






如题,两种数据分割方案哪种更好呢?关于这两种分割方案的基本概念请参照官方文档,我们这里只做方案性能测试:
1.创建表(这里有个无效的冗余索引user_id,历史因素这里先不管,两个表都有):
CREATE TABLE `rank_access_log_range` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` bigint(20) DEFAULT NULL,
`model_name` varchar(30) NOT NULL COMMENT '访问模块',
`channel` varchar(20) DEFAULT NULL COMMENT '渠道',
`channel_keywords` varchar(560) DEFAULT NULL COMMENT '渠道搜索关键字',
`refer_id` varchar(64) DEFAULT NULL,
`ip` varchar(128) DEFAULT NULL,
`begin_time` datetime NOT NULL COMMENT '开始运行时间',
`run_time` int(11) NOT NULL COMMENT '运行时间',
`http_status` smallint(6) DEFAULT NULL COMMENT 'http错误码',
`error_code` varchar(20) DEFAULT NULL COMMENT '业务错误码',
`error_msg` json DEFAULT NULL,
`request_params` varchar(500) DEFAULT NULL COMMENT '请求参数',
PRIMARY KEY (`id`,`begin_time`),
KEY `begin_time` (`begin_time`) USING BTREE,
KEY `rank_access_log_user_id_index` (`user_id`) USING BTREE,
KEY `ix_user_id_model_name` (`user_id`,`model_name`) USING BTREE,
KEY `ix_channel_refer_id` (`channel`,`refer_id`)
) ENGINE=InnoDB AUTO_INCREMENT=13320661 DEFAULT CHARSET=utf8 COMMENT='访问日志'
/*!50500 PARTITION BY RANGE COLUMNS(begin_time)
(PARTITION p201604 VALUES LESS THAN ('2016-05-01') ENGINE = InnoDB,
PARTITION p201605 VALUES LESS THAN ('2016-06-01') ENGINE = InnoDB,
PARTITION p201606 VALUES LESS THAN ('2016-07-01') ENGINE = InnoDB,
PARTITION p201607 VALUES LESS THAN ('2016-08-01') ENGINE = InnoDB,
PARTITION p201608 VALUES LESS THAN (MAXVALUE) ENGINE = InnoDB) */;
CREATE TABLE `rank_access_log` (
`id` bigint(20) NOT NULL,
`user_id` bigint(20) DEFAULT NULL,
`model_name` varchar(30) NOT NULL COMMENT '访问模块',
`channel` varchar(20) DEFAULT NULL COMMENT '渠道',
`channel_keywords` varchar(560) DEFAULT NULL COMMENT '渠道搜索关键字',
`refer_id` varchar(64) DEFAULT NULL COMMENT '如果来自BD活动,referId记录BD方代码;销售推广记录销售员id;用户推荐记录推荐人id',
`ip` varchar(128) DEFAULT NULL,
`begin_time` datetime NOT NULL COMMENT '开始运行时间',
`run_time` int(11) NOT NULL COMMENT '运行时间',
`http_status` smallint(6) DEFAULT NULL COMMENT 'http错误码',
`error_code` varchar(20) DEFAULT NULL COMMENT '业务错误码',
`error_msg` json DEFAULT NULL,
`request_params` varchar(500) DEFAULT NULL COMMENT '请求参数',
PRIMARY KEY (`id`),
KEY `begin_time` (`begin_time`) USING BTREE,
KEY `rank_access_log_user_id_index` (`user_id`) USING BTREE,
KEY `ix_user_id_model_name` (`user_id`,`model_name`) USING BTREE,
KEY `ix_channel_refer_id` (`channel`,`refer_id`) USING BTREE
) ENGINE=MRG_MyISAM DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC UNION=(`rank_access_log_2016_02`,`rank_access_log_2016_03`,`rank_access_log_2016_04`,`rank_access_log_2016_05`,`rank_access_log_2016_06`,`rank_access_log_2016_07`,`rank_access_log_2016_08`,`rank_access_log_2016_09`,`rank_access_log_2016_10`,`rank_access_log_2016_11`,`rank_access_log_2016_12`)
COMMENT='访问日志';
2.看下两张表的测试数据量:
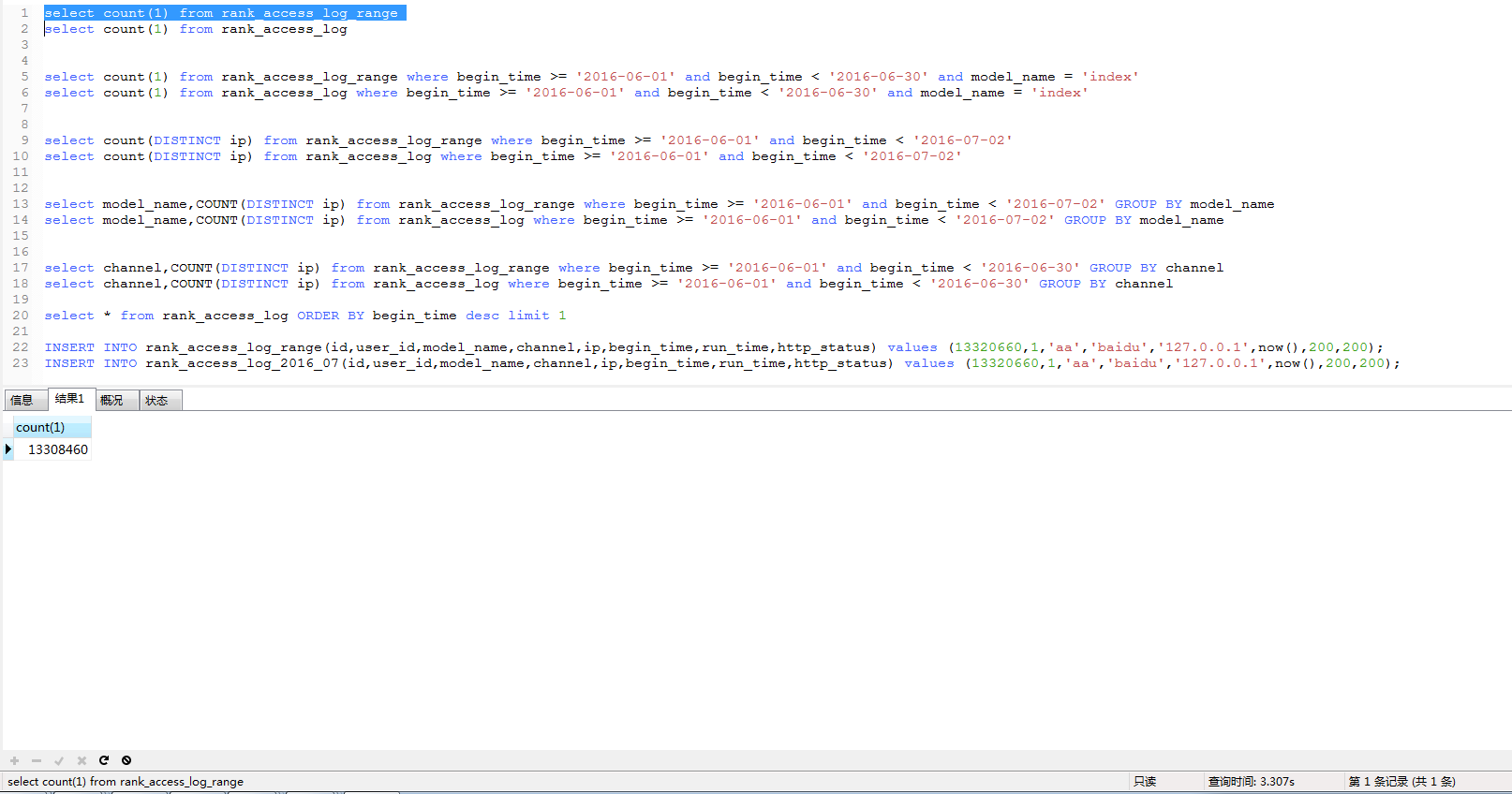
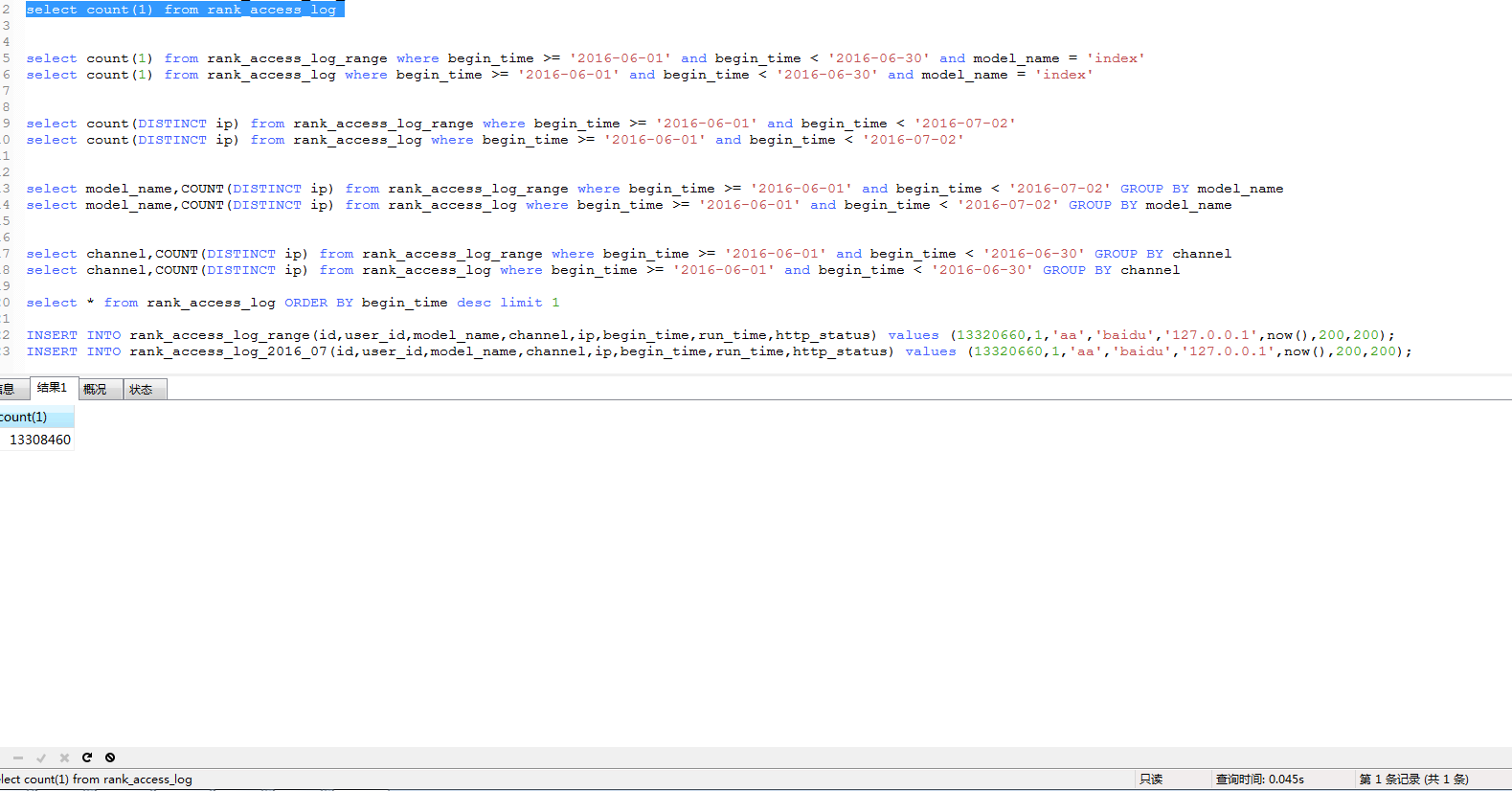
两张表都是1300w的数据。
3.insert测试(毋容置疑,肯定是merge表插入快,这是分表比分区的优势):


但是这里差距确实有点大。。。千万数据的索引校验和几十万数据的索引校验的差距。
4.简单select测试:
select count:
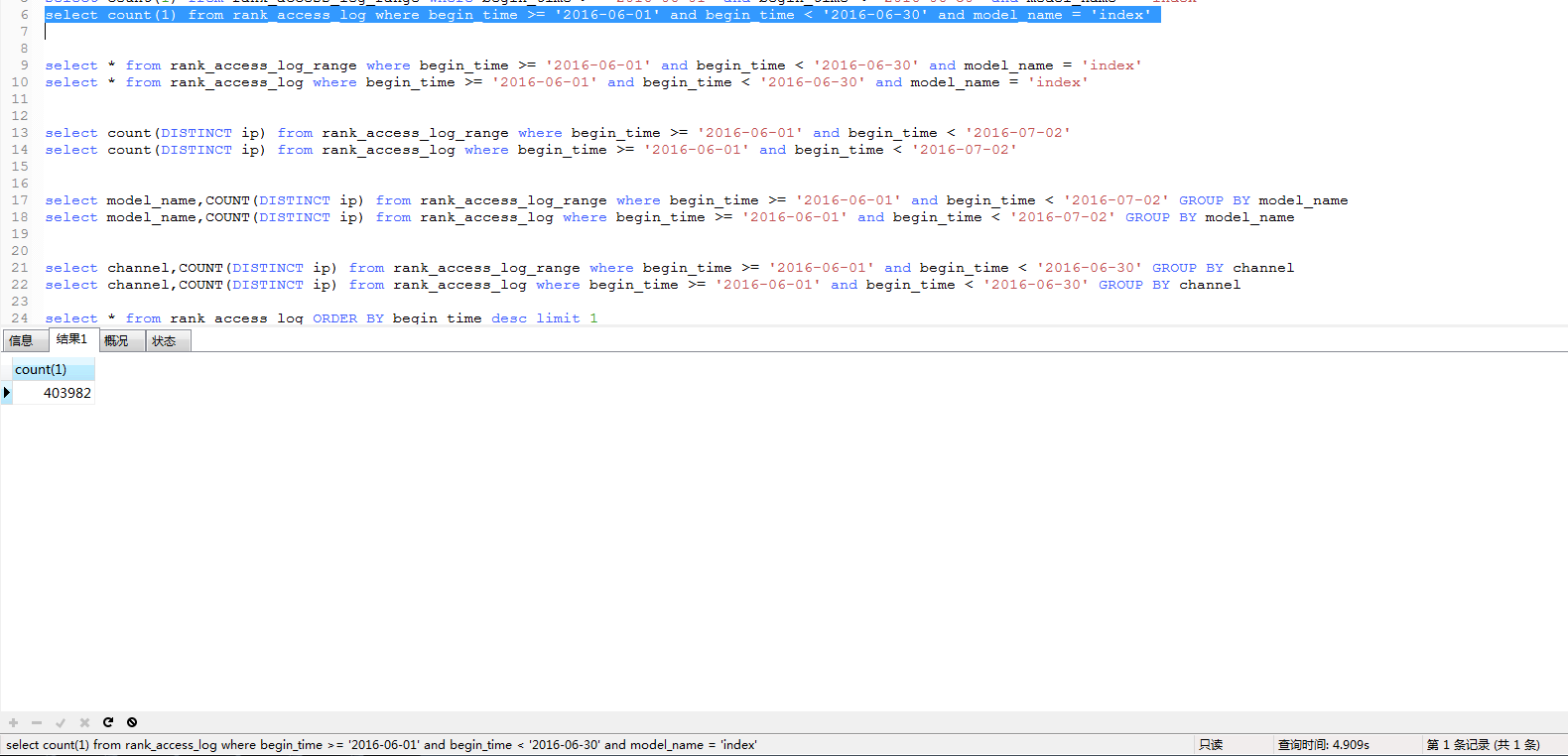
select *:
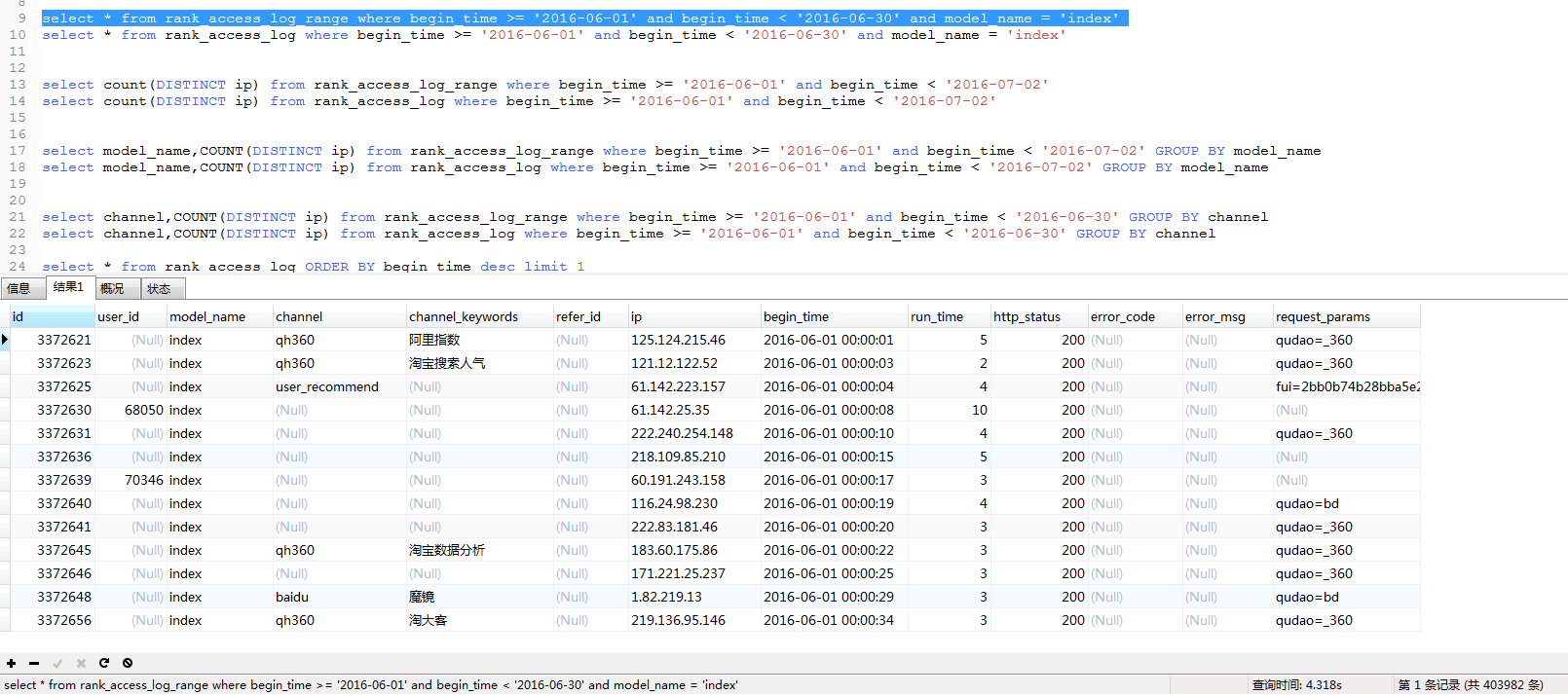
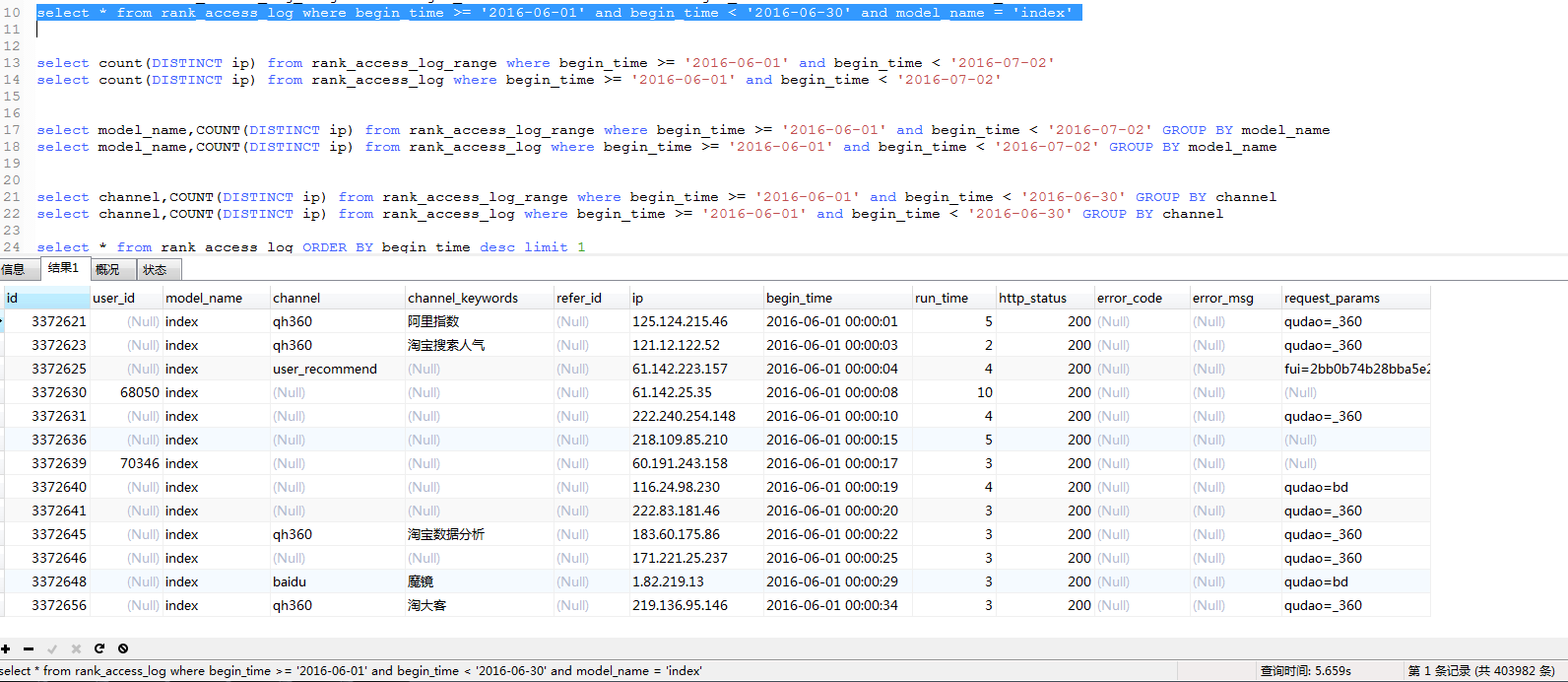
这里,mysql分区表略胜一筹。
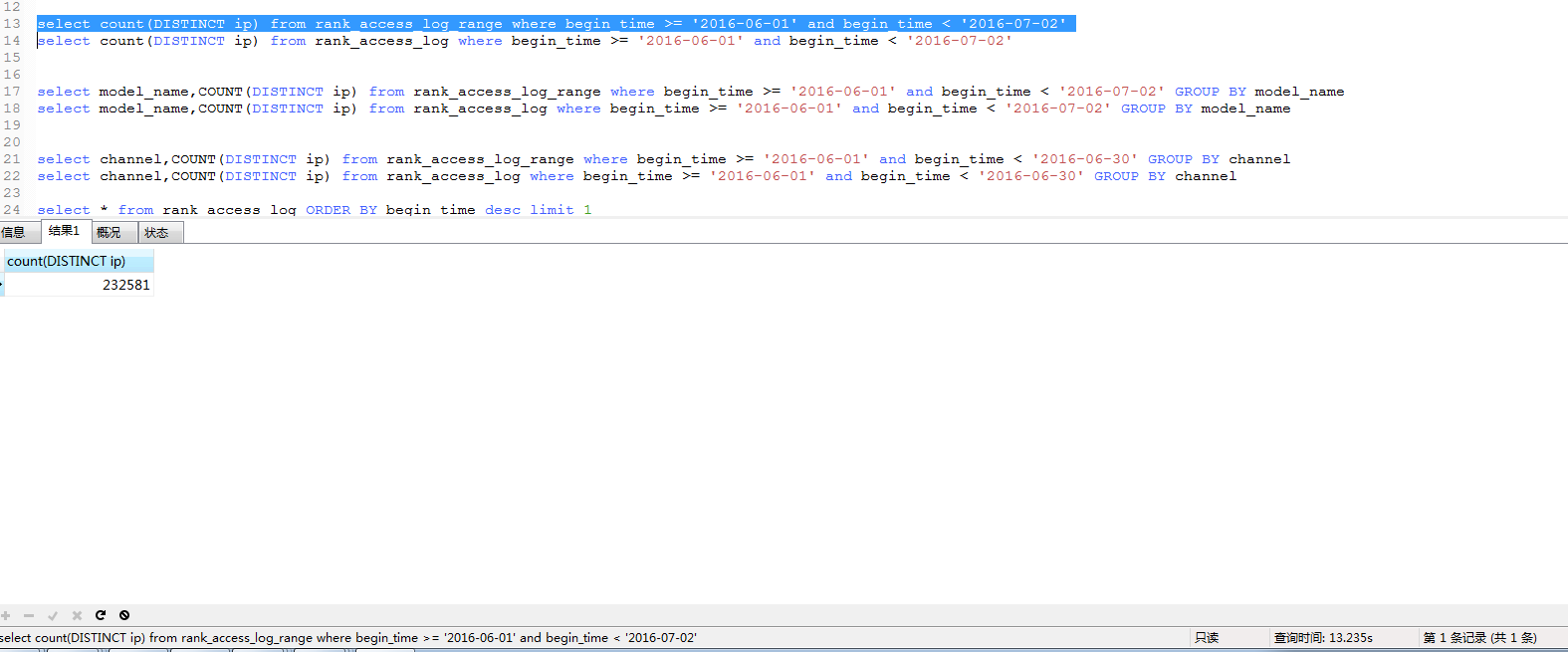
5.复杂select:
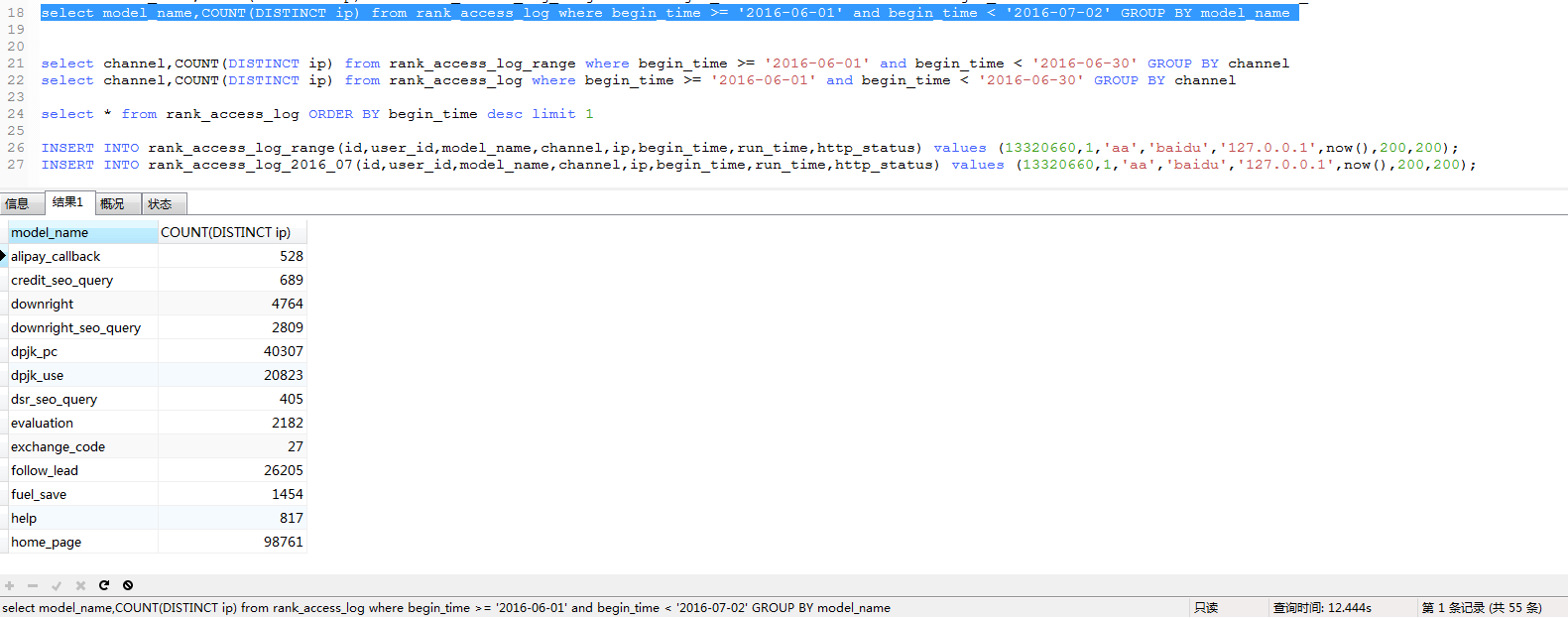
第一组:

第二组:

第三组:
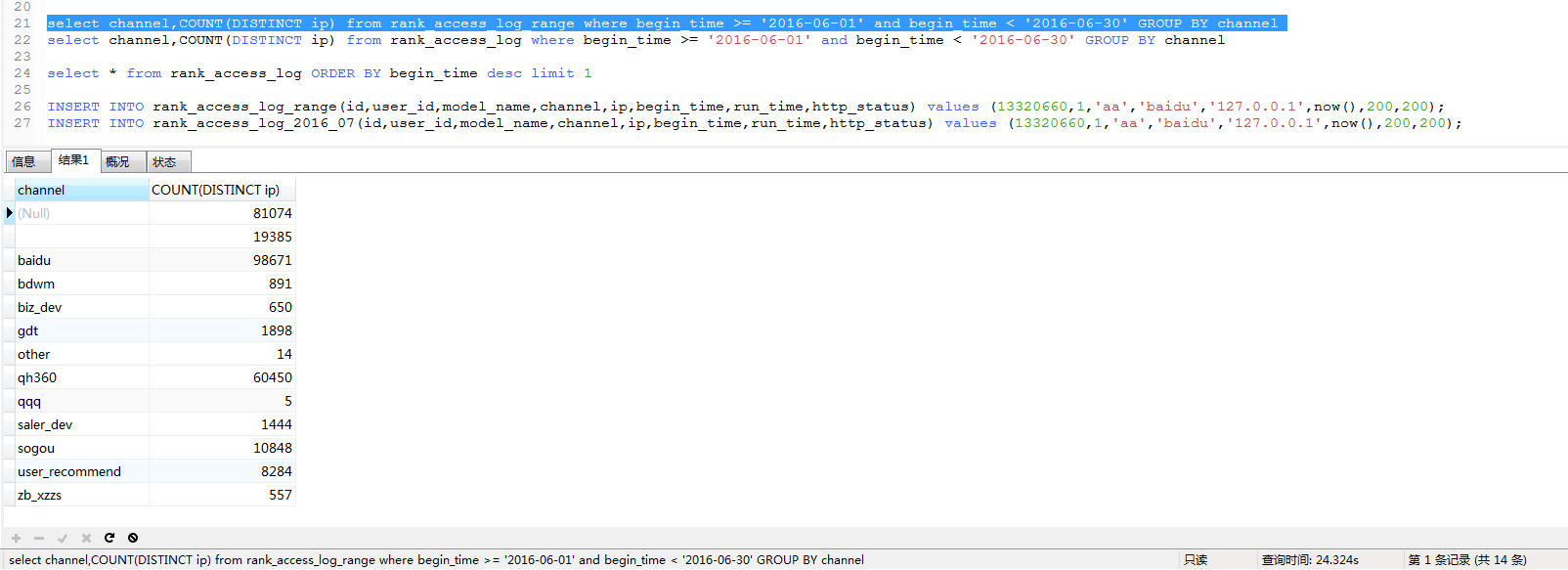
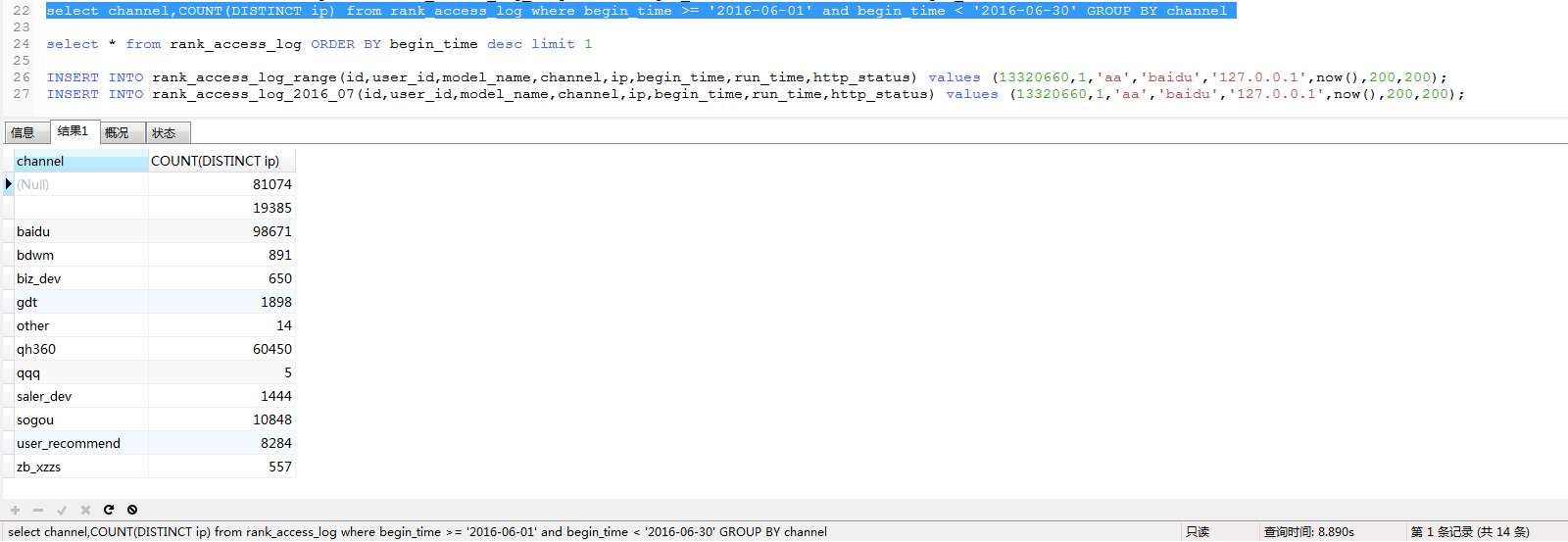
结论:
MyISAM merge表完爆mysql分区表。。完毕。
后记:
博客确实做的太烂,截图看不清楚的,请使用浏览器的放大功能。。














 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









