






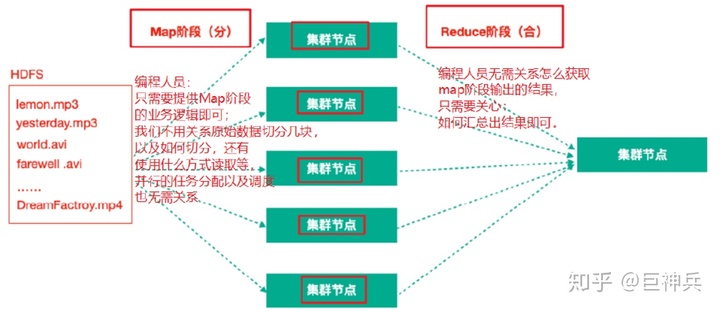
MapReduce思想
MapReduce任务过程分为两个处理阶段:
Map阶段:Map阶段的主要作用是"分",即把复杂的任务分解为若干个"简单的任务"来并行处理。Map阶段的这些任务可以并行计算,彼此间没有依赖关系。
Reduce阶段:Reduce阶段的主要作用是"合",即对map阶段的结果进行全局汇总。
MapReduce编程规范及示例编写
MapReduce的编程结构
Mapper类
- 用户自定义一个Mapper类,该类要继承Hadoop的Mapper类;
- Mapper的输入数据是键值对的形式(类型可以自定义);
- Map阶段的业务逻辑定义在map()方法中;
- Mapper的输出数据是键值对的形式(类型可以自定义)。
注意:map()方法是接收到一行文本就调用一次
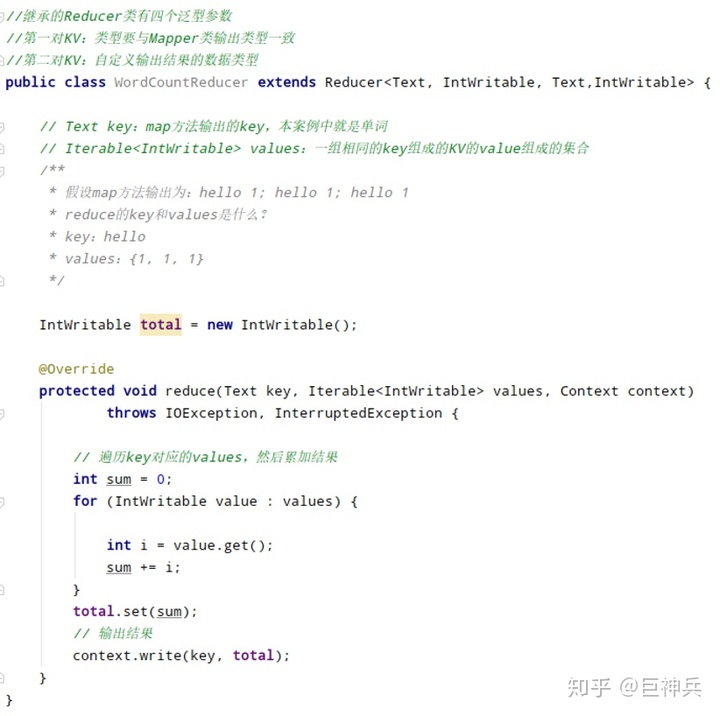
Reducer类
- 用户自定义Reducer类,该类要继承Hadoop的Reducer类;
- Reducer的输入数据类型要与Mapper类的输出数据类型相同;
- Reducer的业务逻辑写在reduce()方法中;
- Reduce()方法是当接收相同key的一组键值对就执行一次。
Driver阶段
创建提交YARN集群运行的Job对象,其中封装了MapReduce程序运行所需的相关参数的输入数据路径,输出数据路径等。也相当于是一个YARN集群的客户端,主要作用就是提交我们MapReduce程序运行。
WordCount代码实现
需求
在给定的文本文件中统计输出每个单词出现的次数
输入数据:wc.txt
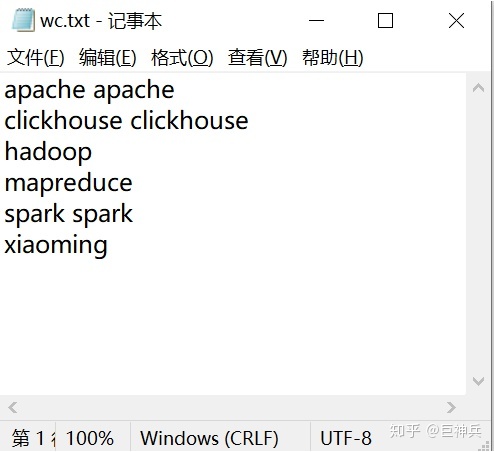
输出:

具体步骤
按照MapReduce编程规范,分别编写Mapper,Reducer,Driver
新建maven工程
导入相关依赖
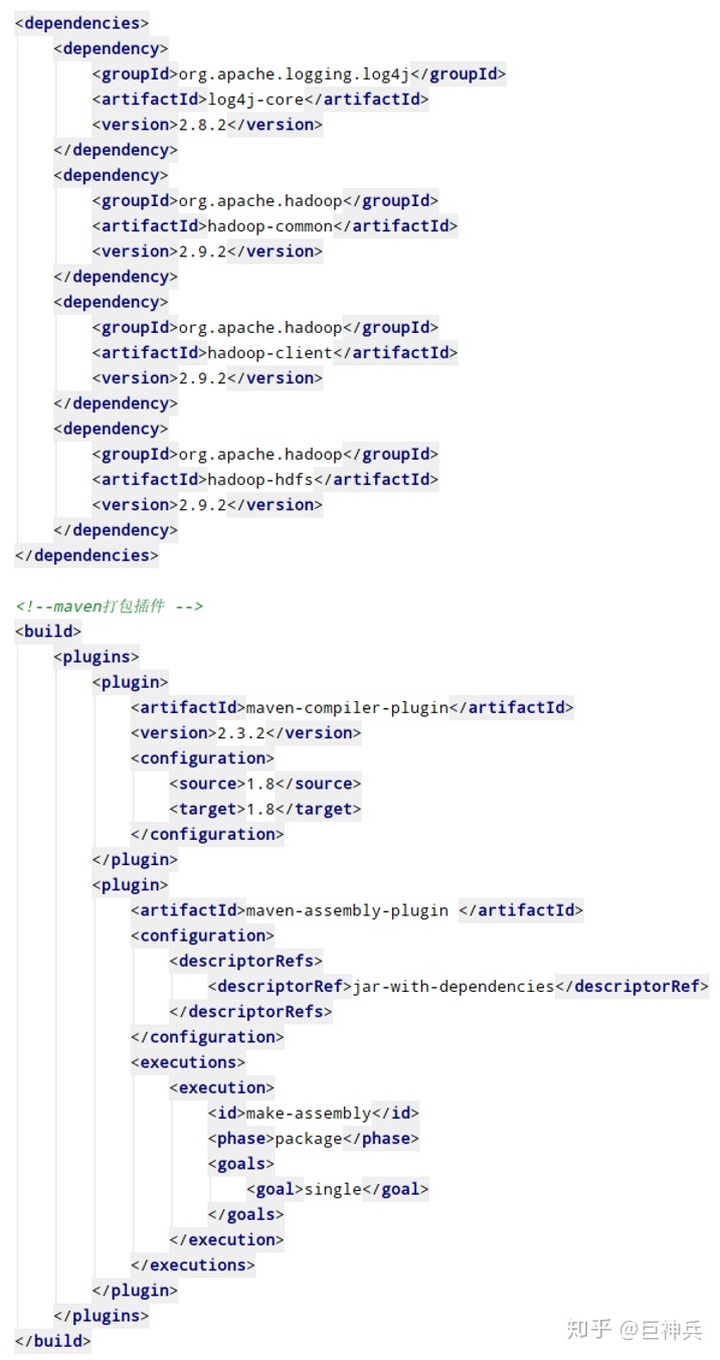
添加log4j.properties配置文件

整体思路梳理
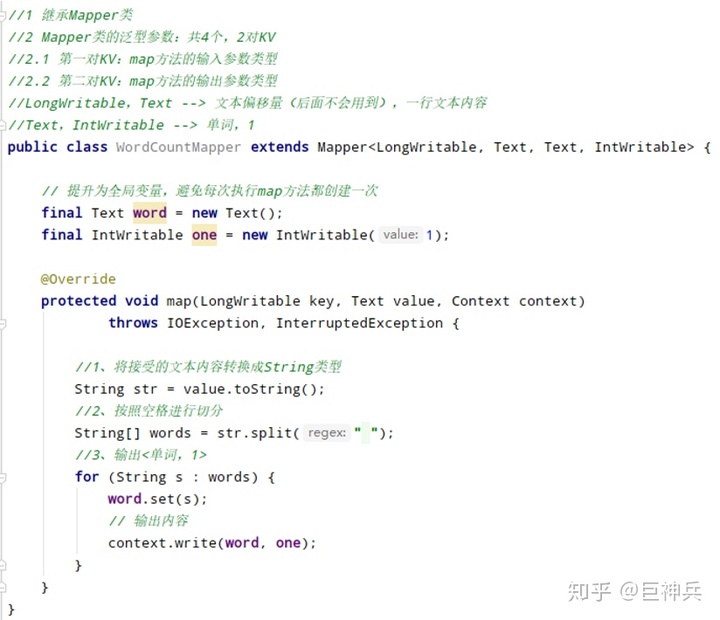
Map阶段:
- map()方法中把传入的数据转为String类型;
- 根据空格切分出单词;
- 输出<单词,1>
Reduce阶段:
- 汇总各个单词的个数,遍历value数据进行累加;
- 输出key的总数
Driver阶段:
- 获取配置文件对象,获取job对象;
- 指定程序jar的本地路径;
- 指定Mapper/Reducer类;
- 指定Mapper输出的KV数据类型;
- 指定最终输出的KV数据类型;
- 指定job处理的原始数据路径;
- 指定job输出结果路径;
- 提交作业。
编写Mapper类
编写Reducer类
编写Driver驱动类

Yarn集群运行任务
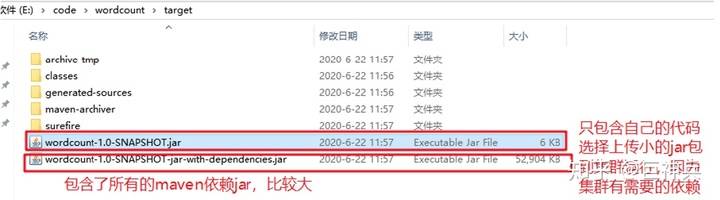
把程序达成jar包,改名为wc.jar,上传到Hadoop集群
选择正确的jar包
准备原始数据文件,上传到HDFS,不是本地Linux系统中,因为跨节点运行无法获得其他节点上的数据,但是HDFS数据是各个节点共享的。

启动Hadoop集群
使用Hadoop命令提交任务运行

/wcinput是原始数据文件所在的路径;
/wcoutput是运行结果存放的路径。















 3612
3612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









