






准备工具:
htmlParser架包下载地址:【https://sourceforge.net/projects/htmlparser/files/htmlparser/】
参考API地址:【http://tool.oschina.net/apidocs/apidoc?api=HTMLParser】
程序实现获取【http://www.ygdy8.net/html/gndy/dyzz/index.html】此网站上所有电影的下载地址。
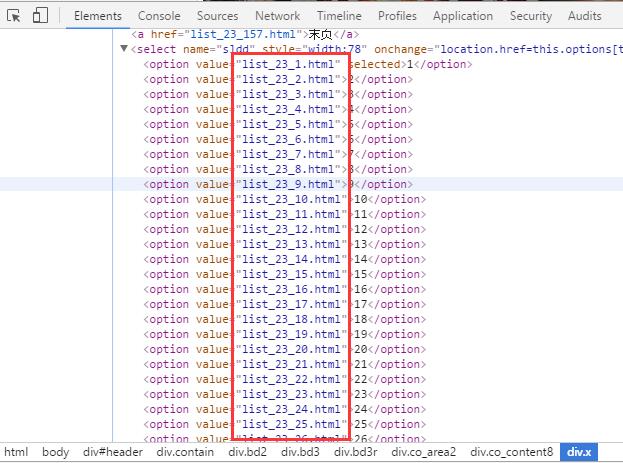
分析页面数据:本网页共有157页,每页25部电影介绍,点击进入电影介绍就可以看见下载链接
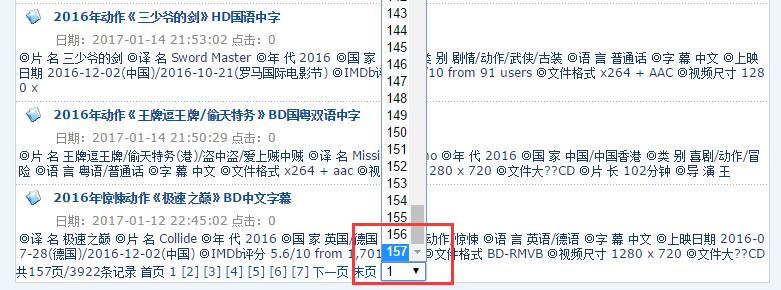
点击电影介绍进入下载页面
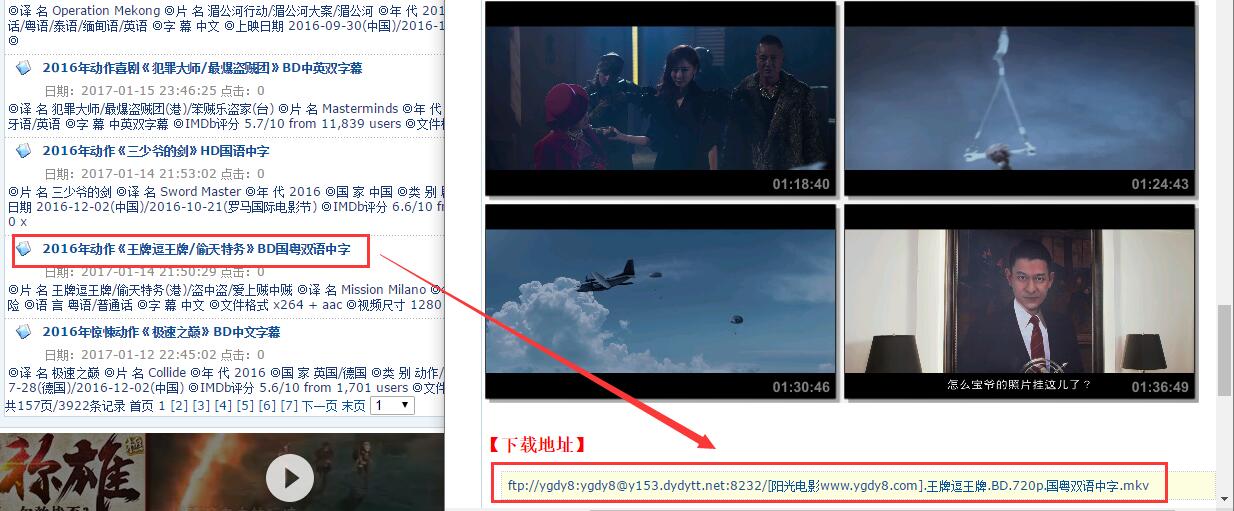
一、获取157页"电影介绍地址"
经过分析,value的值是目标数据:
/**
* 从http://www.ygdy8.net/html/gndy/dyzz/index.html网页里获取157个电影分页的地址
*
* @return List集合存储157个分页地址
*/
public static List getAllPageList() {
List<String> pageList = new ArrayList();
try {
Parser parser = new Parser("http://www.ygdy8.net/html/gndy/dyzz/index.html");
// match匹配带option属性的标签
NodeList nodeList = parser.extractAllNodesThatMatch(new TagNameFilter("option"))
.extractAllNodesThatMatch(new HasAttributeFilter("value"));
for (int i = 0; i < nodeList.size(); i++) {
OptionTag tag = (OptionTag) nodeList.elementAt(i);
String link = tag.getAttribute("value");
// 筛选既带有option属性又含有list的标签
if (link.contains("list")) {
// System.out.println(i+",,,"+link);
pageList.add("http://www.ygdy8.net/html/gndy/dyzz/" + link);
}
}
} catch (ParserException e) {
e.printStackTrace();
}
return pageList;
}二、获取每页含有的"电影介绍地址"
/**
*
* 获取每页25个电影的介绍地址
*/
public static List getAllMovieUrlFromOnePageList(String pageListUrl) {
List<String> allMoveUrl = new ArrayList<String>();
try {
Parser parser = new Parser(pageListUrl);
NodeList nodeList = parser.extractAllNodesThatMatch(new HasAttributeFilter("class", "ulink"));
for (int i = 0; i < nodeList.size(); i++) {
LinkTag tag = (LinkTag) nodeList.elementAt(i);
// System.out.println(tag.getLink());
allMoveUrl.add("http://www.ygdy8.net" + tag.getLink());
}
} catch (ParserException e) {
e.printStackTrace();
}
return allMoveUrl;
}三、获取下载地址
/**
* 获取电影的下载地址
*/
public static String[] getMovieDownloadUrl(String movieIntroUrl) {
String[] downloadUrl = null;
try {
Parser parser = new Parser(movieIntroUrl);
NodeList nodeList = parser.extractAllNodesThatMatch(new LinkStringFilter("ftp"));
for (int i = 0; i < nodeList.size(); i++) {
LinkTag tag = (LinkTag) nodeList.elementAt(i);
System.out.println(tag.getLink());
}
} catch (ParserException e) {
e.printStackTrace();
}
return downloadUrl;
}运行结果:

愉快地下载电影:
最后把完整源码献上:
public class HtmlParserDemo {
/**
* 获取电影的下载地址
*/
public static String[] getMovieDownloadUrl(String movieIntroUrl) {
String[] downloadUrl = null;
try {
Parser parser = new Parser(movieIntroUrl);
NodeList nodeList = parser.extractAllNodesThatMatch(new LinkStringFilter("ftp"));
for (int i = 0; i < nodeList.size(); i++) {
LinkTag tag = (LinkTag) nodeList.elementAt(i);
System.out.println(tag.getLink());
}
} catch (ParserException e) {
e.printStackTrace();
}
return downloadUrl;
}
/**
*
* 获取每页25个电影的介绍地址
*/
public static List getAllMovieUrlFromOnePageList(String pageListUrl) {
List<String> allMoveUrl = new ArrayList<String>();
try {
Parser parser = new Parser(pageListUrl);
NodeList nodeList = parser.extractAllNodesThatMatch(new HasAttributeFilter("class", "ulink"));
for (int i = 0; i < nodeList.size(); i++) {
LinkTag tag = (LinkTag) nodeList.elementAt(i);
// System.out.println(tag.getLink());
allMoveUrl.add("http://www.ygdy8.net" + tag.getLink());
}
} catch (ParserException e) {
e.printStackTrace();
}
return allMoveUrl;
}
/**
* 从http://www.ygdy8.net/html/gndy/dyzz/index.html网页里获取157个电影分页的地址
*
* @return List集合存储157个分页地址
*/
public static List getAllPageList() {
List<String> pageList = new ArrayList();
try {
Parser parser = new Parser("http://www.ygdy8.net/html/gndy/dyzz/index.html");
// match匹配带option属性的标签
NodeList nodeList = parser.extractAllNodesThatMatch(new TagNameFilter("option"))
.extractAllNodesThatMatch(new HasAttributeFilter("value"));
for (int i = 0; i < nodeList.size(); i++) {
OptionTag tag = (OptionTag) nodeList.elementAt(i);
String link = tag.getAttribute("value");
// 筛选既带有option属性又含有list的标签
if (link.contains("list")) {
// System.out.println(i+",,,"+link);
pageList.add("http://www.ygdy8.net/html/gndy/dyzz/" + link);
}
}
} catch (ParserException e) {
e.printStackTrace();
}
return pageList;
}
/**
* 三个方法联系在一起执行,输出抓取的下载地址
*/
public static void getAllMovie() {
// 获取所有的的电影列表页,共有157页
List pageList = getAllPageList();
for (Iterator iterator = pageList.iterator(); iterator.hasNext();) {
String oneMoveListUrl = (String) iterator.next();
// 获取一个电影列表页里面的25个电影页面的地址
List moveListFromOnePage = getAllMovieUrlFromOnePageList(oneMoveListUrl);
try {
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("下载地址.txt")));
String downloadUrl[] = new String[moveListFromOnePage.size()];
for (Iterator iterator2 = moveListFromOnePage.iterator(); iterator2.hasNext();) {
String movieIntroUrl = (String) iterator2.next();
// 获取一个电影的下载地址(ftp地址)
downloadUrl = getMovieDownloadUrl(movieIntroUrl);
bw.write(downloadUrl + "\n");
bw.flush();
}
bw.close();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
public static void main(String[] args) {
getAllMovie();
}
}














 6964
6964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









