







1、MapReduce思想
MapReduce思想在生活中处处可见。我们或多或少都曾接触过这种思想。MapReduce的思想核心是分而治之,充分利用了并行处理的优势。即使是发布过论文实现分布式计算的谷歌也只是实现了这种思想,而不是自己原创。
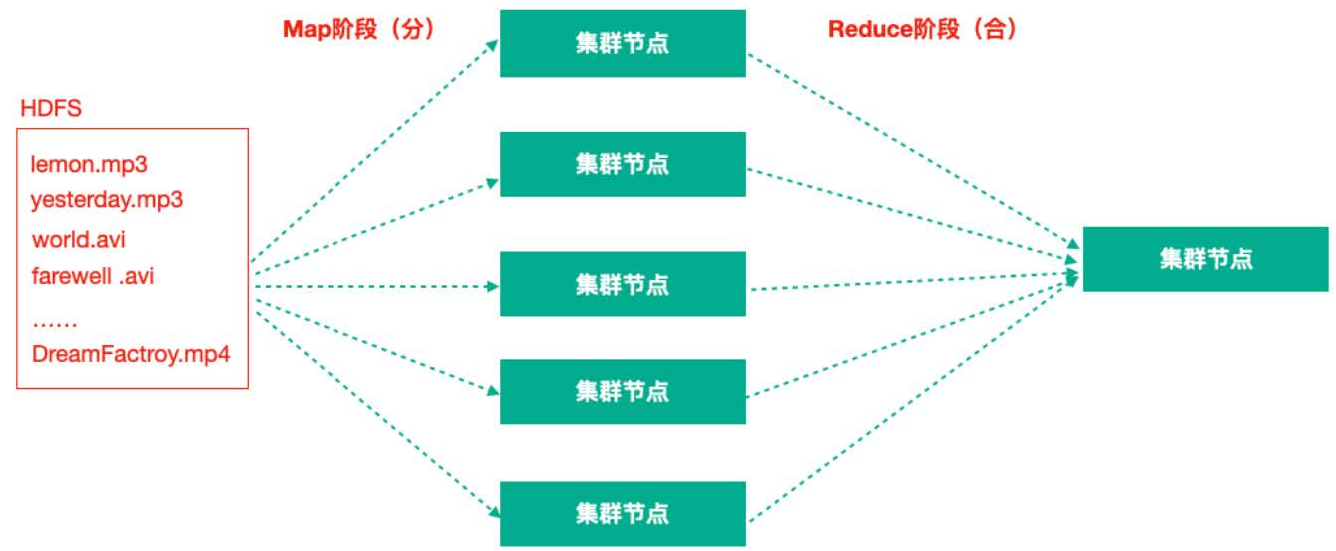
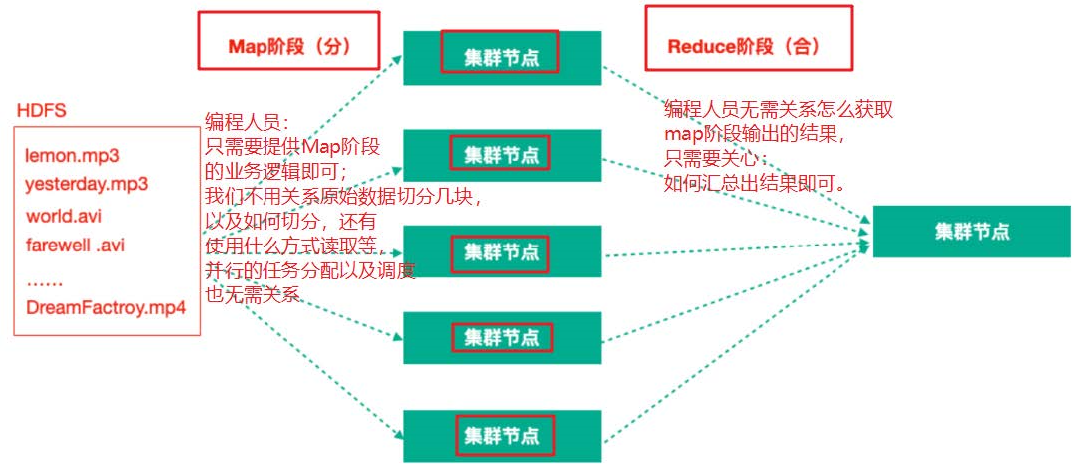
MapReduce任务过程是分为两个处理阶段:
- Map阶段:Map阶段的主要作用是“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。Map阶段的这些任务可以并行计算,彼此间没有依赖关系。
- Reduce阶段:Reduce阶段的主要作用是“合”,即对map阶段的结果进行全局汇总。
再次理解MapReduce的思想
2、官方WordCount案例源码解析
hadoop为我们提供了一个Wordcount示例代码的jar包,我们接下来对其源码进行分析。
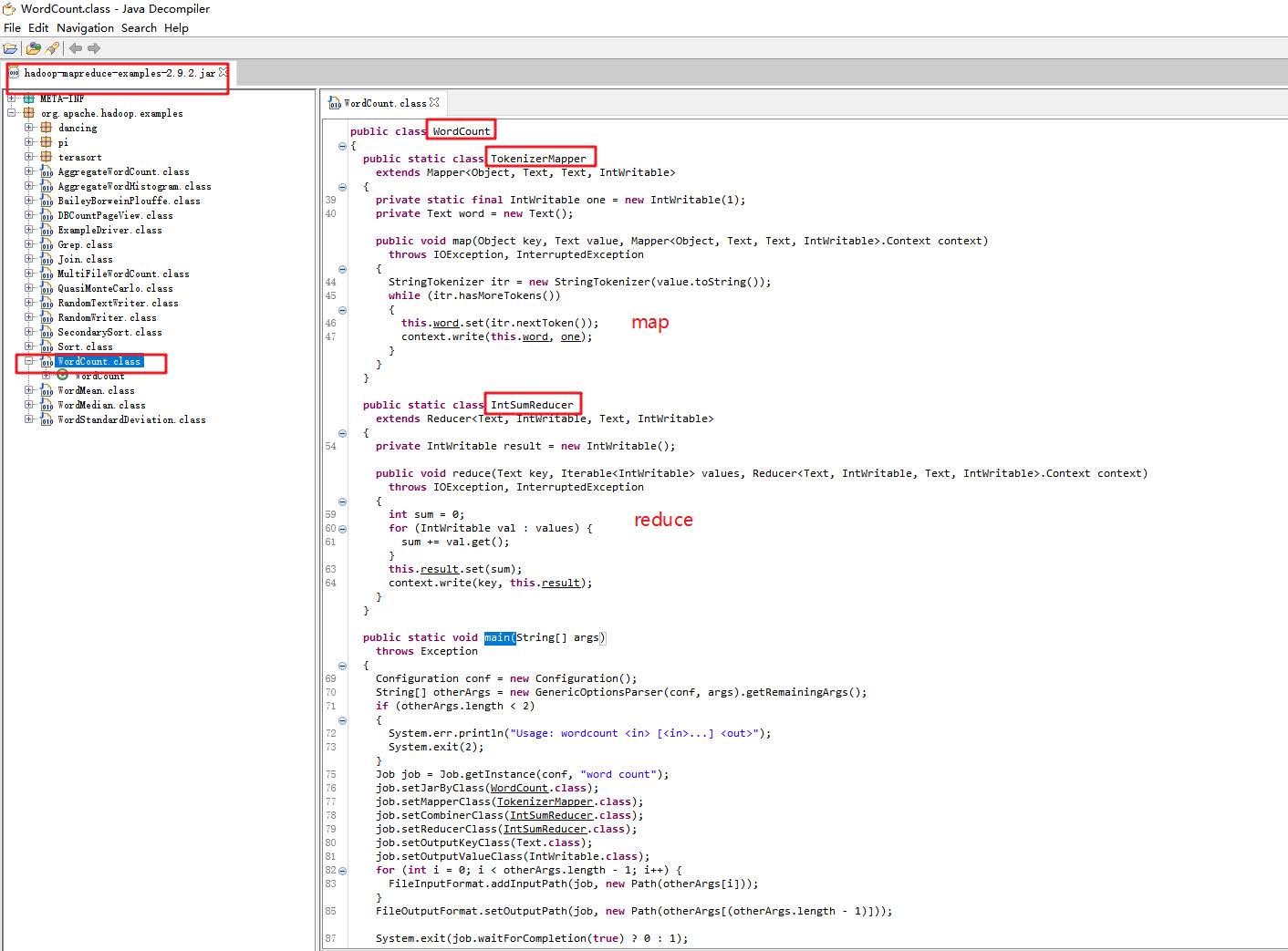

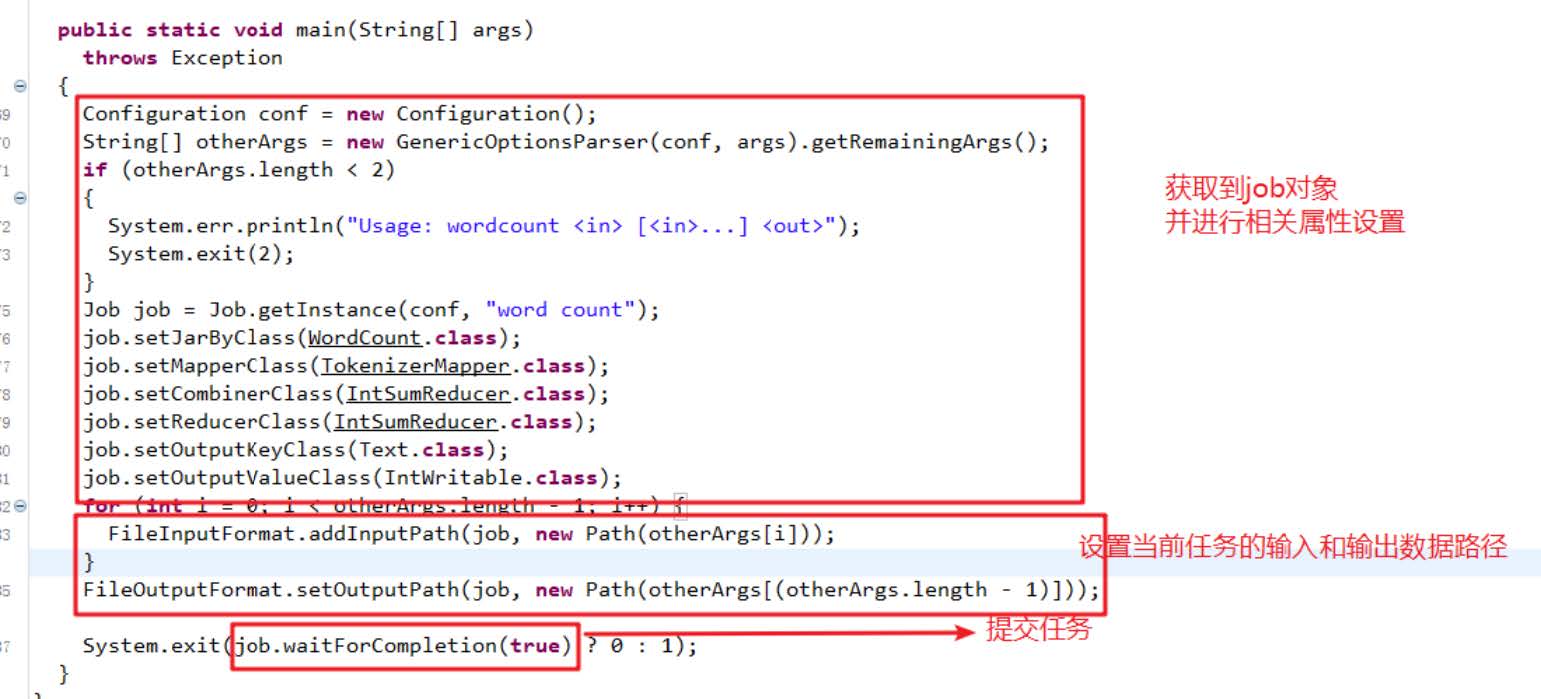
经过查看分析官方WordCount案例源码我们发现一个统计单词数量的MapReduce程序的代码由三个部分组成,
- Mapper类
- Reducer类
- 运行作业的代码(Driver)
Mapper类继承了org.apache.hadoop.mapreduce.Mapper类重写了其中的map方法,Reducer类继承了org.apache.hadoop.mapreduce.Reducer类重写了其中的reduce方法。
- 重写的Map方法作用:map方法其中的逻辑就是用户希望mr程序map阶段如何处理的逻辑;
- 重写的Reduce方法作用:reduce方法其中的逻辑是用户希望mr程序reduce阶段如何处理的逻辑;
3、Hadoop序列化
为什么进行序列化?
序列化主要是我们通过网络通信传输数据时或者把对象持久化到文件,需要把对象序列化成二进制的结构。
观察源码时发现自定义Mapper类与自定义Reducer类都有泛型类型约束,比如自定义Mapper有四个形参类型,但是形参类型并不是常见的java基本类型。
为什么Hadoop要选择建立自己的序列化格式而不使用java自带serializable?
- 序列化在分布式程序中非常重要,在Hadoop中,集群中多个节点的进程间的通信是通过RPC(远程过程调用:Remote Procedure Call)实现;RPC将消息序列化成二进制流发送到远程节点,远程节点再将接收到的二进制数据反序列化为原始的消息,因此RPC往往追求如下特点:
- 紧凑:数据更紧凑,能充分利用网络带宽资源
- 快速:序列化和反序列化的性能开销更低
- Hadoop使用的是自己的序列化格式Writable,它比java的序列化serialization更紧凑速度更快。一个对象使用Serializable序列化后,会携带很多额外信息比如校验信息,Header,继承体系等。
Java基本类型与Hadoop常用序列化类型
| Java基本类型 | Hadoop Writable类型 |
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
















 116
116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











