







HashMap
核心流程
hashMap核心结构就是数组+链表的实现,在new HashMap()时,初始化默认threshold阈值为16,并设置默认的负载因子0.75f(与数组扩容有关)。
当有新的元素插入时,会根据计算出来的容量和负载因子重新计算阈值为12,并初始化HashMap的table属性(Entry数组)以及hashSeed属性;判断key是否为空,为空则将元素put到第0个数组中;通过位移运算得到一个hash值以及key的数组下标;遍历整个链表如果有相同的key,则覆盖并返回旧值,否则modCount+1;判断map中size大于threshold而且当前数组位置中不等于null,则进行扩容操作,最后使用头插法向该链表中插入新元素,并size++。
当获取一个元素时,如果key为null,则循环数组下标为0的链表,返回key为null的值,否则计算key的hash值,遍历链表,判断key值是否相等,如果命中则返回该Entry,否则返回null;
当修改某个HashMap对象时,modCount会加1
put()方法核心点
(1)hash容量
该方法会在put()方法初始化容量的时候调用,通过测试不难发现,他是取得某个int变量值的以内的最大2次方的数。而实际上是通过Integer.highestOneBit((number - 1) << 1)操作获得不小于该int值的最小2次方数。
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}(2)计算hash值
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//与操作计算数组下标
static int indexFor(int h, int length) {
return h & (length-1);
}hash()方法首先有个hashSeed的判断,暂时不管;根据hashCode()方法获得hash值,然后连续通过右移异或操作让高位参与hash计算,使得散列更加均匀。通过indexFor()方法的与操作计算数组下标,其中length为数组长度,因为length的长度是2的次方数,减1操作是确保低位都为1,从而与操作取得数组下标。这就是为什么hash容量是2的次方数的原因。
(3)扩容和新增元素
先扩容在新增元素。扩容条件:HashMap的size大小大于等于阈值threshold(容量*0.75)。创建一个Entry数组,容量是原有的hash容量的2倍,遍历原有的table以及链表,将所有的Entry对象,重新计算hash值和数组下标(如果rehash为false的情况下,数组下标最终只有两种可能,要么原来的下标,要么是两倍原来的下标),put到新的map中,将新创建的newTable赋值到HashMap对象中的table属性中,并重新计算阈值。计算新增元素的hash值和数组下标元素,put到map中。
(4)多线程扩容导致循环链表
假设两个线程都创建了新的Entry数组并同时执行到 Entry<K,V> next = e.next; 其中一个线程(t2)假死,另一个线程(t1)执行完两个循环后(或完成了扩容),t2又开始执行了,此时t2的某个Entry中链表会出现循环链表。最终HashMap的table属性被t1创建的Entry数组覆盖,当调用get()或者put()方法时就有可能出现死循环。
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}具体过程如下:
- t1先完成扩容

- t2在执行到 Entry<K,V> next = e.next;时让出时间片后等到t1完成扩容后,再开始扩容,先处理第一个节点
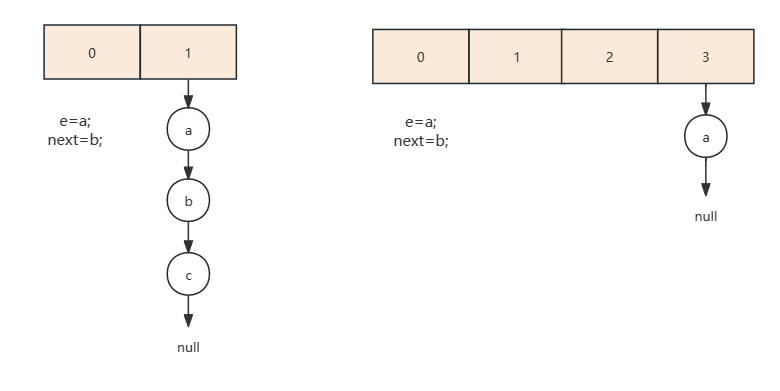
- 处理第二个节点。
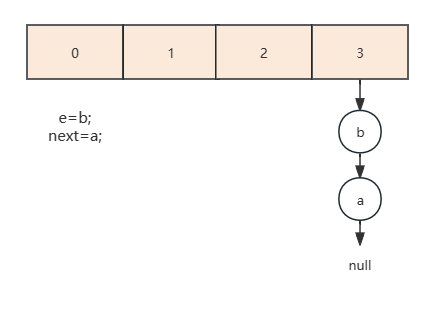
- 由于b指向a,所以接下来继续处理a,由于next=null循环就结束了
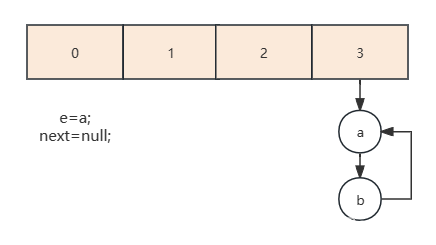
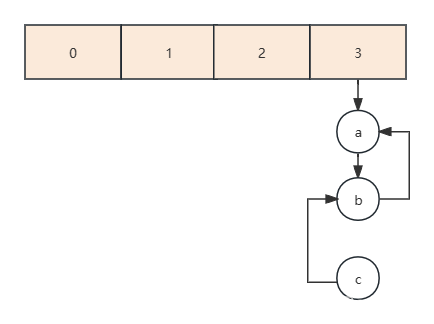
- 如果t2创建的table数组覆盖了t1的,由于t1已经完成了扩容,所以c是指向b的,最后就变成了这种死循环链表
ConcurrentHashMap
大家都知道ConcurrentHashMap是使用分段锁来保证线程安全的,那么它是如何实现线程安全的呢?本质上通过UNSAFE的cas保证把一个Segment对象放入Segment数组中,Segment类实现了ReentrantLock类,当调用Segment#put()会通过ReentrantLock来实现加锁保证线程安全
初始化
当new ConcurrentHashMap()时,在内存中会生成类似如下图的对象,其中Segment数组大小为16,并会初始化ConcurrentHashMap的第一个segment对象及其属性table(HashEntry数组,大小为2),数组其他位置均为null。

put()方法源码思路
- 判断元素是否为null,为空则抛异常;
- 对key进行hash得到hash值(这里的hash算法与HashMap有所不同),然后右移28位取高四位与15得到segment的下标值;通过UNSAFE.getObject()方法拿到当前数组位置的值,判断是否为null,为null则根据数组第一个Segment对象的table长度和负载因子创建HashEntry[]和Segment对象(这里就体现了初始化提前创建第一个segment对象的好处)最后通过while循环和unsafe的CAS操作将segment对象放入Segment数组中,并返回segment对象;
- 最后调用segment对象的put()方法,这里会加锁保证线程安全(segment继承了ReentrantLock),先调用tryLock()方法尝试获取锁,如果获取到了,计算key的hash值和下标位置,定位具体的HashEntry并遍历这个链表,如果存在相同的key则创建一个HashEntry覆盖,如果不存在就用头插法将新创建的HashEntry对象插入链表中;
static final class Segment<K,V> extends ReentrantLock implements Serializable {
...
}- 期间会判断当前segment是否需要扩容,扩容条件:segment对象内hashEntry个数大于阈值而且hashEntry数组长度小于最大值(1 << 30),满足条件则扩容为原来的两倍;
- 如果tryLock()方法没有获取到锁,调用scanAndLockForPut()方法,它会进行cpu层面的优化,因为如果使用lock()方法,会一直阻塞到获取到锁,阻塞的过程cpu资源就浪费了,此时用阻塞的时间调用scanAndLockForPut()去尝试创建一个HashEntry对象,但是不一定会创建成功,如果创建成功了并满足相关条件则调用lock()方法获取锁,并返回HashEntry对象(可能为null,但是不影响外层方法会判断是否需要创建HashEntry对象);modCount++
get()方法
get方法获取的逻辑与HashMap类似,最重要的一点是这里会使用unsafe操作来获取数组的中segment对象保证原子性
总结
- HashMap的key和value可以为空。ConcurrentHashMap的key和value不能为空
- HashMap是线程不安全的,多线程执行可能导致死循环。ConcurrentHashMap是线程安全的,segment对象通过死循环+cas保证线程安全,插入链表是通过JDK的ReentrantLock保证线程安全
- HashMap扩容是扩容整个数组,大小为原来的两倍。ConcurrentHashMap是扩容某个segment下table数组,也是扩容到原来的两倍















 1536
1536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









