






实为吾之愚见,望诸君酌之!闻过则喜,与君共勉
测试数据
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL,
`dept_no` char(4) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`),
KEY
`from_date` (`from_date`),
CONSTRAINT `dept_emp_ibfk_1` FOREIGN KEY (`emp_no`) REFERENCES
`employees` (`emp_no`) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=latin1
CREATE TABLE `departments` (
`dept_no` char(4) NOT NULL,
`dept_name` varchar(40) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
mysql> select count(1) from departments;
+----------+
| count(1) |
+----------+
|
9 |
+----------+
1 row in set (0.00 sec)
mysql> select count(1) from dept_emp;
+----------+
| count(1) |
+----------+
|
331603 |
+----------+
1 row in set (0.08 sec)
其中dept_emp有331603行记录,departments有9行数据
事例查询
select e.to_date,d.dept_name from dept_emp
e,departments d where e.dept_no=d.dept_no;
这是一个两表join的query,对应条件是where e.dept_no=d.dept_no,主要找出表dept_emp和departments中,满足dept_no相等的记录,然后展示出e.to_date,d.dept_name列其中dept_emp有331603行记录,departments有9行数据
执行计划对比
关闭block_nested_loop
打开block_nested_loop

打开batched_key_access
Nested-Loop事例
Nested-Loop Join
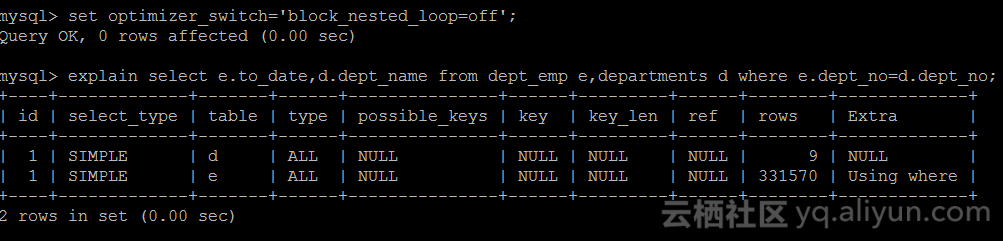
关闭设置optimizer_switch的block_nested_loop为off,然后查看查询的执行计划
从上图可知,执行计划对departments是全表扫描(9行数据),对dept_emp也是全表扫描(331570行数据),当使用Nested-Loop Join算法的时候,先逐行的读取departments表(此处是全表扫描,仅限于该sql),针对departments的每一行数据,都对表dept_emp的每一行记录进行匹配(此处是全表扫描,仅限于该sql)满足条件的行(where e.dept_no=d.dept_no),wiki的伪代码如下:
For each tuple r in R do
For each tuple s in S do
If r and s satisfy the join condition
Then output the tuple
过程概括如下图:
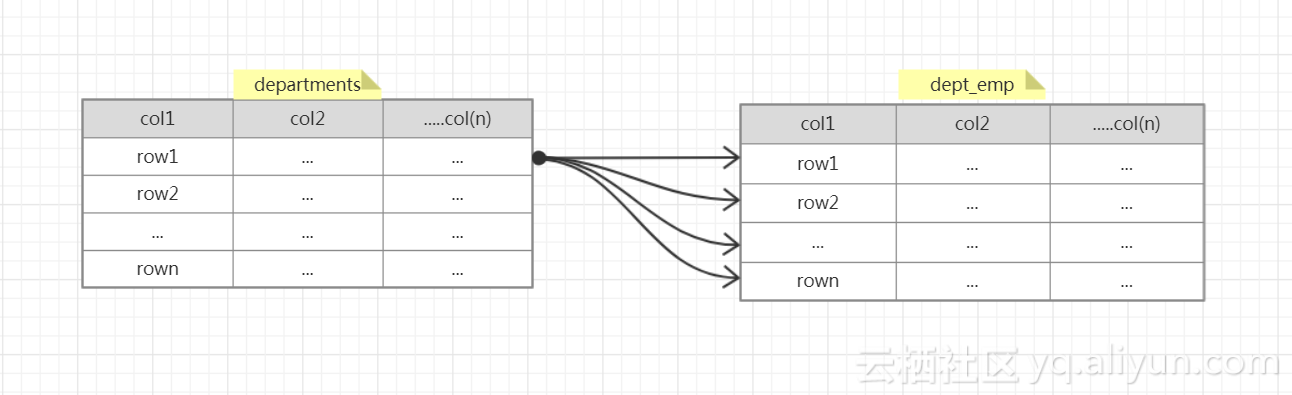
上图所示,departments的row1要和dept_emp每一行做条件匹配,查找符合条件的行,反复循环,直至departments的记录扫描完成(最后一条记录rown与dept_emp的每一行都进行了条件匹配)
Block_nested_loop
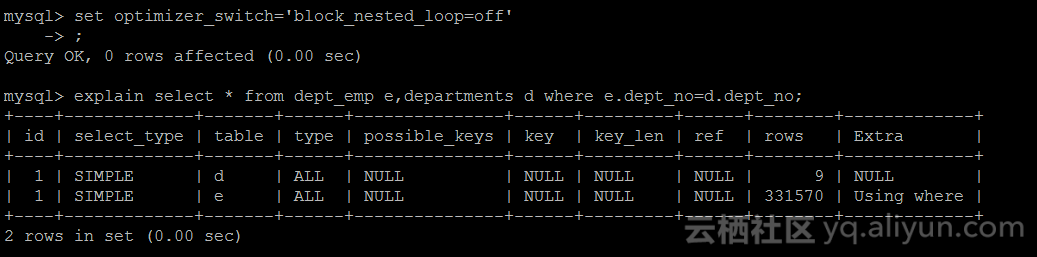
先打开设置optimizer_switch的block_nested_loop为on,然后查看查询的执行计划
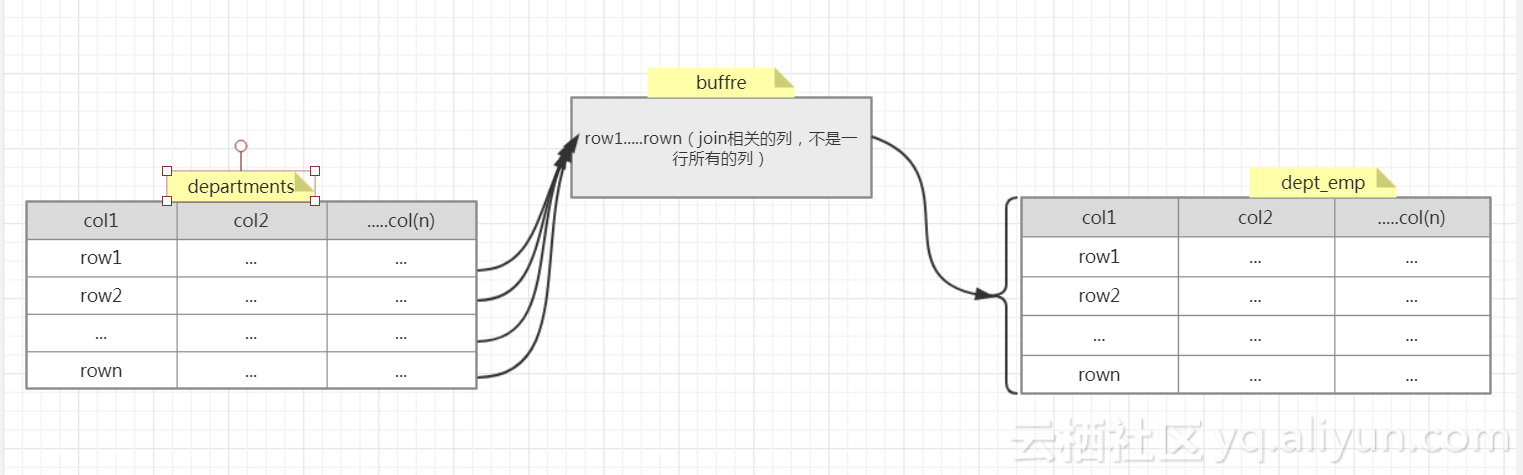
从上图可知,执行计划对departments是全表扫描(9行数据),对dept_emp也是全表扫描(331570行数据),但是extra列多了一部分” Using join buffer (Block Nested Loop)”,当使用Block
Nested-Loop Join算法的时候,先逐行的读取departments表(此处是全表扫描,仅限于该sql),然后把读取的数据,存储到join buffer里(如果join buffer足够大,就可以一次全部存储departments所需要的join对象了,如果join buffer太小,一次只可以缓存departments的一部分join对象的话,就需要分多次进行缓存departments的join对象),针对join buffer中缓存的数据(注意之前的一次缓存以及多次缓存),批量(不需要与Nested-Loop Join一样,一条条的比较了,可以多条比较了)的对表dept_emp的每一行记录进行匹配(此处是全表扫描,仅限于该sql)满足条件的行(where e.dept_no=d.dept_no),伪代码可以写成(参考的wiki):
For each tuple r in R do
store used columns from R in join buffer
For each tuple s in S do
If r and s satisfy the join condition
Then output the tuple
过程概括如下图:
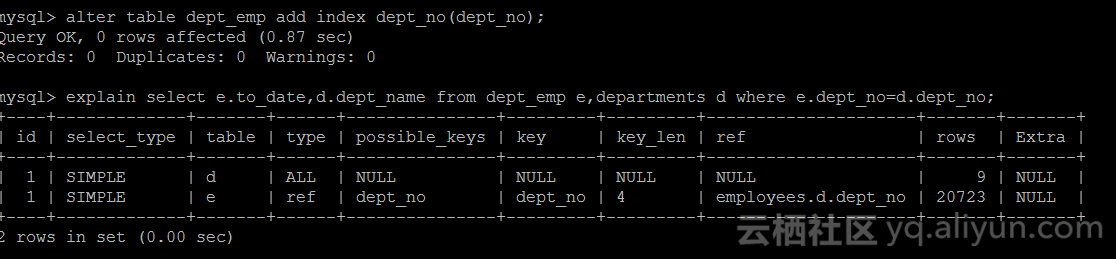
当为dept_emp表的列dept_no添加一个索引的时候(二级索引,已经有主键索引),再观察执行计划:


Join type从all变成了ref,可以理解为对dept_emp执行join的时候,使用索引进行匹配(对应之前的全表扫描),这里预估的行数是20723rows,比之前的331570rows少了很多(全表扫描),执行计划从全表扫描和ref(join type)中,选择了
ref,对比之前的block_nested_loop,过程变化如下:
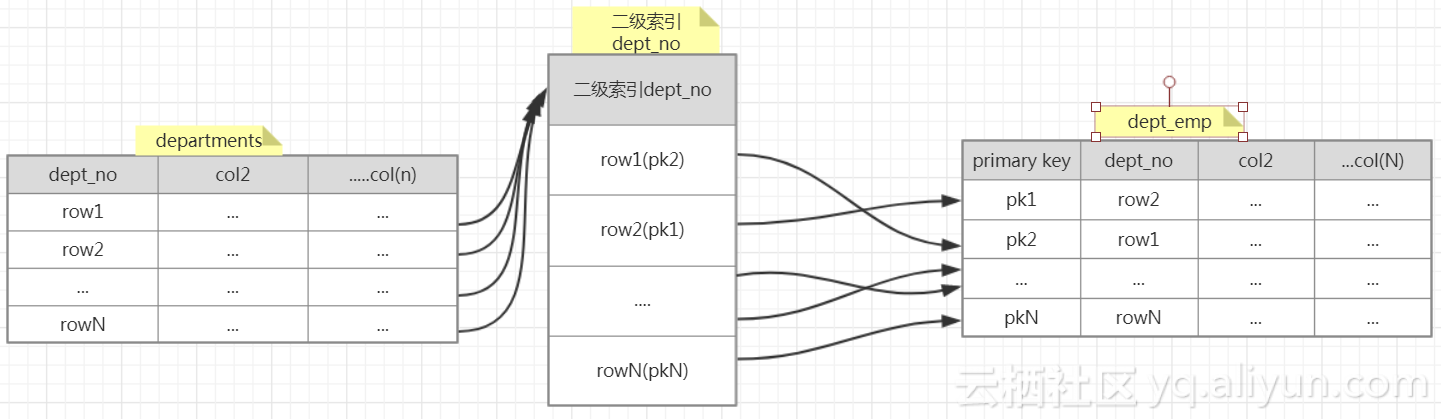
由于dept_emp下的dept_no是二级索引,查询中又查询了e.to_date(单单从二级索引里获取不到数据),于是需要通过索引,查询表里面对应的e.to_date的值,这是如上图可知,访问时随机的(图例的表现方式是row1对应pk2,row2对应pk1等等),可能会产生随机io,如果不查询e.to_date,则不需要再去表里查询了,同时Extra会显示Using index,如下:

Batched_key_access
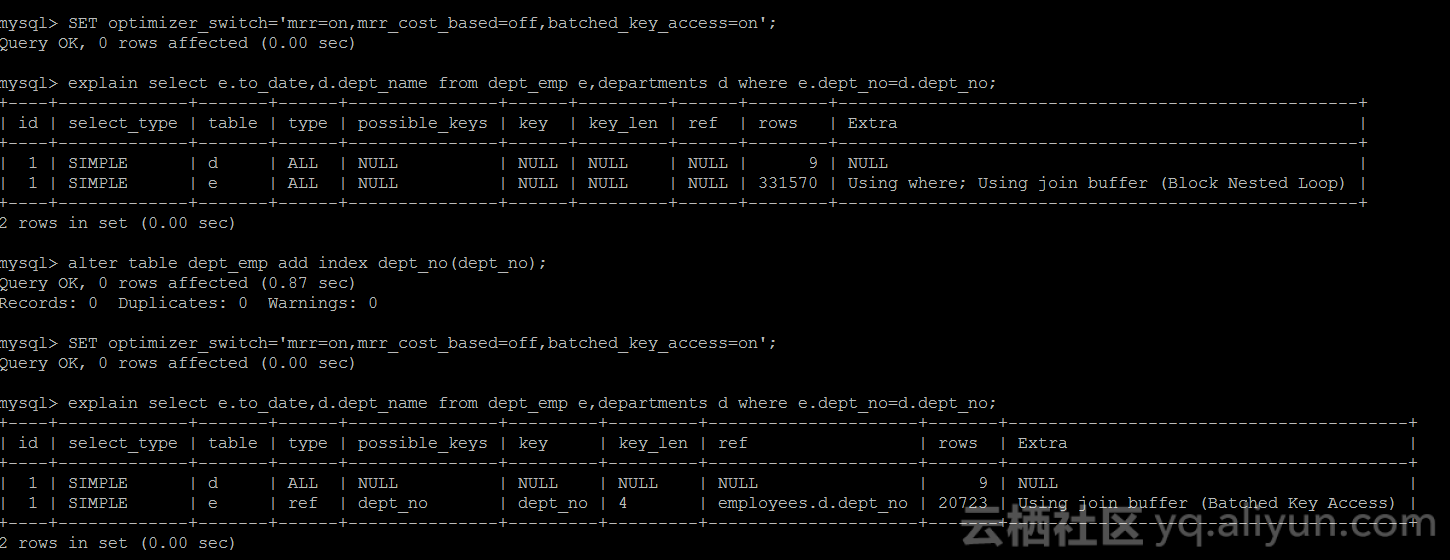
在Block_nested_loop最后部分,使用二级索引查询的时候,出现了一个现象:当获取的数据二级索引无法满足时,需要去查询原始的数据表来确定数据,查询数据是通过主键去查的,会出现不是按照主键顺序查的情况,如果有办法把这些无序的主键查询转换成有序的去查询表的数据(聚簇索引),会节省很多的时间,mysql提供了Batched_key_access算法来实现这个需求,复现如下:
对比之前的Block_nested_loop(有索引和没有索引两部分),上面加索引后,开启了mrr,batched_key_access,同时关闭了mrr_cost_based,这个时候Extra列出现了Using join buffer (Batched Key Access),使用Batched_key_access的过程如下:
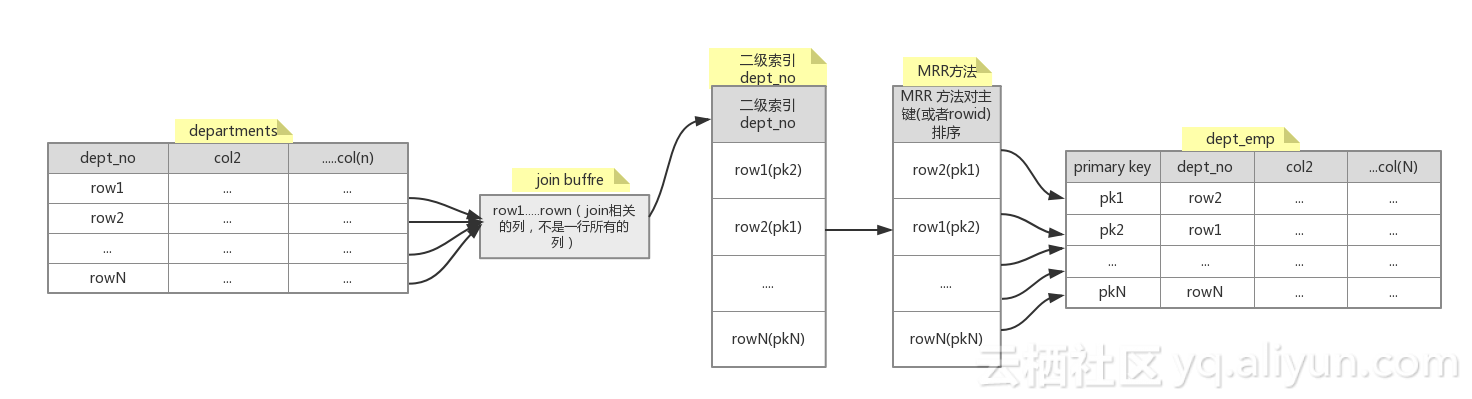
上图看,join buffer会缓存departments相关的join列,Batched_key_access算法会使用dept_no二级索引去查找,由于是无序的,查找前把这些key(可以大概理解为主键信息+join buffer里行的标识信息)的信息反馈给mrr 去,mrr会按照主键(没有主键使用row id)排序,然后顺序的去dept_emp里去查找信息,并发信息再次反馈给Batched_key_access算法去和join buffer里的row进行比较















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









