






思维导图
 MySQL.png
MySQL.png
前言
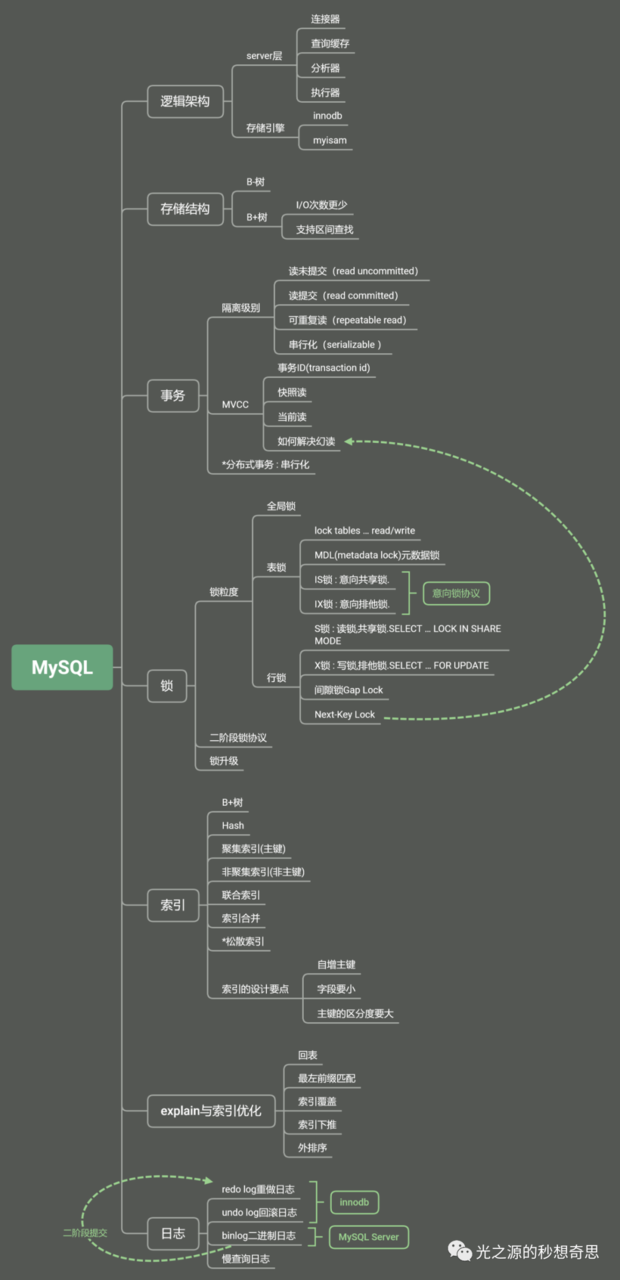
整理了MySQL的笔记后,我做了上面这张图.不过看了林晓斌老师的专栏后,我在这篇文章里并不打算直接陷入这些细节中了,而是从各个常用sql出发,拆分一下它们执行的流程.专栏里介绍了select和update的过程,我这里再稍微补充下order by和group by的原理.
SELECT是如何执行的
select查询是MySQL里最常使用的操作了,我们常会输入下面的语句:
mysql> select * from T where ID=10;
复制代码
然后,mysql就会返回T表中ID为10的结果.下面来拆解一下其中执行的过程.
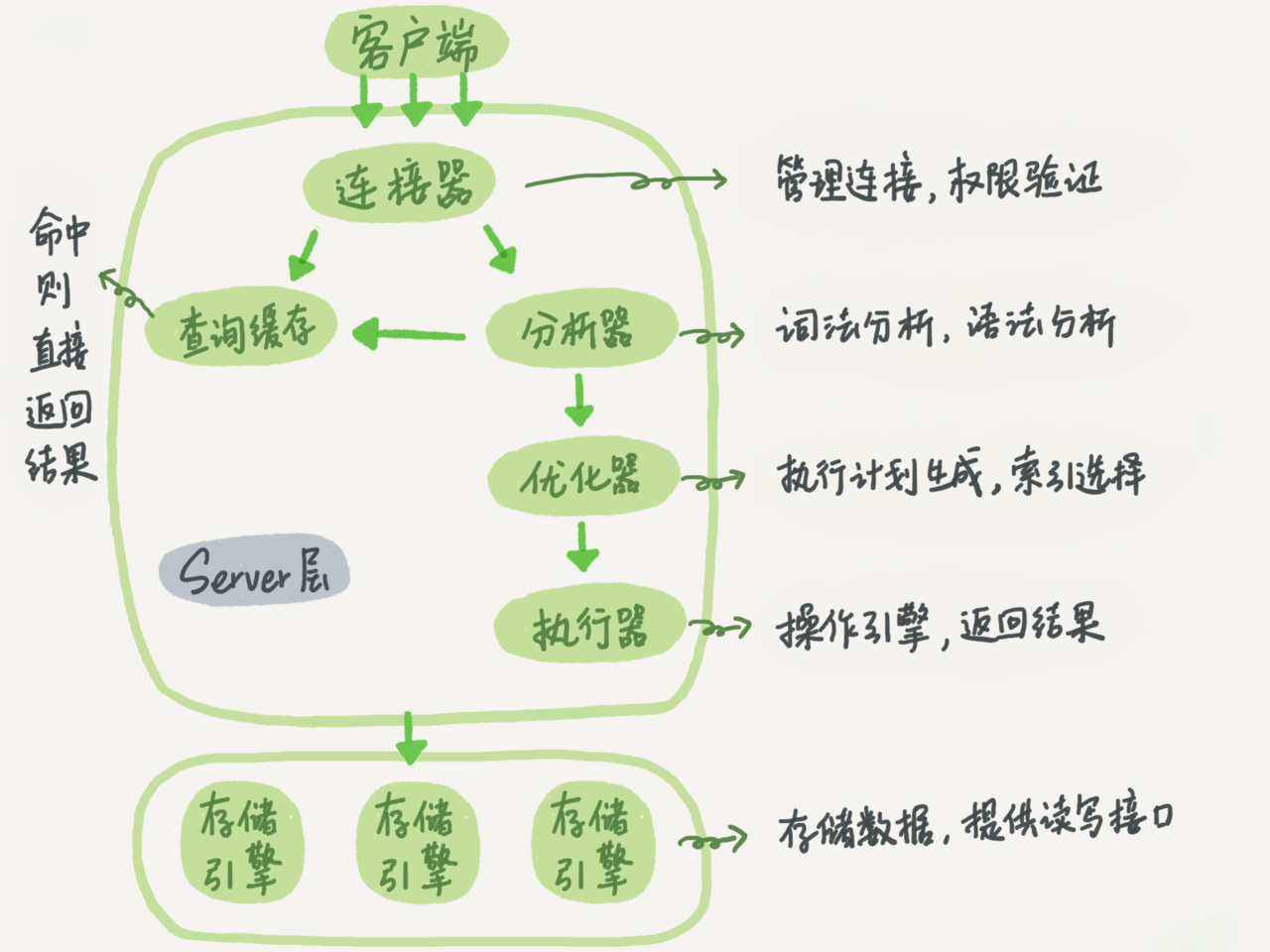
MySQL的逻辑架构
 MySQL架构
MySQL架构
上面这张图,可以很直观地看见一条sql从被提交后都经过哪些组件做了哪些处理.
大体来说,MySQL可以分为Server层和存储引擎层两部分。
Server层包括:
连接器
查询缓存
分析器
优化器
执行器
涵盖MySQL的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
而存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持InnoDB、MyISAM、Memory等多个存储引擎。现在最常用的存储引擎是InnoDB,它从MySQL 5.5.5版本开始成为了默认存储引擎.
InnoDB支持事务,MyISAM不支持.你可以这么理解,业务需要并发的,选择InnoDB,不需要并发的,选择MyISAM.而现在做Web业务,并发是少不了的,所以现在工业界基本都只用InnoDB.在我的mysql文章里,默认只讨论InnoDB.
连接器
当我们往mysql服务器发送一条sql时,需要先通过连接器建立连接.
连接器的作用包括管理连接和身份认证.
当身份认证通过后,这条连接会一直保持着"验证通过"的状态,直到连接断开,即便中途修改了用户密码.
客户端如果太长时间没动静,连接器就会自动将它断开.这个时间是由参数wait_timeout控制的,默认值是8小时.
查询缓存
连接建立完成后,就可以执行select语句了.
在真正执行之前,mysql还会检查一下这条语句有没有对应的缓存,若有就直接把缓存的结果返回.
上一篇文章提过,mysql的数据是存在硬盘里的,对于近期大量执行的一些select语句,mysql肯定不想每次都去读磁盘,所以它把它们都存了起来复用.
但是呢,在实践中才发现查询缓存失效非常频繁,只要某个表更新了一点东西,这个表上所有查询缓存都会被清空.
费了好大劲才存起来的结果,然后没等到使用就被清除了.所以MySQL在8.0以后直接把查询缓存给删了.
不过即便在以前的版本,除了不太会更新的配置表,都不建议使用查询缓存.
分析器
查询缓存结束了,就开始执行sql语句了吗?
不是的,在此之前mysql还需要通过分析器检查一下你的sql有没有毛病.
主要的工作是:
词法分析 : 你输入的是由多个字符串和空格组成的一条SQL语句,MySQL需要识别出里面的字符串分别是什么,代表什么。比如要把"select"这个关键字识别出来,这是一个查询语句.把"T"识别成表名T,把"ID"识别成列ID.
语法分析 : 根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个SQL语句是否满足MySQL语法。比如select有没有拼成selct
优化器
分析器处理完之后,该开始执行了吧?
很抱歉,还是不行.即便你的语句没有问题,为了提升执行的效率,还得经过优化器的优化.
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序。
也许你接触过执行计划explain这个概念,没有也不要紧,之后我们也会专门讲到.工欲善其事,必先利其器,在真正开始工作之前,研究制定出一个高效的执行计划,这就是优化器的任务.
执行器
上述的步骤都是在MySQL Server里面进行的,而MySQL的数据保存在存储引擎中,所以执行器得使用存储引擎提供的接口来获得我们的数据.
调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,如果不是则跳过,如果是则将这行存在结果集中;
调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
至此,这个语句就执行完成了。
UPDATE是如何执行的
update同样需要经过以上步骤,不过在执行时有所不同.
select时有缓存,其实update也有.试想,如果某一时刻mysql接到大量的写请求,对于每个请求mysql都得去写一次磁盘,那用于磁盘I/O的时间就会严重影响mysql的性能,导致qps上不去.
mysql的策略是先写日志(内存缓存中),等到不忙的时候再去写磁盘.
这个技术叫做WAL,Write-Ahead Logging.和Redis刚好是反过来的,redis先保存数据,再写aof.
这里的日志指的就是redo log,重做日志.有了redo log,InnoDB就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为crash-safe。
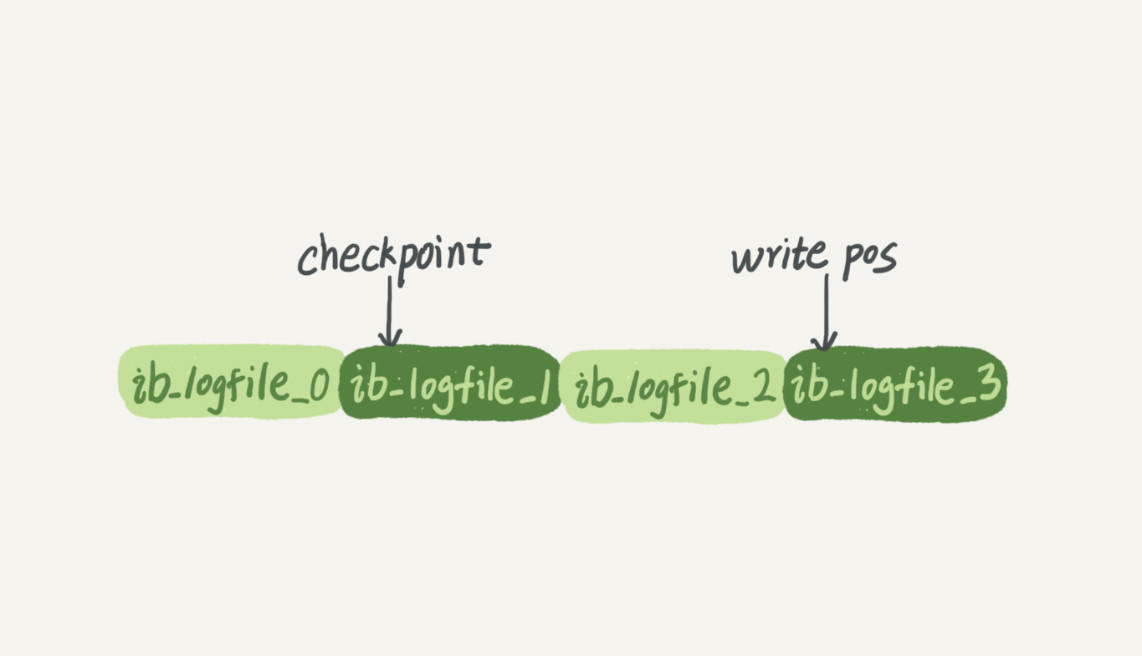
InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,那么redo log总共就可以记录4GB的操作。从头开始写,写到末尾就又回到开头循环写,如下面这个图所示。
 redo log
redo log
write_pos是记录点,每写一份数据,它就往后挪一挪.
check_point是擦除点,每把一份数据写回磁盘,它就往后挪一挪.
可以这么理解,write_pos在前面写(记录数据),check_point在后面追(把这些数据写回磁盘).当check_point追上write_pos,就说明全部数据都写回磁盘了.当write_pos追上check_point,说明缓存区写满了,暂时无法处理新的写请求.
除了redo log,更新数据时也需要写binlog.它们的不同在于:
redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
redo log是物理日志,记录的是“在某个数据页上做了什么修改”;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给ID=2这一行的c字段加1 ”。
redo log是循环写的,空间固定会用完;binlog是可以追加写入的。“追加写”是指binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
所以redo log用于数据库宕机时保证持久性,而binlog用于还原数据版本.可以这么理解,redo log是主,binlog是备.
对redo log和binlog的操作需要是原子性的.
如果一个事务先写redo log,写完以后数据库重启binlog丢失了,那么以后利用binlog恢复的话就会丢失这个事务.
如果一个事务先写binlog,写完写完以后数据库重启redo log丢失了,那么重启后redo log写回磁盘的数据就丢失了这个事务,可是以后利用binlog恢复的话这个事务又会回来.
mysql使用二阶段提交来保证redo log和binlog的操作是原子性的,要么全部保存,要么全部丢失.
以下是它们的二阶段提交流程:
 二阶段提交
二阶段提交
ORDER BY是如何执行的
在select 阶段,如果有where条件,那么使用索引的逻辑和没有order by是相同的.
如果没有where条件,order by的字段被索引覆盖,且select的字段刚好都在这个索引上(不需要回表的情况),那么就会使用这个索引.否则就全表扫描.
在select完之后,如果数据的排序已经满足要求了,就不需要排序.否则就要.
mysql会在内存中开辟一块空间用于排序,这个叫内排序.
如果数据量太大,缓冲区放不下,就得利用硬盘来协助排序了,这个叫外排序.
GROUP BY是如何执行的
在select阶段,如果有where条件,那么where能走索引就肯定走索引,不过还会判断group by能不能走索引,如果group的字段也能被索引覆盖,那么就会使用联合索引,先取出where的索引列,再到group by的索引中对where的索引列进行分组计算,最后取数据.
如果没有where条件,就直接判断group by能不能走索引,能的话就利用对应的索引进行分组.
不过这里要强调,group by的字段必须完全包含在索引中,而不仅仅只是满足最左前缀原则.假设索引列为(x,y)那么仅当group by的字段为(x)或者(x,y)时才能使用索引,(x,y,z)这样多出了z这列的情况会使索引失效.
group by的索引逻辑和回表与否没有关系,所以select的字段随意.
如果无法利用索引,mysql就得分配一个临时表(temporary)用于分组
此外group by还涉及松散索引和紧凑索引等概念,不过这些会留到索引优化的文章里再详细展开了.















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









