






昨天一开发同事反馈一个存储过程很慢,但是重编译后,存储过程就很快了。了解基本情况后,初步判断是参数嗅探问题。那么如何诊断定位、分析问题呢?下面简单介绍一下这次参数嗅探问题定位的流程过程。
首先查看该存储过程的执行计划相关信息:
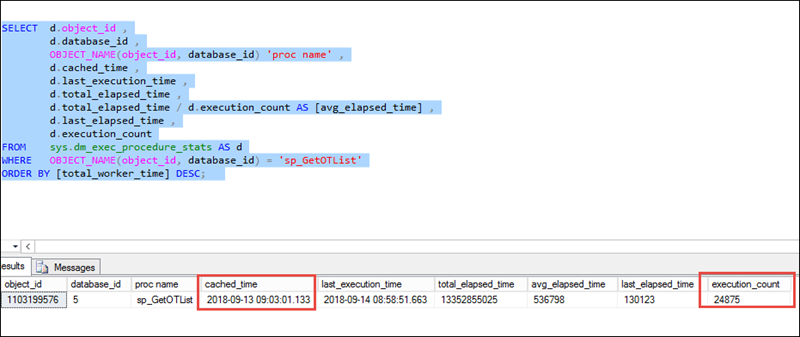
如下截图所示,此存储过程是2018-09-12 9:03:01缓存的,最后一次执行是2018-09-14 08:58,而且自上次缓存后,执行了24875次。从这里我们基本判断该存储过程一直在重用缓存的执行计划,而且没有产生重编译现象。
SELECT d.object_id ,d.database_id ,OBJECT_NAME(object_id, database_id) 'proc name' ,d.cached_time ,d.last_execution_time ,d.total_elapsed_time ,d.total_elapsed_time / d.execution_count AS [avg_elapsed_time] ,d.last_elapsed_time ,d.execution_countFROM sys.dm_exec_procedure_stats AS dWHERE OBJECT_NAME(object_id, database_id) = 'sp_GetOTList'ORDER BY [total_worker_time] DESC;
然后我们使用下面脚本找到该存储过程的实际执行计划,将存储过程的执行计划的XML内容拷贝到Plan Explorer工具。生成比较清晰、详细的执行计划图。
SELECTd.object_id ,DB_NAME(d.database_id) DBName ,OBJECT_NAME(object_id, database_id) 'SPName' ,d.cached_time ,d.last_execution_time ,d.total_elapsed_time/1000000 AS total_elapsed_time,d.total_elapsed_time / d.execution_count/1000000AS [avg_elapsed_time] ,d.last_elapsed_time/1000000 AS last_elapsed_time,d.execution_count ,d.total_physical_reads ,d.last_physical_reads ,d.total_logical_writes ,d.last_logical_reads ,et.text SQLText ,eqp.query_plan executionplanFROM sys.dm_exec_procedure_stats AS dCROSS APPLY sys.dm_exec_sql_text(d.sql_handle) etCROSS APPLY sys.dm_exec_query_plan(d.plan_handle) eqpWHERE OBJECT_NAME(object_id, database_id) = 'sp_GetOTList'ORDER BY [total_worker_time] DESC;
如下截图所示,我们可以清晰的找到Est Cost、 Est Cpu Cost、 Est IO Cost等高的SQL语句(其实这个是实际执行计划,而不是预估的执行计划),
然后重点研究、对比, 然后使用WITH(RECOMPILE)重新执行该存储过程,生成新的执行计划,然后按照上面方式将存储过程执行计划的XML拷贝到Plan Explorer工具里面。 然后我们可以对比、研究看看到底出现了什么情况
旧的实际执行计划
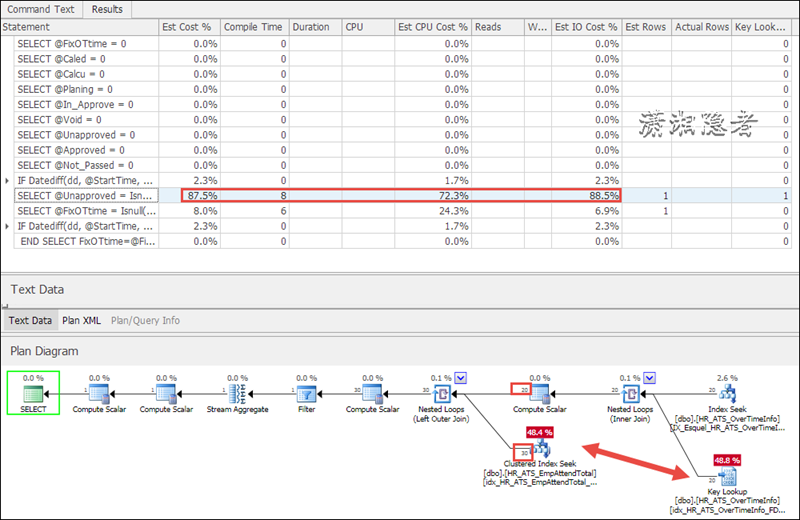
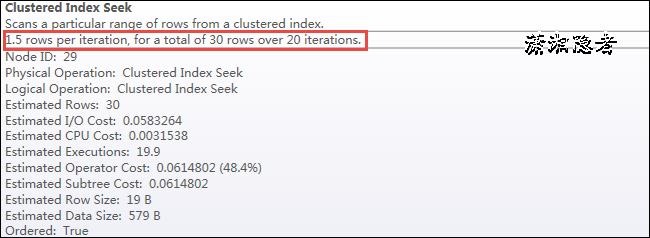
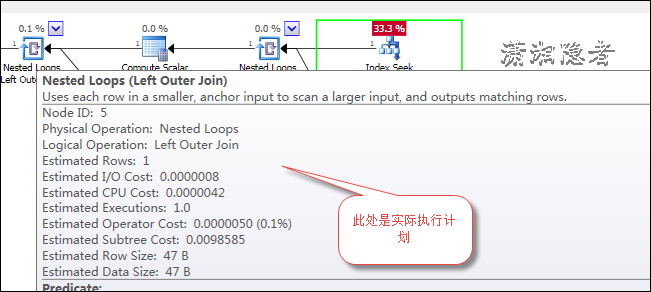
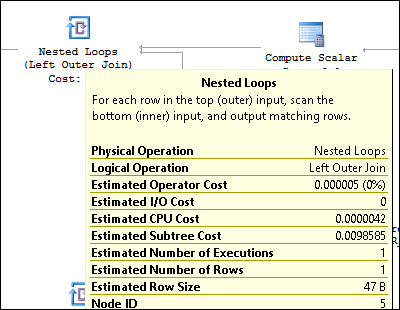
如上截图所示,开销最大的SQL语句的实际执行计划如上所示,注意开销占比最大的地方。 下面截图是Nested Loops里面循环的次数(迭代次数20次),也是我们
对比执行计划需要重点关注的地方
新的实际执行计划
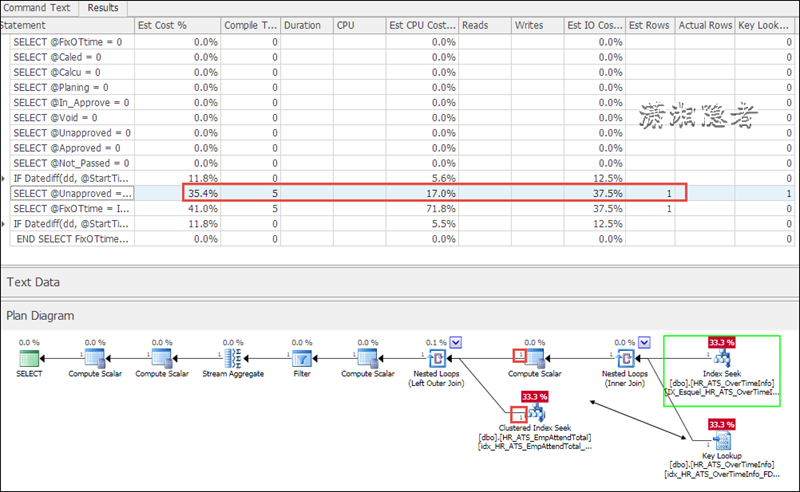
新的执行计划中,可以看到旧执行计划开销最大的SQL语句在整体开销的占比减少了很多,但是该语句的新旧执行计划是一样的。唯一不同的就是两个Nested Loops里面循环的次数不一样。这个就是产生性能差异的地方,如果对嵌套循环连接不太熟悉,可以参考一下下面这段内容:
Nested Loops也称为嵌套迭代,它将一个联接输入用作外部输入表(显示为图形执行计划中的顶端输入),将另一个联接输入用作内部(底端)输入表。外部循环逐行消耗外部输入表。内部循环为每个外部行执行,在内部输入表中搜索匹配行。最简单的情况是,搜索时扫描整个表或索引;这称为单纯嵌套循环联接。如果搜索时使用索引,则称为索引嵌套循环联接。如果将索引生成为查询计划的一部分(并在查询完成后立即将索引破坏),则称为临时索引嵌套循环联接。
旧执行计划:
嵌套循环次数:20* 30
嵌套循环次数:20*20
新执行计划:
嵌套循环次数: 1* 1
嵌套循环次数: 1* 1
那么为什么产生这个差异,就是因为存储过程里面一段SQL语句使用了存储过程参数,而恰巧里面那个表按照这个字段的数据分布很不均衡。所以当存储过程按照第一次传入的参数生成执行计划并缓存下来,而按照那个参数生成的执行计划并不是一直都是最优执行计划,那么就导致了性能问题出现了,这也就是参数嗅探问题。
解决方法
在SQL语句后面使用HINT提示来解决参数嗅探,本想在对应的SQL语句后面使用OPTION (RECOMPILE),但是考虑此存储过程调用频繁,而且同事极力推荐使用提示OPTION(OPTIMIZEFORUNKNOWN).修改过后,性能测试效果也确实显著。














 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









