







 本文深入探讨了小米小爱同学在全双工连续对话中的关键技术,包括回声消除、拒识、多轮对话和节奏控制。拒识功能是关键,通过策略拒识、语义拒识和多模态拒识逐步优化,以减少无效人声的干扰。此外,文章还介绍了语义判不停的技术,确保用户指令完整接收。小爱同学的全双工技术已在音乐场景等得到广泛应用,并不断扩展到更多领域。
本文深入探讨了小米小爱同学在全双工连续对话中的关键技术,包括回声消除、拒识、多轮对话和节奏控制。拒识功能是关键,通过策略拒识、语义拒识和多模态拒识逐步优化,以减少无效人声的干扰。此外,文章还介绍了语义判不停的技术,确保用户指令完整接收。小爱同学的全双工技术已在音乐场景等得到广泛应用,并不断扩展到更多领域。
以下文章来源于:数据实战派
原文链接:请点击
文章仅用于学习交流,如有侵权请联系删除
本文来自PaperWeekly和biendata组织的企业AI技术实战讲座。作者为小米人工智能部的崔世起,崔老师以著名的“小爱同学”为实例,详细介绍了全双工关键技术及其应用。
内容主要分为四部分:
- 什么是全双工连续对话,针对全双工交互中涉及到的关键技术进行介绍。
- 针对拒识和判不停两部分工作,介绍一下小米的实践。
- 当前工作的进展与展望。
- 按照惯例,我们依然为大家整理了直播中问答环节的精华内容

作者简介:崔世起,就职于小米人工智能部,目前主要负责小爱全双工项目的技术研发。

一、什么是全双工连续对话

全双工是通信领域的术语,指在通话的时候数据可以在两个方向同时传输。举个简单的例子可以解释全双工,手机通信就是全双工,而用对讲机通信是半双工。
全双工连续对话有三个特点:第一是一次唤醒连续对话,以小爱智能音箱为例,用户唤醒小爱之后,一段时间之内可以对小爱连续地发出指令,不需要每次重新唤醒。
第二是边听边说,随时打断。边听边说是指小爱音箱在说话的同时可以听用户的指令。如果用户对小爱音箱的播报不感兴趣可以随时插话打断,这样交互效率会更高。第三是在连续对话的场景下,人一边思考一边说话,产生一些不自然的停顿会更接近于人与人之间真实的表达方式。在多轮对话,也容易省略掉一些内容。
下面有一段演示,是一段用户唤醒小爱之后的对话,其中有一些指令,也有人在闲聊,小爱可以智能地把闲聊的声音忽略掉。
人:小爱同学,今天心情好不好?
本来我今天心情不好的,你来找我聊天,瞬间心情变好了。
人:打开书房灯。
设备已经开了。
人:亮度调暗一点。
调暗了。
人:放一首《燕归巢》。
一首《燕归巢》送给你,遇到他道一声别来无恙。画外闲聊音:我们自己聊天的声音是能够接收的。人:它挺聪明的,应该不会乱搭话。人:收藏这首歌。
已添加到我的收藏。
人:声音调大一点,换一首许嵩版的。
许嵩好听的《燕归巢》送给你。
人:现在几点了?
现在是下午1点7分。
人:都1点了,我去点外卖了.
你帮我也点一个。
人:好,退出。
这段对话主要想要给大家演示,用户唤醒小爱之后,可以连续地发出不同的指令,包括闲聊、听音乐、调整音量和问时间,并且小爱能识别出周围人聊天的声音,不做出响应。

下面就介绍一下小爱在全双工上落地的设备。我们内部把全双工分为两种模式:
第一类是场景式的全双工,是针对全领域而言的。场景式的全双工,只会响应一个或者多个领域的指令,比如听音乐的场景,音箱会响应听歌、选歌、调音量的指令;看视频的场景,设备可以在用户看视频的过程中,允许连续地搜片、选片、快进。目前小爱触屏音箱支持听音乐、控制设备等场景,小米电视支持看视频的场景。
第二类全双工,我们称之为全领域。这种方式对用户的请求没有任何领域限制,是全领域的,同时允许用户与小爱聊天和问答,场景式的模式,实现起来会相对容易一点,而全领域对拒识要求比较严格。
二、全双工关键技术
接下来介绍全双工的一些关键技术。
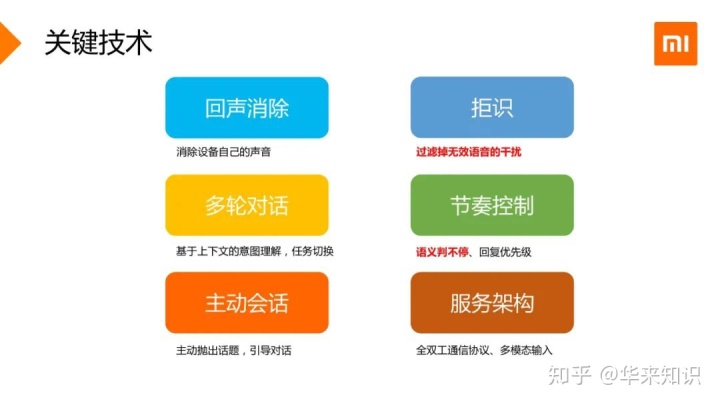
首先是回声消除,由于小爱音箱在说话的时候会把自己的声音也录音,所以需要消除音箱自己的声音。这部分主要是通过前端声学算法解决,而回声消除也是全双工非常必要的部分。
第二是拒识,小爱音箱会一直开着麦克风,难免录入很多背景噪音,比如周围人的说话声,拒识的功能就是把无效的语音过滤掉。
第三是多轮对话,连续的对话模式,对基于上下文的意图理解有更高的要求,用户可以在多轮交互中让小爱完成更复杂的任务,并允许任务的切换。
第四是节奏控制,用户会以更加自然的方式对话小爱音箱,就会存在着停顿、节奏的变化,这时需要通过判不停更加智能地适应用户的说话节奏。当用户连续发出多条指令时,也需要对每一条指令的回复进行优先级控制。
第五是主动对话,全双工的场景下,不仅是用户问小爱,小爱还可以主动地抛出话题,引导对话。
最后对服务架构也有比较高的挑战,由于小爱音箱会实时连续不断地把语音传上来,对系统的效率有很高的要求,需要有高效的通信协议,同时能支持多模态的输入和异步的处理。
总结一下,全双工交互的实现,涉及到的技术链条相对比较长,从声学、语音到NLP,涉及到算法与架构,需要各个模块的配合,才能达到相对比较好的体验。下面我会对中间的两部分内容:拒识和节奏控制中的语义判不停,分享一下我们在这方面做的一些实践、一些思考,希望能对大家有一些启发。
1.拒识
拒识功能就是识别出哪些话是同小爱说的,哪些不是同小爱说的。为什么拒识很重要呢?有统计数据表明,在全双工场景下无效人声占比大约在15%~30%之间,这个比例非常高,如果对所有的请求都响应,会对用户产生很大的干扰,导致全双工的可用性非常差。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









