






步骤1:索引删除和更新步骤2:先说没有删除前的情形步骤3:删除索引步骤4:更多删除步骤5:更新索引
步骤 1 : 索引删除和更新
索引建立好了之后,还是需要维护的,比如新增,删除和维护。 新增就是建立索引的过程,这里就不表了,本教材主要讲索引的删除和更新。
索引里的数据,其实就是一个一个的Document 对象,那么本文就是介绍如何删除和更新这些Documen对象。步骤 2 : 先说没有删除前的情形
直接使用14万条数据 里的代码,不过使用不一样的查询语句。
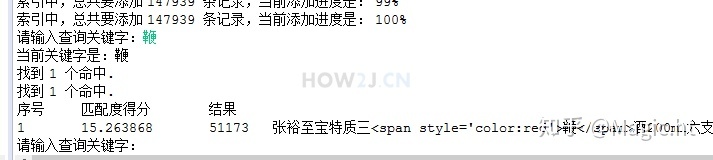
如图所示,通过关键字 “鞭" 可以查询到一条id是51173的数据。
package com.how2java;import java.io.IOException;import java.io.StringReader;import java.util.List;import java.util.Scanner;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.TextField;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.IndexableField;import org.apache.lucene.index.Term;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.highlight.Highlighter;import org.apache.lucene.search.highlight.QueryScorer;import org.apache.lucene.search.highlight.SimpleHTMLFormatter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.RAMDirectory;import org.wltea.analyzer.lucene.IKAnalyzer;public class TestLucene {public static void main(String[] args) throws Exception {// 1. 准备中文分词器IKAnalyzer analyzer = new IKAnalyzer();// 2. 索引Directory index = createIndex(analyzer);// 3. 查询器Scanner s = new Scanner(System.in);while(true){System.out.print("请输入查询关键字:");String keyword = s.nextLine();System.out.println("当前关键字是:"+keyword);Query query = new QueryParser( "name", analyzer).parse(keyword);// 4. 搜索IndexReader reader = DirectoryReader.open(index);IndexSearcher searcher=new IndexSearcher(reader);int numberPerPage = 10;ScoreDoc[] hits = searcher.search(query, numberPerPage).scoreDocs;// 5. 显示查询结果showSearchResults(searcher, hits,query,analyzer);// 6. 关闭查询reader.close();}}private static void showSearchResults(IndexSearcher searcher, ScoreDoc[] hits, Query query, IKAnalyzer analyzer) throwsException {System.out.println("找到 " + hits.length + " 个命中.");SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));System.out.println("找到 " + hits.length + " 个命中.");System.out.println("序号t匹配度得分t结果");for (int i = 0; i < hits.length; ++i) {ScoreDoc scoreDoc= hits[i];int docId = scoreDoc.doc;Document d = searcher.doc(docId);List<IndexableField> fields= d.getFields();System.out.print((i + 1) );System.out.print("t" + scoreDoc.score);for (IndexableField f : fields) {if("name".equals(f.name())){TokenStream tokenStream = analyzer.tokenStream(f.name(), new StringReader(d.get(f.name())));String fieldContent = highlighter.getBestFragment(tokenStream, d.get(f.name()));System.out.print("t"+fieldContent);}else{System.out.print("t"+d.get(f.name()));}}System.out.println("<br>");}}private static Directory createIndex(IKAnalyzer analyzer) throws IOException {Directory index = new RAMDirectory();IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter writer = new IndexWriter(index, config);String fileName = "140k_products.txt";List<Product> products = ProductUtil.file2list(fileName);int total = products.size();int count = 0;int per = 0;int oldPer =0;for (Product p : products) {addDoc(writer, p);count++;per = count*100/total;if(per!=oldPer){oldPer = per;System.out.printf("索引中,总共要添加 %d 条记录,当前添加进度是: %d%% %n",total,per);}}writer.close();return index;}private static void addDoc(IndexWriter w, Product p) throws IOException {Document doc = new Document();doc.add(new TextField("id", String.valueOf(p.getId()), Field.Store.YES));doc.add(new TextField("name", p.getName(), Field.Store.YES));doc.add(new TextField("category", p.getCategory(), Field.Store.YES));doc.add(new TextField("price", String.valueOf(p.getPrice()), Field.Store.YES));doc.add(new TextField("place", p.getPlace(), Field.Store.YES));doc.add(new TextField("code", p.getCode(), Field.Store.YES));w.addDocument(doc);}}步骤 3 : 删除索引
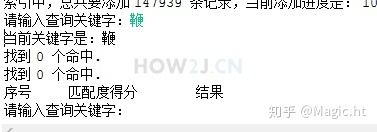
删除id=51173的Document之后,如图所示,再搜索鞭字,就查询不到结果了。
删除关键代码如下,通过 Term对象删除//删除id=51173的数据IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter indexWriter = new IndexWriter(index, config);indexWriter.deleteDocuments(new Term("id", "51173"));indexWriter.commit();indexWriter.close();
- 代码片段
- TestLucene.java
//删除id=51173的数据IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter indexWriter = new IndexWriter(index, config);indexWriter.deleteDocuments(new Term("id", "51173"));indexWriter.commit();indexWriter.close();package com.how2java;import java.io.IOException;import java.io.StringReader;import java.util.List;import java.util.Scanner;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.TextField;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.IndexableField;import org.apache.lucene.index.Term;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.highlight.Highlighter;import org.apache.lucene.search.highlight.QueryScorer;import org.apache.lucene.search.highlight.SimpleHTMLFormatter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.RAMDirectory;import org.wltea.analyzer.lucene.IKAnalyzer;public class TestLucene {public static void main(String[] args) throws Exception {// 1. 准备中文分词器IKAnalyzer analyzer = new IKAnalyzer();// 2. 索引Directory index = createIndex(analyzer);// 3. 查询器Scanner s = new Scanner(System.in);//删除id=51173的数据IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter indexWriter = new IndexWriter(index, config);indexWriter.deleteDocuments(new Term("id", "51173"));indexWriter.commit();indexWriter.close();while(true){System.out.print("请输入查询关键字:");String keyword = s.nextLine();System.out.println("当前关键字是:"+keyword);Query query = new QueryParser( "name", analyzer).parse(keyword);// 4. 搜索IndexReader reader = DirectoryReader.open(index);IndexSearcher searcher=new IndexSearcher(reader);int numberPerPage = 10;ScoreDoc[] hits = searcher.search(query, numberPerPage).scoreDocs;// 5. 显示查询结果showSearchResults(searcher, hits,query,analyzer);// 6. 关闭查询reader.close();}}private static void showSearchResults(IndexSearcher searcher, ScoreDoc[] hits, Query query, IKAnalyzer analyzer) throwsException {System.out.println("找到 " + hits.length + " 个命中.");SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));System.out.println("找到 " + hits.length + " 个命中.");System.out.println("序号t匹配度得分t结果");for (int i = 0; i < hits.length; ++i) {ScoreDoc scoreDoc= hits[i];int docId = scoreDoc.doc;Document d = searcher.doc(docId);List<IndexableField> fields= d.getFields();System.out.print((i + 1) );System.out.print("t" + scoreDoc.score);for (IndexableField f : fields) {if("name".equals(f.name())){TokenStream tokenStream = analyzer.tokenStream(f.name(), new StringReader(d.get(f.name())));String fieldContent = highlighter.getBestFragment(tokenStream, d.get(f.name()));System.out.print("t"+fieldContent);}else{System.out.print("t"+d.get(f.name()));}}System.out.println("<br>");}}private static Directory createIndex(IKAnalyzer analyzer) throws IOException {Directory index = new RAMDirectory();IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter writer = new IndexWriter(index, config);String fileName = "140k_products.txt";List<Product> products = ProductUtil.file2list(fileName);int total = products.size();int count = 0;int per = 0;int oldPer =0;for (Product p : products) {addDoc(writer, p);count++;per = count*100/total;if(per!=oldPer){oldPer = per;System.out.printf("索引中,总共要添加 %d 条记录,当前添加进度是: %d%% %n",total,per);}}writer.close();return index;}private static void addDoc(IndexWriter w, Product p) throws IOException {Document doc = new Document();doc.add(new TextField("id", String.valueOf(p.getId()), Field.Store.YES));doc.add(new TextField("name", p.getName(), Field.Store.YES));doc.add(new TextField("category", p.getCategory(), Field.Store.YES));doc.add(new TextField("price", String.valueOf(p.getPrice()), Field.Store.YES));doc.add(new TextField("place", p.getPlace(), Field.Store.YES));doc.add(new TextField("code", p.getCode(), Field.Store.YES));w.addDocument(doc);}}步骤 4 : 更多删除
还可以按照如下方法来删除索引,API 很明显,就不做代码示例了DeleteDocuments(Query query):根据Query条件来删除单个或多个DocumentDeleteDocuments(Query[] queries):根据Query条件来删除单个或多个DocumentDeleteDocuments(Term term):根据Term来删除单个或多个DocumentDeleteDocuments(Term[] terms):根据Term来删除单个或多个DocumentDeleteAll():删除所有的Document步骤 5 : 更新索引
如图所示,更新索引后,再用鞭查询,得到的结果是查出了更新之后的数据。 更新的关键代码:// 更新索引IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter indexWriter = new IndexWriter(index, config);Document doc = new Document();doc.add(new TextField("id", "51173", Field.Store.YES));doc.add(new TextField("name", "神鞭,鞭没了,神还在", Field.Store.YES));doc.add(new TextField("category", "道具", Field.Store.YES));doc.add(new TextField("price", "998", Field.Store.YES));doc.add(new TextField("place", "南海群岛", Field.Store.YES));doc.add(new TextField("code", "888888", Field.Store.YES));indexWriter.updateDocument(new Term("id", "51173"), doc );indexWriter.commit();indexWriter.close();

package com.how2java;import java.io.IOException;import java.io.StringReader;import java.util.List;import java.util.Scanner;import org.apache.lucene.analysis.TokenStream;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field;import org.apache.lucene.document.TextField;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.IndexableField;import org.apache.lucene.index.Term;import org.apache.lucene.queryparser.classic.QueryParser;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.highlight.Highlighter;import org.apache.lucene.search.highlight.QueryScorer;import org.apache.lucene.search.highlight.SimpleHTMLFormatter;import org.apache.lucene.store.Directory;import org.apache.lucene.store.RAMDirectory;import org.wltea.analyzer.lucene.IKAnalyzer;public class TestLucene {public static void main(String[] args) throws Exception {// 1. 准备中文分词器IKAnalyzer analyzer = new IKAnalyzer();// 2. 索引Directory index = createIndex(analyzer);// 3. 查询器// 更新索引IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter indexWriter = new IndexWriter(index, config);Document doc = new Document();doc.add(new TextField("id", "51173", Field.Store.YES));doc.add(new TextField("name", "神鞭,鞭没了,神还在", Field.Store.YES));doc.add(new TextField("category", "道具", Field.Store.YES));doc.add(new TextField("price", "998", Field.Store.YES));doc.add(new TextField("place", "南海群岛", Field.Store.YES));doc.add(new TextField("code", "888888", Field.Store.YES));indexWriter.updateDocument(new Term("id", "51173"), doc );indexWriter.commit();indexWriter.close();Scanner s = new Scanner(System.in);while(true){System.out.print("请输入查询关键字:");String keyword = s.nextLine();System.out.println("当前关键字是:"+keyword);Query query = new QueryParser( "name", analyzer).parse(keyword);// 4. 搜索IndexReader reader = DirectoryReader.open(index);IndexSearcher searcher=new IndexSearcher(reader);int numberPerPage = 10;ScoreDoc[] hits = searcher.search(query, numberPerPage).scoreDocs;// 5. 显示查询结果showSearchResults(searcher, hits,query,analyzer);// 6. 关闭查询reader.close();}}private static void showSearchResults(IndexSearcher searcher, ScoreDoc[] hits, Query query, IKAnalyzer analyzer) throwsException {System.out.println("找到 " + hits.length + " 个命中.");SimpleHTMLFormatter simpleHTMLFormatter = new SimpleHTMLFormatter("<span style='color:red'>", "</span>");Highlighter highlighter = new Highlighter(simpleHTMLFormatter, new QueryScorer(query));System.out.println("找到 " + hits.length + " 个命中.");System.out.println("序号t匹配度得分t结果");for (int i = 0; i < hits.length; ++i) {ScoreDoc scoreDoc= hits[i];int docId = scoreDoc.doc;Document d = searcher.doc(docId);List<IndexableField> fields= d.getFields();System.out.print((i + 1) );System.out.print("t" + scoreDoc.score);for (IndexableField f : fields) {if("name".equals(f.name())){TokenStream tokenStream = analyzer.tokenStream(f.name(), new StringReader(d.get(f.name())));String fieldContent = highlighter.getBestFragment(tokenStream, d.get(f.name()));System.out.print("t"+fieldContent);}else{System.out.print("t"+d.get(f.name()));}}System.out.println("<br>");}}private static Directory createIndex(IKAnalyzer analyzer) throws IOException {Directory index = new RAMDirectory();IndexWriterConfig config = new IndexWriterConfig(analyzer);IndexWriter writer = new IndexWriter(index, config);String fileName = "140k_products.txt";List<Product> products = ProductUtil.file2list(fileName);int total = products.size();int count = 0;int per = 0;int oldPer =0;for (Product p : products) {addDoc(writer, p);count++;per = count*100/total;if(per!=oldPer){oldPer = per;System.out.printf("索引中,总共要添加 %d 条记录,当前添加进度是: %d%% %n",total,per);}}writer.close();return index;}private static void addDoc(IndexWriter w, Product p) throws IOException {Document doc = new Document();doc.add(new TextField("id", String.valueOf(p.getId()), Field.Store.YES));doc.add(new TextField("name", p.getName(), Field.Store.YES));doc.add(new TextField("category", p.getCategory(), Field.Store.YES));doc.add(new TextField("price", String.valueOf(p.getPrice()), Field.Store.YES));doc.add(new TextField("place", p.getPlace(), Field.Store.YES));doc.add(new TextField("code", p.getCode(), Field.Store.YES));w.addDocument(doc);}}
更多内容,点击了解: https://how2j.cn/k/search-engine/search-engine-delete-update/1676.html















 2957
2957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









