







丁易锋
丁易锋,网易游戏资深运维工程师,主要工作方向为网易游戏项目运维支持。专注于运维技术的突破,以及为产品提供更加高质量和便捷的服务支撑。
前言
微服务架构是一种架构模式,它提倡将单一应用程序划分成一组小的服务,服务之间相互协调、互相配合,为用户提供最终价值。每个服务运行在其独立的进程中,服务和服务之间采用轻量级的通信机制相互沟通。每个服务都围绕着具体的业务进行构建,并且能够被独立的部署到生产环境、类生产环境等。
微服务加上如今的服务发现,在基础设施即代码(指使用脚本配置计算基础设施,而不是手动配置计算机的方法)的过程中,我们正在不断的尝试各种实践方案。如何在云基础设施下结合业务场景,通过负载均衡、服务发现、容器化来实现业务链自动化,这就是本文给大家带来的分享。
背景介绍
困扰和烦恼
首先来看下我们其中一个平台之前的大体架构:
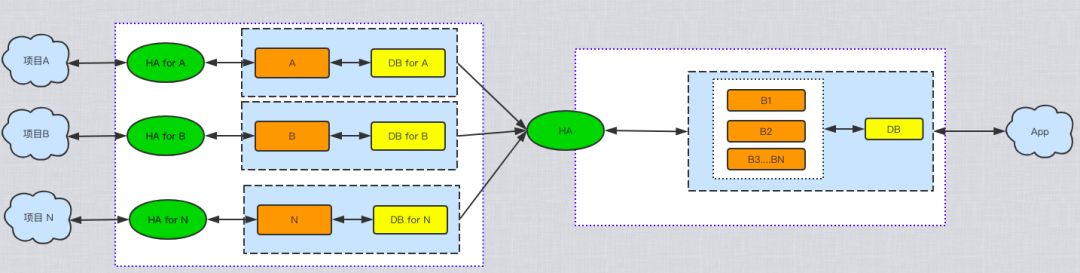
随着业务的递增,我们遇到了以下的问题:
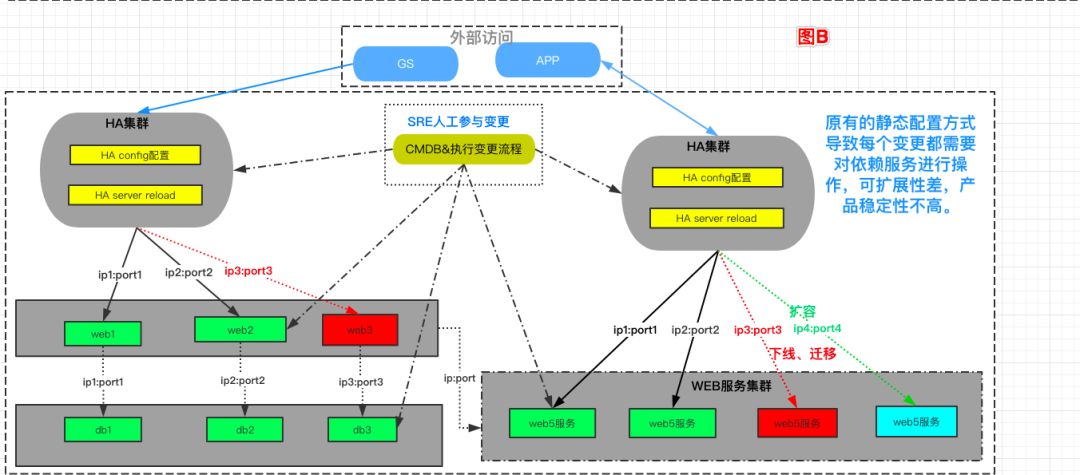
在非云环境下,为了节省资源,当前只能通过业务混布的方式提高资源利用率,但这种方式可能会导致业务之间互相影响,不能进行有效的隔离,并无法实现资源最大化利用;
由于每个业务都要使用独立一套资源进行隔离,一个业务的上下线至少需要进行 10-15 个步骤来完成;
静态的配置导致多个服务互相依赖时,每次服务 A 变更需要通知依赖服务 B 进行变更,变更维护等一系列的流程变得成本越来越高;
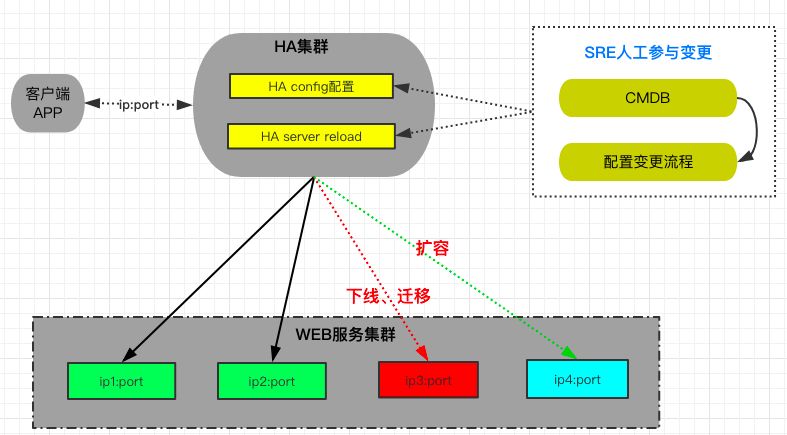
混布业务的机器异常会导致上面的 N 个服务受影响,需要人工介入花费大量时间确保服务恢复正常,故障自动恢复程度不高;
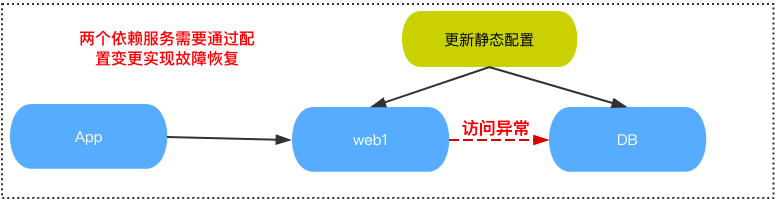
变更所带来的数据信息变动需要额外的机制来保证实时更新,保证产品的稳定性。
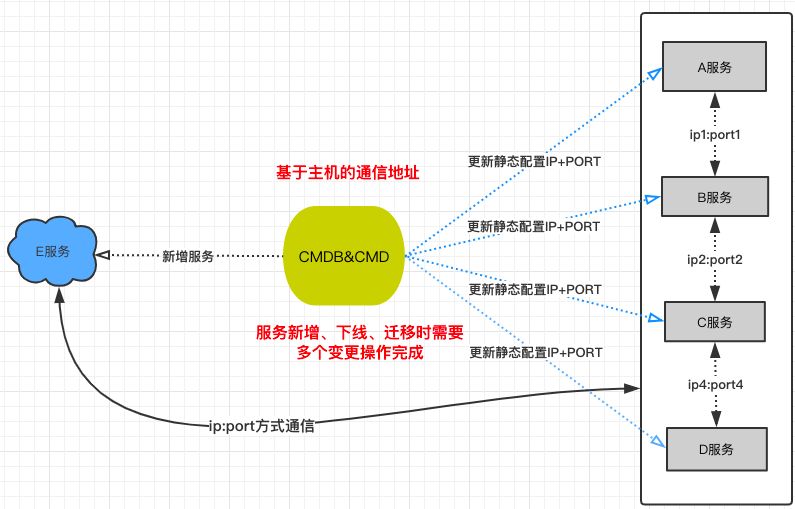
新思路和改进
容器化部署:首先我们将服务通过编程化,指定 CPU、MEM、DISK 等等一些列参数配置我们的基础系统环境,利用镜像批量创建 N 个 docker 容器(微服务化的同时,我们通过编程化的方式来解决硬件基础设置的利用率提升问题)。
服务发现:在容器创建时的 ip 随机分配时,在频繁的创建销毁过程中,如何让各个服务之间实现自动快速的通信?这里我结合了 Consul 的域名服务发现功能,能够在 1 分钟左右实现从容器销毁-->容器新建--->服务恢复可用,整个过程自动完成,保证容器本身和其它容器互相访问的一个正常通信。
什么是服务发现?
在分布式微服务架构中,一个应用可能由一组职责单一化的服务组成。这时候就需要一个注册服务的机制,注册某个服务或者某个节点是可用的,还需要一个发现服务的机制来找到哪些服务或者哪些节点还在提供服务。
在实际应用中,通常还都需要一个配置文件告诉我们一些配置信息,比如数据连接的地址,redis 的地址等等。但很多时候,我们想要动态地在不修改代码的情况下得到这些信息,并且能很好地管理它们。
然而,服务发现组件记录了(大规模)分布式系统中所有服务的信息,其它服务可以据此找到这些服务。DNS 就是一个简单的例子。当然,复杂系统的服务发现组件要提供更多的功能,例如,服务元数据存储、健康监控、多种查询和实时更新等。服务发现是支撑大规模 SOA 的核心服务。
Consul介绍
Consul 是一个支持多数据中心分布式高可用,用于服务发现和配置共享的开源工具。它具有开箱即用、可跨系统平台部署(在任何基础架构上连接任何应用)等特点。Consul 的三个主要应用场景:服务发现、服务隔离、服务配置。Consul 关键特性:
多数据中心
服务发现
健康检查
Key/Value 存储
运行时编排 (Consul Template)
Web UI
Consul 之服务发现
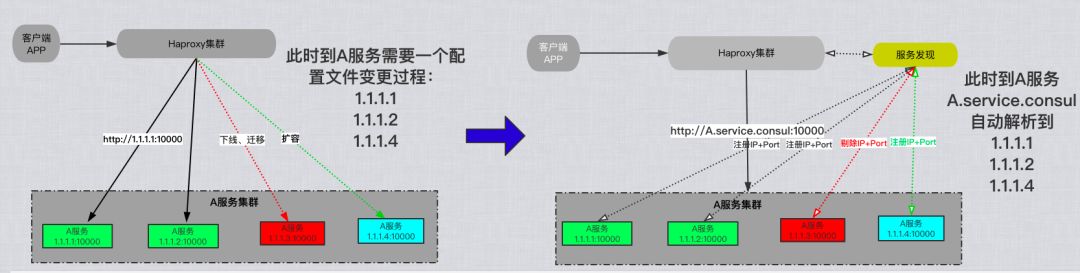
通过 HTTP 和 DNS 进行服务发现简化了跨分布式基础架构部署的连接服务。
通信方式从以往的
ip:port向域名:port的转变。变更(新增/缩减等)的服务会实时自动更新域名解析地址,即 consul 内部域名保持实时解析最新的可用服务地址。
具有服务健康检查、心跳检测、服务域名等等一系列可自定义特性。
Consul 之服务配置
首先 Consul 集群内的所有数据都是可共享的,任何一个节点都是可以同时获取到集群内最新的数据信息。然后通过一些例如 Key/Value、server、node 等等数据进行文本内容渲染,从而达到一个变更的全程实时自动化。例如根据 Key/Value 信息渲染:
#For example:
{{ range tree "service/redis" }}
{{ .Key }}:{{ .Value }}{{ end }}#renders
minconns 2
maxconns 12
nested/config/value "value"
例如根据服务信息渲染:
#For example:
{{ range service "web" }}server {{ .Name }}{{ .Address }}:{{ .Port }}{{ end }}
#renders the IP addresses of all healthy nodes with a logical service named "web":server web01 10.5.2.45:2492server web02 10.2.6.61:2904
在传统运维方式上可以有哪些改变
Consul 让服务具有较强的可扩展性,根据其动态的服务注册和健康检测,可以使服务被频繁替换时,避免服务中断。
Consul 让配置文件管理变得更加轻松,不用经过 CMDB 和多个变更流程实现,配置内容跟随业务进行实时自动变化调整。
传统方式如何向微服务化转变
入口的动态自动化
容器和服务发现始终只是在对内部的通信实现,如何将这些服务快速方便的对外实现通信,并且能够高度自动化呢?我们通过将 HA 作为各类后端服务的对外统一入口;配置 backend 服务时,配置的是 Consul 中的服务域名。从而作为内部和外部通信的一个通信转发枢纽。
HA 的域名动态解析
首先看看容器化下的服务地址是怎样通过 consul 完成变更的。
容器新建or销毁等操作频繁,ip地址随机生成分配一个。
每个服务有一个consul域名,对应一个容器的ip地址,进行服务地址注册。
容器重建后,consul的域名对应的ip重新注册,刷新服务地址,consul DNS域名解
析会立即发生更新变化,对外完成变更。
然后为什么是 HA 的 DNS 动态解析?这个不是 DNS 的锅么?
在常见的代码更新、服务配置变更、迁移、扩容等需要容器重建时,会导致N个容器同时发生Consul域名解析变更(当然也是预期内的变更),这个时候需要使用了consul域名的服务在访问失败时能够去重新解析一次域名获取新的ip,完成解析的自动变更。
需要注意的是这里有个坑,原来使用haproxy 1.5版本, 后端服务配置使用域名时,启动服务后只解析一次(和nginx类似)域名,这时如果已解析的服务挂掉或进行了切换等,即使异常节点已屏蔽,访问HA时依然会出现例如503等异常(即使DNS已经发生了改变,但HA服务本身缓存了旧ip等于地址未更新)。后续查询官网得知haproxy 1.6+才支持了动态dns。
如何利用 HA 的域名解析配置实现后端路由动态化
首先,HA配置增加一段 resolvers 定义,用来实现 HA 的域名动态解析。
resolvers consuldns
nameserver dns1 127.0.0.1:53
resolve_retries 200
timeout retry 1s
hold valid 10s
其次,对不同业务环境隔离的路由分发,同样需要增加 HA 的 frontend 配置进行流量隔离。
#自定义服务监听相关逻辑
frontend serverA
balance leastconn
cookie JSESSIONID prefix
bind 0.0.0.0:1000 accept-proxy
capture request header Host len 128
option httplog
log-format %si:%sp\ %ci\ %ft\ %hrl\ %r\ %ST\ %B\ %Tt
#自定义ACL(路由)策略
acl host_hostname1 hdr_dom(host) -i a.test.com
acl host_hostname2 hdr_dom(host) -i b.test.com
use_backend hostname1 if host_hostname1
use_backend hostname2 if host_hostname2
最后,在 HA 的 backend 处引用前面定义的 resolvers 和 frontend,实现到后端rs的动态转发。
#自定义转发的rs地址,采用consul域名配置,利用自定义resolvers consuldns进行动态解析,从而保证后端服务自动化变更的灵活性。
backend hostname1
server hostname1 a.service.consul:1000 resolvers consuldns maxconn 50000 check inter 2000 rise 2 fall 100
backend hostname2
server hostname2 b.service.consul:1000 resolvers consuldns maxconn 50000 check inter 2000 rise 2 fall 100
.........
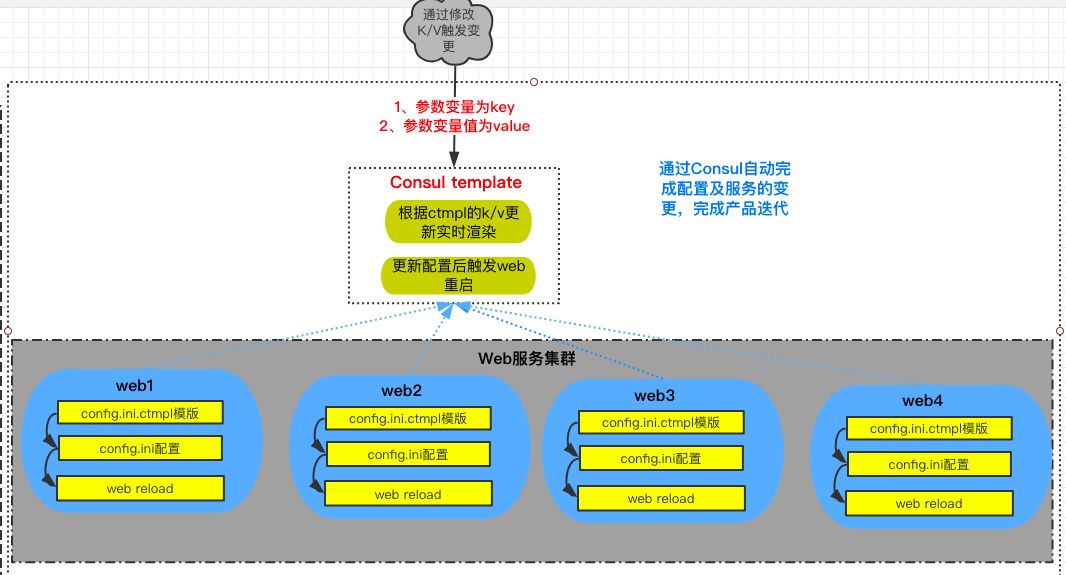
WEB 配置内容自动托管
文件内容更新:使用 Consul 的 K/V watch 功能,一旦有新服务上线/下线时,配置自动化接入和自动化下线流程,更新 web 服务配置并 reload(触发脚本完成),完成整个流程的自动化。
#当监控的key状态发生变化时,触发执行指定的自定义脚本。
/usr/local/bin/consul watch -type=key -key=key名 自定义触发的脚本路径。
#当监控的key状态发生变化时,实时渲染配置文件,并执行reload。
consul-template -consul-addr 127.0.0.1:8500 -template "ha.conf.ctmpl:ha.conf:HA reload"
后端服务自动加入集群
云主机节点自动初始化自身后进行服务注册,自动导入流量。
#web_service.json
{
"service": {
"name": "web",
"port": 80,
"id": "web",
"address": "10.1.1.1",
"check": {
"id": "web",
"name": "tcp",
"tcp": "10.1.1.1:80",
"interval": "60s",
"timeout": "30s"
}
}
}
#nslookup web.service.consul
Server: 127.0.0.1
Address: 127.0.0.1#53
Name: web.service.consul
Address: 10.1.1.1
Name: web.service.consul
Address: 10.1.1.2
Name: web.service.consul
Address: 10.1.1.3
总结
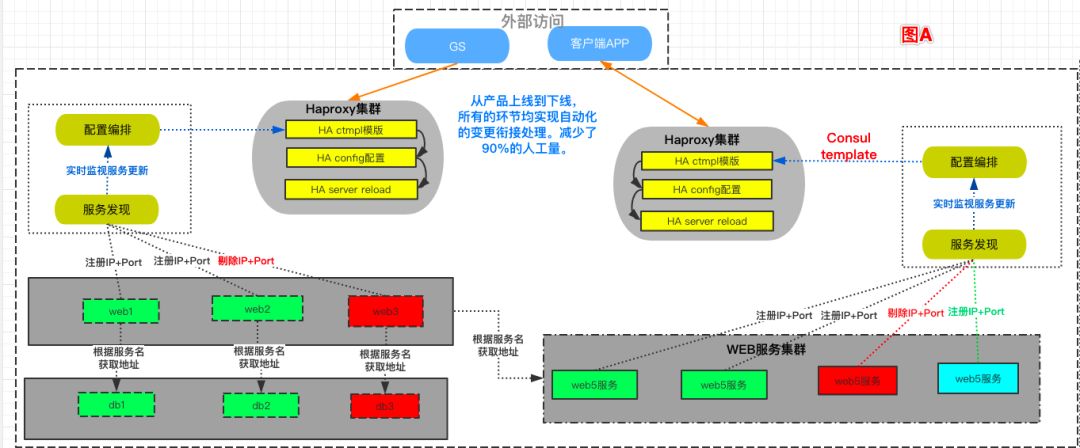
总的来说,我们根据业务特性,使用HA、Consul、docker 这样的一个组合来实现高度可扩展性、稳定性,及流程的基本全自动化过程。
业务链高度自动化,从上线到下线,整个流程包括服务上线、配置变更、产品发布、功能迭代、下线回收等全自动衔接完成。
利用云特性解决不同业务之间的资源隔离问题,并根据服务性能分配 cpu、mem、disk 等实现硬件基础资源编程化。
整套业务拆分,微服务化,每个服务一个 docker 实例,故障自动漂移恢复,通过服务发现实现自愈,去掉人工介入环节。
利用 consul 解决服务模块的扩展性,根据其动态的服务注册和健康检测功能,在避免服务中断的情况下,可以接受服务的频繁变更。
利用 HA 统一我们的入口,容器化后的服务,变更时产生的容器销毁&创建导致服务地址变更时,HA 和 consul 是实时监控服务心跳,自动更新 DNS 解析,整套环境高度自动化。
整个过程至少实现了:
-
服务依赖解耦
配置文件的动态自动化变更
产品的自动发布
服务故障自愈
不断简化的流程和中间层
HA 代理的弱化与替代
基础设施云化,利用率提升
去掉了 90% 的人工参与过程。
现在(图 A)和原有(图 B)对比如下:
关注我们,获一手游戏运维方案

感谢阅读,如果好看请点击右下角「在看」,点亮小星星,变亮的星星是小编的动力哦!















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









