








请点击上方“民生运维人” 添加订阅!
01背景
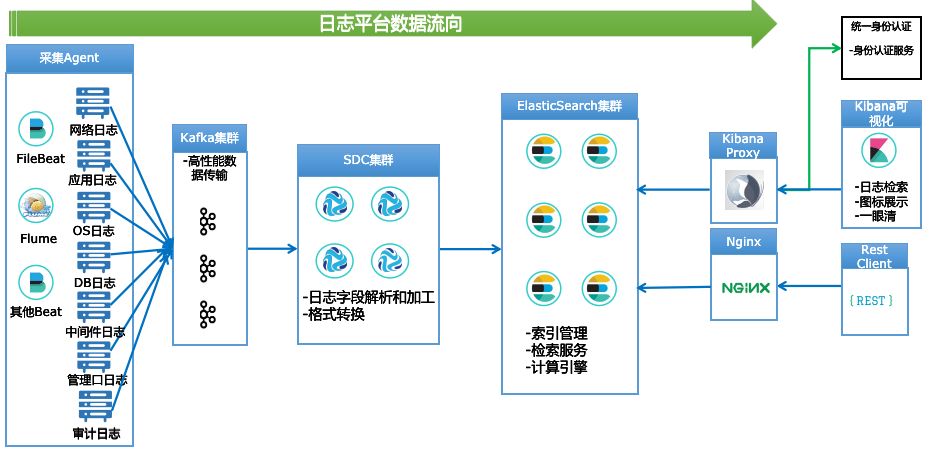
天眼日志平台自投产后,目前已接入网络日志、应用日志、操作系统、数据库、中间件等多种类型日志,每日数据量约为10T+。下图是天眼日志平台的数据流向图,原始日志的数据流向是采集Agent->Kafka集群->SDC集群->Elasticsearch集群,整条数据链路上涉及了多个开源组件和系统。随着平台逐步推广使用和用户群的增加,我们收到一些同事关于日志上送延迟的抱怨,而现有的监控手段无法解决这种诉求,也就是我们无法得知哪些日志有延迟、日志到底延迟了多久,只能依赖使用用户的反馈,因此如何对日志平台全链路的延迟进行监控,将运维模式变被动为主动,成为了我们亟待解决的问题。
02
方案和实现效果
在对日志链路上所有开源组件(Filebeat、Flume、Kafka、Streamsets和Elasticsearch)的调研和源码改造基础上,我们提出了一个方案(原理图如下):获取日志数据经过每个组件的时间戳,即在每一条日志数据中添加4个时间戳:Agent采集数据的时间time_agent、数据入kafka的时间time_kafka、数据入SDC的时间time_sc、数据入ES time_es的时间,再结合原始日志中带的时间戳time_log,通过差值计算出整条链路上端到端延迟以及每个阶段的延迟。
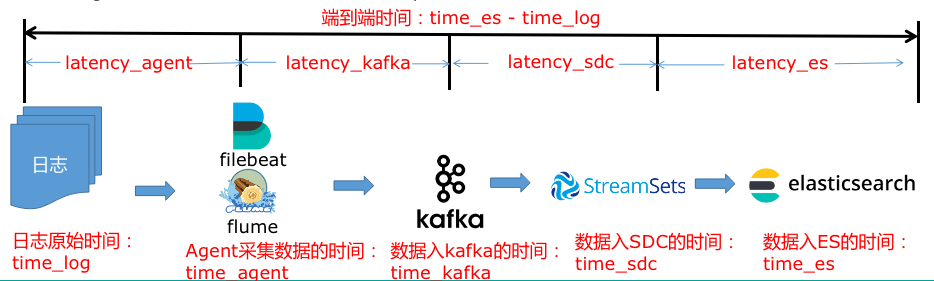

在测试环境经过方案的验证后,我们在生产上选取了7套系统进行了实践,并通过Kibana进行了延迟相关数据的展示。以下是某系统的日志链路延迟监控展示图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









