如同一道桥梁,将LLM的答案与人类的期望紧密相连。它借助人类的反馈学习偏好,旨在消除偏见、优化模型,使它们更加符合人类的期望。尽管比SFT更为复杂,但RLHF的效用使其成为不可或缺的选项。
-
偏好数据集:这些数据集如同珍贵的宝石,蕴含了人类对不同答案的偏好排序,为模型提供了独特的视角。
-
近端策略优化:此算法凭借奖励模型,洞察文本在人类心中的价值。它据此优化SFT模型,通过KL散度进行巧妙调整。
-
直接偏好优化:DPO将复杂的优化过程简化为分类问题。它无需奖励模型训练,仅通过一个超参数即可实现高效稳定的模型优化。
📚 参考宝库:
-
RLHF引导LLM培训之道:Ayush Thakur的指引,揭示了RLHF在减少LLM偏见、提升性能方面的独特魅力。
-
Hugging Face的RLHF视觉盛宴:RLHF的深入解读,包括奖励模型训练和强化学习微调,为您揭开RLHF的神秘面纱。
-
StackLLaMA教程:Hugging Face团队携手Transformer库,引领您高效地将LLaMA模型与RLHF完美融合。
-
LLM培训探索:RLHF与替代方案:Sebastian Rashcka博士带您领略RLHF流程及RLAIF等替代方案的魅力。- 运用DPO对Mistral-7b进行微调:深入探索DPO微调技术在Mistral-7b模型中的应用,并精准再现NeuralHermes-2.5的精彩教程。
六、评价之艺
在LLM的广阔天地中,评价扮演着被低估却至关重要的角色。它既复杂又细致,需要针对下游任务精准选择评价内容。然而,请铭记古德哈特定律的警示:“一旦某项指标成为目标,其本身的可靠性便值得商榷。”
-
传统评价:虽然困惑度和BLEU分数等指标曾在过去盛行,但它们在今日的实际应用中显露出许多局限性。然而,了解它们以及它们适用的场合仍然是我们不可或缺的知识储备。
-
通用基准:在语言模型评估工具的支持下,开放LLM排行榜为通用LLM(如ChatGPT)提供了主要的评价标杆。同时,也有其他备受瞩目的基准测试,如BigBench和MT-Bench等。
-
任务特定基准:在摘要、翻译、问答等细分任务领域,有着各自专用的评价基准、指标和子领域(如医学、金融等)的特定要求,例如PubMedQA,为生物医学问答领域提供了精准的评价工具。
-
真实用户评价:最终,最真实、最可靠的评价来源于用户的反馈和直接的使用体验。如果你想知道一个模型是否表现出色,最简单也最有效的方法就是亲自试用它。
📚参考资料:
-
Hugging Face对固定长度模型困惑度的深度解析:深入了解使用Transformer库实现困惑度计算的代码细节。
-
BLEU的利弊考量:Rachael Tatman为我们带来了BLEU分数的全面解析,让我们更清晰地了解其优点与不足。
-
Chang等人对LLM评估的深入调查:这篇论文全面探讨了LLM评估的内容、方法及其重要性。
-
lmsys的Chatbot Arena排行榜:基于人类真实评价的通用LLM Elo评级,为我们提供了宝贵的参考。
7. 量化之路
量化,即通过降低模型权重(和激活)的精度来减少计算和内存成本的技术,正变得越来越重要。例如,原本使用16位存储的权重,现在可以被进一步压缩至4位表示。这一技术为我们优化LLM的性能和效率提供了新的方向。
- 基础技术概览:了解不同级别的精度(如FP32、FP16、INT8等)以及如何利用absmax和零点技术实现简单的量化过程。这个链接可能存在安全风险,为了保护您的设备和数据安全,请避免访问此链接。- 位置编码:深入探索 Transformer 中的位置编码机制,特别是那些引人注目的方案,如RoPE、ALiBi和YaRN,这些不仅增强了模型的理解能力,还赋予了处理更广泛上下文窗口的能力。(虽然它与直接的推理优化无直接联系,但无疑为模型提供了更广阔的视野。)
📚参考资料:
-
GPU Inference by Hugging Face:详细阐述了如何在GPU上实现高效的推理过程。
-
Optimizing LLMs for Speed and Memory by Hugging Face:详细解读了三种关键技术——量化、Flash Attention和架构创新,它们如何助力我们优化大型语言模型的速度和内存使用。
-
Assisted Generation by Hugging Face:这是一篇极具洞察力的博客,HF版本的推测解码技术在此得到了详尽的解读,其背后的实现逻辑令人着迷。
-
Extending the RoPE by EleutherAI:一篇综述性文章,对不同的位置编码技术进行了全面的梳理和总结。
-
扩展上下文很难……但并非不可能,作者:kaiokendev:在这篇博文中,作者深入探讨了SuperHOT技术,并为我们带来了关于相关工作的精彩解读,为读者呈现了一个宏大的视角。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓
















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











