






练习1-开始了解你的数据
探索Chipotle快餐数据
相应数据集:chipotle.tsv
import pandas as pd
chipo=pd.read_csv("exercise_data/chipotle.tsv",sep='t')
chipo.head(5)
chipo.shape[0] #查看有多少行
4622
chipo.shape[1] #查看有多少列
5
chipo.columns #打印所有列名
Index(['order_id', 'quantity', 'item_name', 'choice_description',
'item_price'],
dtype='object')
chipo.index #打印索引
RangeIndex(start=0, stop=4622, step=1)c=chipo[['item_name','quantity']].groupby(['item_name'],as_index=False).agg({'quantity':sum})
c.sort_values(['quantity'],ascending=False,inplace=True)
c.head(5)
#被下单数最多商品(item)是什么?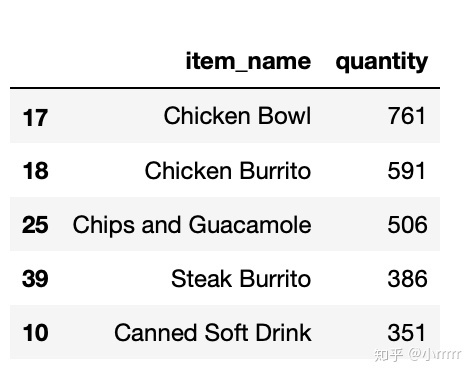
chipo['item_name'].nunique()
#在item_name这一列中,一共有多少种商品被下单?
5
chipo['choice_description'].value_counts().head()
#在choice_description中,下单次数最多的商品是什么?
chipo['quantity'].sum()
#一共有多少商品被下单?
4972lambda函数,apply和map区别
dollarizer = lambda x: float(x[1:-1])
#x为item_price这列组成的数组,对其切片,取第二个(下标为1)到最后一个数,即把美元符号去掉
chipo['item_price'] = chipo['item_price'].apply(dollarizer)
#将item_price转换为浮点数
chipo['revenue']=chipo['quantity']*chipo['item_price']
total=round(chipo['revenue'].sum(),2)
total
#在该数据集对应的时期内,收入(revenue)是多少
39237.02chipo['order_id'].nunique()
#在该数据集对应的时期内,一共有多少订单?
1834先分组,再求和,再求平均
c=round(chipo[['order_id','revenue']].groupby(['order_id']).agg({'revenue':sum})['revenue'].mean(),2)
c
#每一单(order)对应的平均总价是多少?
21.39练习2-数据过滤与排序
探索2012欧洲杯数据
相应数据集:Euro2012_stats.csv
import pandas as pd
euro=pd.read_csv("Euro2012_stats.csv")
euro.head()
#只选取 Goals 这一列
euro['Goals']
0 4
1 4
2 4
3 5
4 3
5 10
6 5
7 6
8 2
9 2
10 6
11 1
12 5
13 12
14 5
15 2
Name: Goals, dtype: int64#有多少球队参与了2012欧洲杯?
euro.shape[0]
16
#该数据集中一共有多少列(columns)?
euro.shape[1]
35
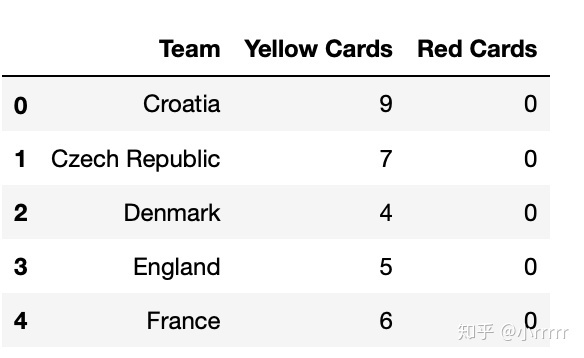
#将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框
discipline=euro[['Team','Yellow Cards','Red Cards']]
discipline.head()
#对数据框discipline按照先Red Cards再Yellow Cards进行排序
discipline.sort_values(['Red Cards','Yellow Cards'],ascending=False)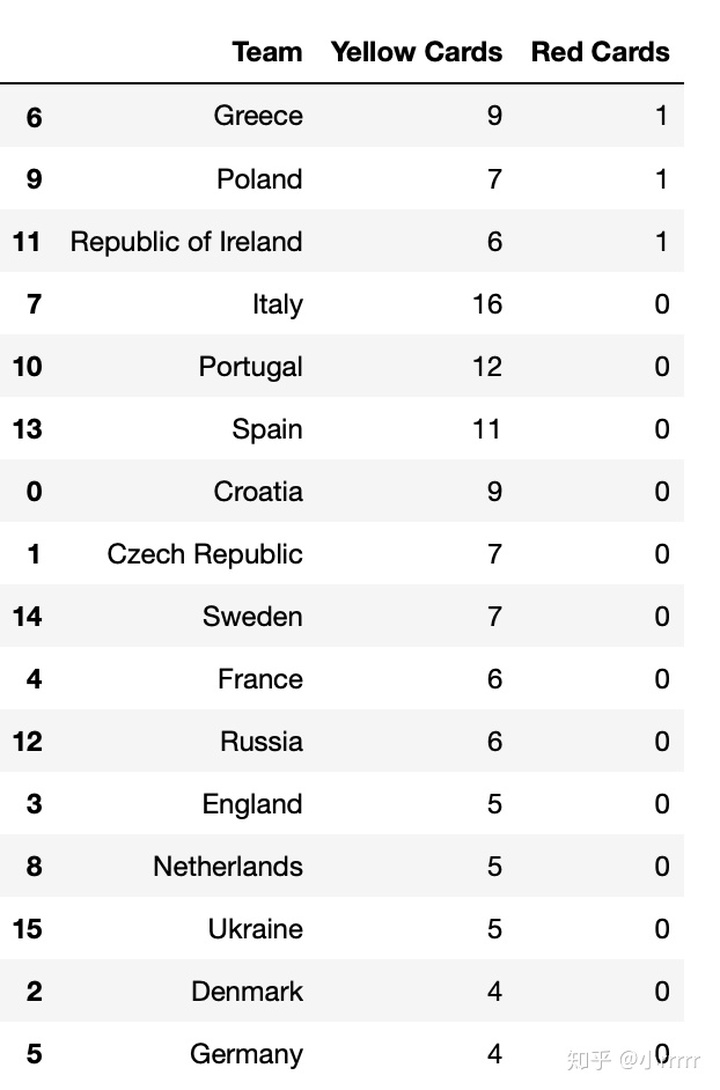
#计算每个球队拿到的黄牌数的平均值
round(discipline['Yellow Cards'].mean())
7
#找到进球数Goals超过6的球队数据
euro[euro['Goals']>6]
#选取以字母G开头的球队数据
euro[euro['Team'].str.startswith('G')]
#选取前7列
euro.iloc[:,0:7] #切片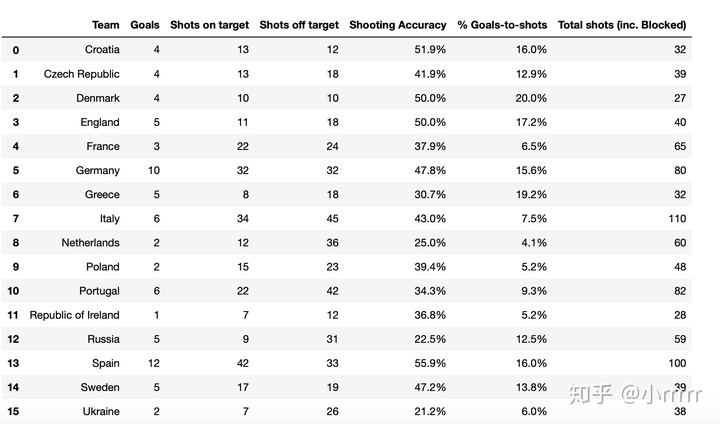
按行号列号切片
#选取除了最后3列之外的全部列
euro.iloc[:,0:-3]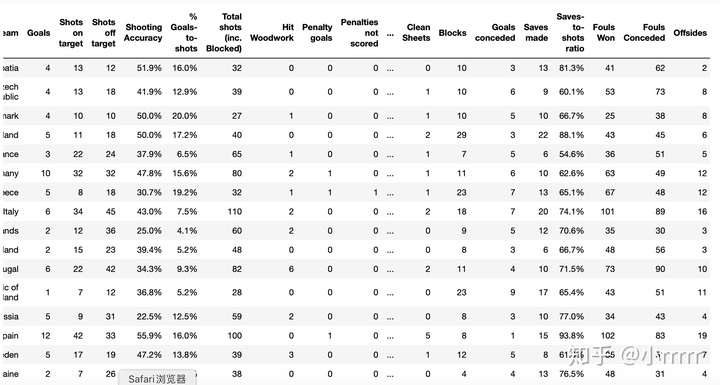
按列名切片
#找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
euro.loc[euro.Team.isin(['England','Italy','Russia']),['Team','Shooting Accuracy']]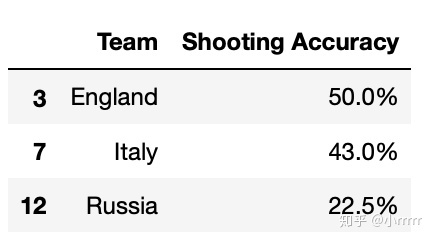
练习3-数据分组
探索酒类消费数据
相应数据集:drinks.csv
import pandas as pd
drinks=pd.read_csv(r"/Users/a2016/exercise_data/drinks.csv")
drinks.head()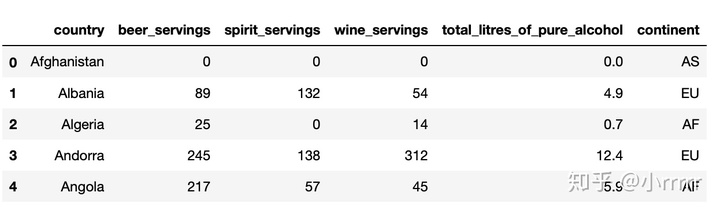
#哪个大陆(continent)平均消耗的啤酒(beer)更多?
drinks.groupby(['continent'])['beer_servings'].mean()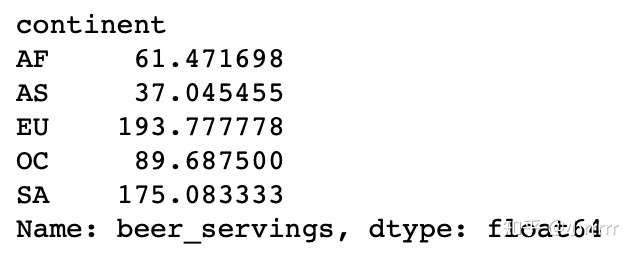
#打印出每个大陆(continent)的红酒消耗(wine_servings)的描述性统计值
drinks.groupby(['continent'])['wine_servings'].describe()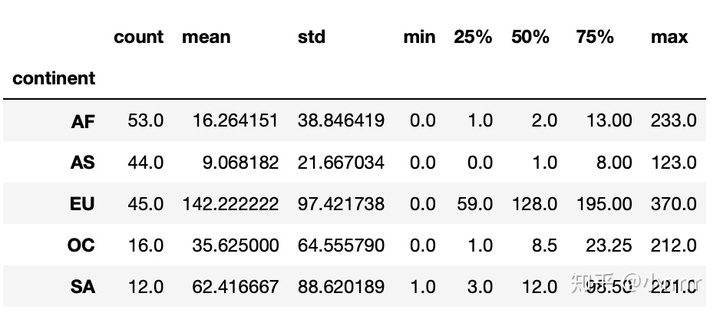
#打印出每个大陆每种酒类别的消耗平均值
drinks.groupby(['continent']).mean()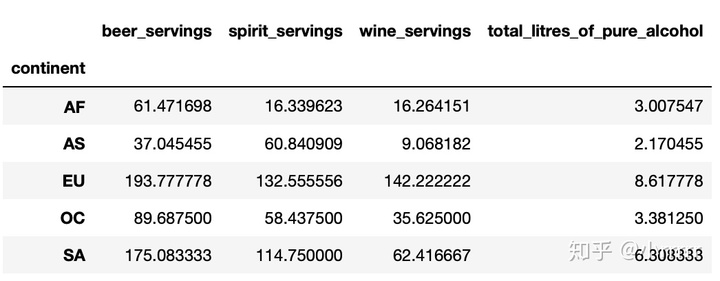
求中位数 median()
#打印出每个大陆每种酒类别的消耗中位数
drinks.groupby(['continent']).median()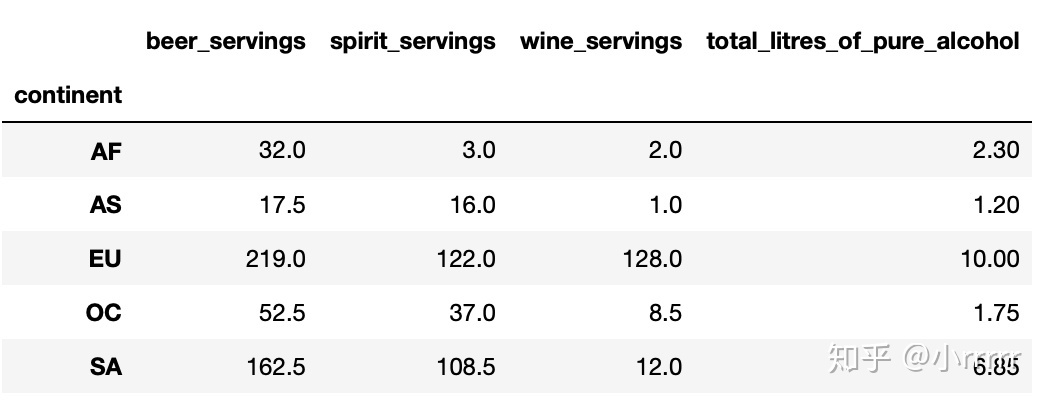
#打印出每个大陆对spirit饮品消耗的平均值,最大值和最小值
drinks.groupby(['continent'])['spirit_servings'].agg(['mean','max','min'])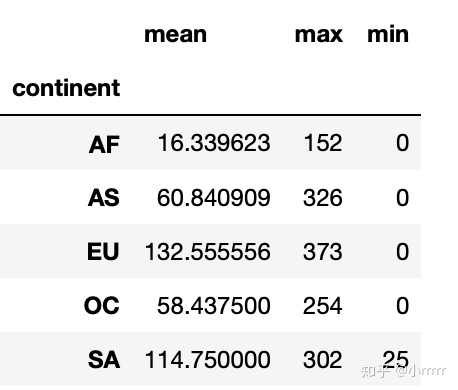
练习4-Apply函数
探索1960-2014美国犯罪数据
相应数据集:US_Crime_Rates_1960_2014.csv
import pandas as pd
US=pd.read_csv(r"/Users/a2016/exercise_data/US_Crime_Rates_1960_2014.csv")
US.head()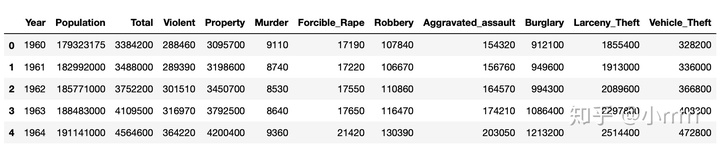
#每一列(column)的数据类型是什么样的?
US.dtypes
Year int64
Population int64
Total int64
Violent int64
Property int64
Murder int64
Forcible_Rape int64
Robbery int64
Aggravated_assault int64
Burglary int64
Larceny_Theft int64
Vehicle_Theft int64
dtype: object注意到Year的数据类型为int64,但是pandas有一个不同的数据类型去处理时间序列(time series),将year的数据类型更改。
#将Year的数据类型转换为 datetime64
US['Year']=pd.to_datetime(US['Year'],format='%Y')
US.dtypes
Year datetime64[ns]
Population int64
Total int64
Violent int64
Property int64
Murder int64
Forcible_Rape int64
Robbery int64
Aggravated_assault int64
Burglary int64
Larceny_Theft int64
Vehicle_Theft int64
dtype: object#将列Year设置为数据框的索引
US = US.set_index('Year', drop = True)
US.head()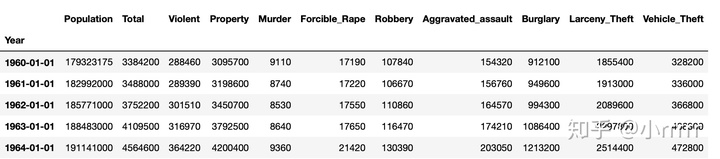
#删除名为Total的列
del US['Total']
US.head()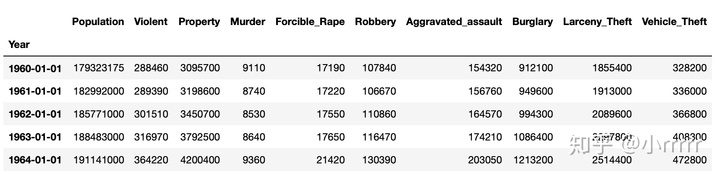
#日期汇总数据,将数据以10AS十年聚合日期第一天开始的形式进行聚合 索引
US.resample('10AS').sum()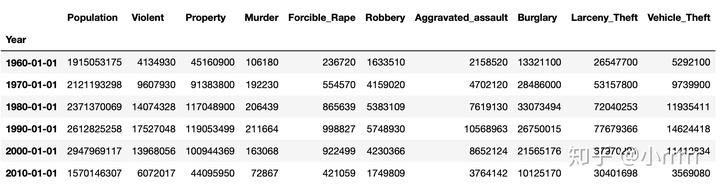
#按照Year对数据框进行分组并求和***注意Population这一列,若直接对其求和,是不正确的***
resample 的介绍
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.resample.htmlpandas.pydata.org# 用resample去得到“Population”列的每十年中的最大值
population = US['Population'].resample('10AS').max()
population
Year
1960-01-01 201385000
1970-01-01 220099000
1980-01-01 248239000
1990-01-01 272690813
2000-01-01 307006550
2010-01-01 318857056
Freq: 10AS-JAN, Name: Population, dtype: int64#让每十年中的最大值代替population这一列
US1['Population']=population
US1
#何时是美国历史上生存最危险的年代?
US.idxmax(0)
练习5-合并
探索虚拟姓名数据
相应数据集:练习自定义的数据集
import pandas as pd
import numpy as np# 运行以下代码
raw_data_1 = {
'subject_id': ['1', '2', '3', '4', '5'],
'first_name': ['Alex', 'Amy', 'Allen', 'Alice', 'Ayoung'],
'last_name': ['Anderson', 'Ackerman', 'Ali', 'Aoni', 'Atiches']}
raw_data_2 = {
'subject_id': ['4', '5', '6', '7', '8'],
'first_name': ['Billy', 'Brian', 'Bran', 'Bryce', 'Betty'],
'last_name': ['Bonder', 'Black', 'Balwner', 'Brice', 'Btisan']}
raw_data_3 = {
'subject_id': ['1', '2', '3', '4', '5', '7', '8', '9', '10', '11'],
'test_id': [51, 15, 15, 61, 16, 14, 15, 1, 61, 16]}
# 运行以下代码
data1 = pd.DataFrame(raw_data_1, columns = ['subject_id', 'first_name', 'last_name'])
data2 = pd.DataFrame(raw_data_2, columns = ['subject_id', 'first_name', 'last_name'])
data3 = pd.DataFrame(raw_data_3, columns = ['subject_id','test_id'])纵向合并两个表,用concat。前提是两个表的列名对应
#将data1和data2两个数据框纵向合并,命名为all_data
all_data=pd.concat([data1,data2])
all_data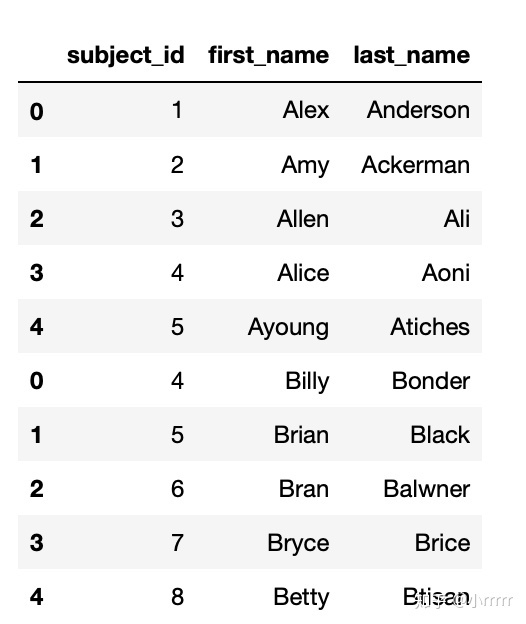
#将data1和data2两个数据框横向合并,命名为all_data_col
all_data_col=pd.concat([data1,data2],axis=1)
all_data_col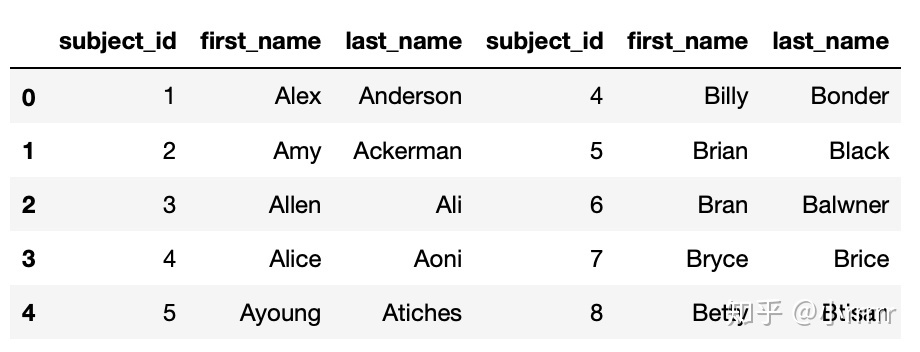
#按照subject_id的值对all_data和data3作合并
pd.merge(all_data,data3,on='subject_id')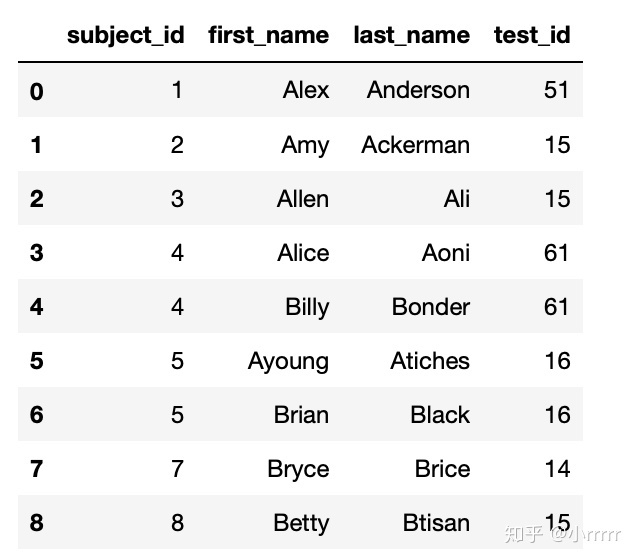

#对data1和data2按照subject_id作连接
pd.merge(data1,data2,on='subject_id',how='inner')
#找到 data1 和 data2 合并之后的所有匹配结果
pd.merge(data1,data2,on='subject_id',how='outer')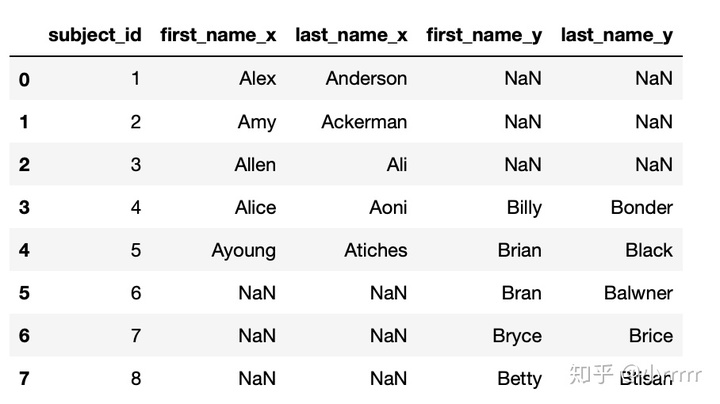















 8563
8563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









