






堆的概念:
堆是一种完全二叉树,非叶子结点 i 要满足key[i]>key[i+1]&&key[i]>key[i+2](最大堆) 或者 key[i]
堆排序基本思想:(以最大堆为例)
利用完全二叉树性质将一个无序序列构建最大堆,使得每次从无序中选择最大记录变得简单。
1)将初始待排序无序序列(R1,R2....Rn)构建成大顶堆,此堆为初始的无序序列;
2)将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,......Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n];
3)由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,......Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2....Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
举例说明:
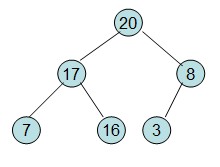
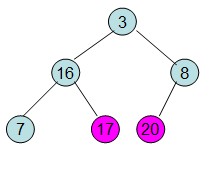
假设初始序列为a[]={16,7,3,20,17,8},根据该数组构建一个初始完全二叉树
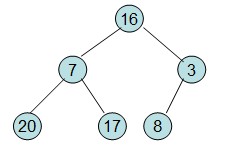
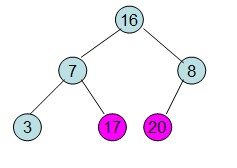
然后从最后一个非叶子节点开始构建初始堆,根据最大堆的性质来构建,过程如下:
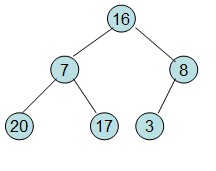
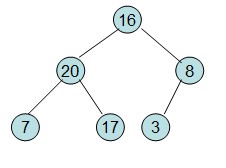
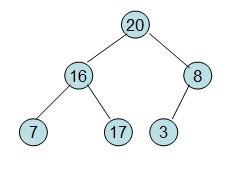
调整后16节点不满足性质,从新调整
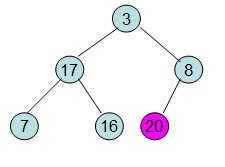
这样就得到了初始堆。
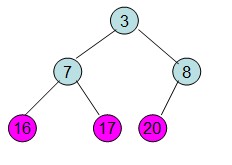
即每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换(交换之后可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整)。有了初始堆之后就可以进行排序了。
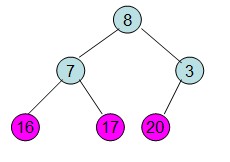
交换根节点和叶子节点
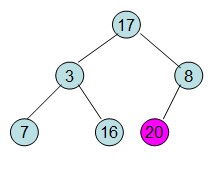
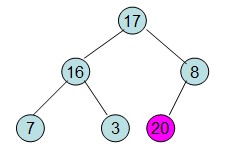
交换后,不满足最大堆性质,继续根据上面步骤重新构造最大堆。
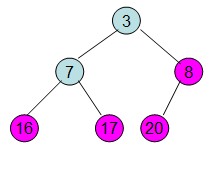
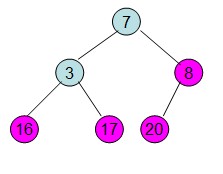
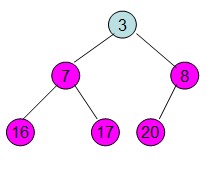
Java代码实现:
packagepaixu;importjava.util.Arrays;public classDuiPaiXu {public static voidmain(String[] args) {int[] a={16,7,3,20,17,8};int arrayLength=a.length;//循环建堆
for(int i=0;i
buildMaxHeap(a,arrayLength-1-i);//交换堆顶和最后一个元素
swap(a,0,arrayLength-1-i);
System.out.println(Arrays.toString(a));
}
}//对data数组从0到lastIndex建大顶堆
public static void buildMaxHeap(int[] data, intlastIndex){for(int i=(lastIndex-1)/2;i>=0;i--){ //从最后一个非叶子结点开始建堆
int k=i; //k保存正在判断的节点
while(k*2+1<=lastIndex){ //如果当前k节点的子节点存在
int biggerIndex=2*k+1; //k节点的左子节点的索引
if(biggerIndex
if(data[biggerIndex]
biggerIndex++; //biggerIndex总是记录较大子节点的索引
}
}//如果k节点的值小于其较大的子节点的值
if(data[k]
swap(data,k,biggerIndex);//将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k=biggerIndex;
}else{break;
}
}
}
}//交换
private static void swap(int[] data, int i, intj) {int tmp=data[i];
data[i]=data[j];
data[j]=tmp;
}
}
从上述过程可知,堆排序其实也是一种选择排序,是一种树形选择排序。只不过直接选择排序中,为了从R[1...n]中选择最大记录,需比较n-1次,然后从R[1...n-2]中选择最大记录需比较n-2次。
事实上这n-2次比较中有很多已经在前面的n-1次比较中已经做过,而树形选择排序恰好利用树形的特点保存了部分前面的比较结果,因此可以减少比较次数。对于n个关键字序列,最坏情况下每个
节点需比较log2(n)次,因此其最坏情况下时间复杂度为nlogn。堆排序为不稳定排序,不适合记录较少的排序。
算法性能分析:
时间复杂度:平均时间复杂度为O(nlogn)。
空间复杂度:O(1)。
稳定性:堆排序的过程是从第n/2开始和其子节点共3个值选择最大(大顶堆)或者最小(小顶堆),这3个元素之间的选择当然不会破坏稳定性。但当为n /2-1, n/2-2, ...1这些个父节点选择元素时,
就会破坏稳定性。有可能第n/2个父节点交换把后面一个元素交换过去了,而第n/2-1个父节点把后面一个相同的元素没 有交换,那么这2个相同的元素之间的稳定性就被破坏了。
所以,堆排序不是稳定的排序算法。















 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









