







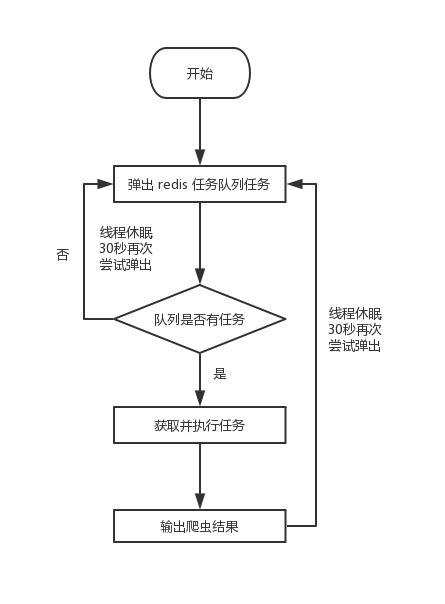
流程图
实现概念
- 基于 redis 良好的特性
- 爬虫脚本的 模板化
- 爬虫脚本监听 redis,实现爬虫自动化
该方案的优点
- 爬虫脚本模板化,复用性高
- 按自定义任务进行爬取,且可以控制任务粒度
- 爬虫脚本自动监听 redis,爬虫自动加入任务执行,不需要人为修改
- 如果有 redis 可视化页面,添加任务信息会很便利
了解相关概念
为什么选择 redis
简单的说,因为它的两个特性,快 和 单线程,由于 redis 的数据保存在内存中,获取数据所需的时间会很少,基本上是 个位数的毫秒级别,正因为它很快,所以它有资本使用 单线程,简单地说,就是多台服务器同时去 redis 里面拿数据,他们是需要排队的,如下如,命令1 没有执行完成,redis 是不会执行命令2的
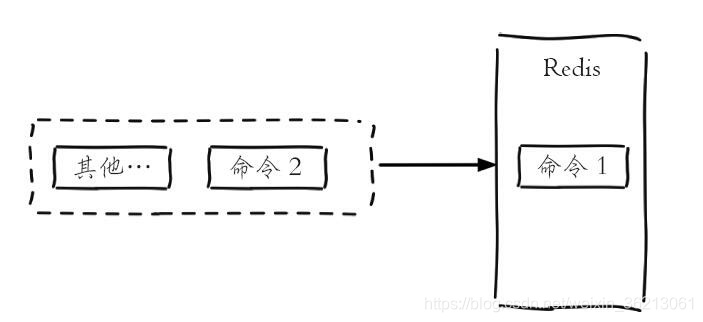
再借助 redis 的 列表 数据结构(可以当做 栈 或 队列使用),就可以实现服务器之间不会出现竞争任务的情况,每一个服务器只会领走一个任务,我们还可以通过 对列表的不同操作,改变任务执行策略,是先执行新添加的任务,还是耽搁最久的任务,以下就是列表,使用 push 从列表添加数据(任务),使用 pop 从列表中取出数据
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3711
3711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









