






HDD还是SSD?
如果你的NAS支持使用SSD固态硬盘,你会选择全HDD还是全SSD?
···

「机械硬盘HDD」和「固态硬盘SSD」各有优缺点
SSD:运行速度快;消耗功率少;产生的噪音、振动和热量低;不会产生坏道
HDD:容量更大;价格相对便宜;使用寿命相对更长
所以当运行需要更高随机IOPS的应用程序或将大量数据写入非连续块(例如,OLTP数据库和电子邮件服务)时,构建全闪存会让你心情更舒畅,但是存储空间容量可能会需要妥协减少,而且还会让你吃土还不起花呗…

别方,有SSD缓存
想容量和速度兼得?你可以选择在NAS中创建SSD缓存,让你的NAS一些盘位上大容量HDD,一些盘位上SSD来组建SSD缓存。SSD缓存提高存储空间和iSCSI LUN(包括常规文件和RAID上使用所有硬盘容量的LUN)的性能,从而提高随机读写速度,并大幅降低I/O延迟率。
SSD缓存是SSD中闪存芯片上频繁访问的数据(也称为热数据)的临时存储空间,较低延迟的SSD可以更容易地响应数据请求,以加快读/写速度并提高整体性能。
*请注意,由于大型顺序读/写操作(如HD视频流)缺少重新读取模式,因此此类工作负载模式无法从SSD缓存中获益。

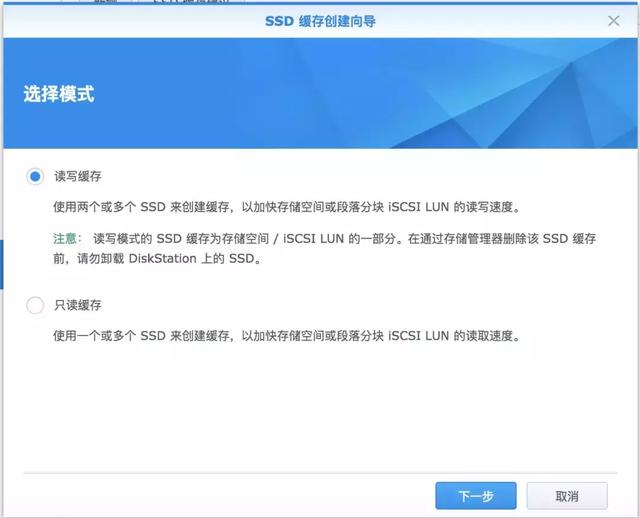
像是桌面型DS918+、DS1819+等都支持SSD缓存,创建SSD缓存有以下两种模式:
【只读缓存】:经常访问的数据会存储在缓存中以加快随机读取速度。由于它不参与写入数据,因此即使SSD发生故障,数据也相对安全。
【读写缓存】:与只读缓存相比,读写缓存将数据同步写入SSD。为确保数据安全,至少需要两块SSD来设置RAID 1,以允许一块SSD的容错。但如果损坏的SSD数量超过RAID配置中的容错能力,则会导致数据丢失的风险。
如何选择SSD?
有些小伙伴们知道,SSD写入数据的频率越高,其生命周期就越短。所以在选择SSD时,应该仔细查看两个参数来评估SSD耐用性:TBW(太字节写入)和DWPD(每天驱动器写入)。
TBW表示可以在整个生命周期内写入SSD的累计数据量
DWPD表示在保修期内每天可以覆盖整个SSD的次数
可以使用以下公式转换TBW和DWPD:
TBW = DWPD X 365 X保修(年)X容量(TB)
DWPD = TBW /(365 X保修(年)X容量(TB))
举个例子,假设一块SSD容量为2TB,保修期为5年。如果DWPD的等级为1,则表示接下来的5年内每天将2TB的数据写入其中。基于上述等式,TBW数字将为1 * 365 * 5 * 2 = 3650TB。所以最好在达到3650TB之前更换它。
如果你的NAS日常使用多密集型任务,那么建议使用企业级SSD以确保能够承受大量写入活动。因为消费级SSD的DWPD数字通常低于1,不能承受持续的读/写工作负载。相比之下,大多数企业级SSD的DWPD都在1到10之间,因此可以提供更好的耐用性。
NAS内存容量
除了SSD耐用性之外,还应该考虑SSD缓存的内存要求。由于SSD缓存需要一定量的系统内存,具体取决于缓存大小,因此如果要安装更大的SSD缓存,则要升级NAS内存。为了保持系统稳定性,1/4的预安装系统内存会被分配用于SSD缓存,如果缺少内存将限制SSD高速缓存大小。
举个例子,由于1 GB SSD占用大约416KB系统内存(包括可扩展内存),2 X 128GB SSD只读缓存(总共256GB)需要至少104MB内存,而2 X 128GB SSD读写缓存(总共128GB)消耗52MB内存。

而如果你的NAS具有PCIe插槽,还可以考虑安装支持SATA和NVMe SSD的双M.2 SSD扩展卡,避免占用硬盘盘位同时加快数据传输。
当然,选购SSD除了以上几点,还要记得参考兼容性列表
最后要注意,创建SSD缓存之后,不要随意插拔SSD和扩展卡,以免造成数据丢失。

















 2320
2320

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









