







一、前言
缓存是把双刃剑,用好了提升用户体验,用不好不知不觉掉进坑里了,正是因为在业务中遇到了缓存相关的问题,所以才有了这篇文章,目的是梳理缓存相关的逻辑,结合自己的业务,挖掘出项目中可以优化的点。
缓存分很多种,比如CDN缓存、数据库缓存、浏览器缓存等等,我们今天主要分析两种:
1. 浏览器缓存
2. 本地缓存
因为这两种都是和我们的前端业务紧密相关的,首先我们来说说浏览器的缓存。
二、浏览器缓存1. 先来看个面试题
在下面的index.html文件中有三种静态资源,每种资源都加载两次
<html lang="en">
<head>
<title>test cache</title>
<!-- 加载两个相同的css文件 -->
<link rel="stylesheet" href="./index.css">
<link rel="stylesheet" href="./index.css">
<!-- 加载两个相同的js文件 -->
<script src="./index.js"></script>
<script src="./index.js"></script>
<!-- 加载两个相同的图片资源 -->
<img src="./index.png">
<img src="./index.png">
</head>
<body>
hello
</body>
</html>
问题:
1.这个index.html文件中,不设置任何缓存相关的策略,每种静态资源会请求几次?
2.如果给存放三种资源的服务器响应头加上Cache-Control:no-cache,这三种资源又各自会被请求几次?
3.那如果把no-cache改成no-store,会请求几次?
4.把no-cache改成max-age,又会有什么变化?
我们先不着急看答案,先看看原理分析,一步步分析出答案。
2. 浏览器缓存策略分析
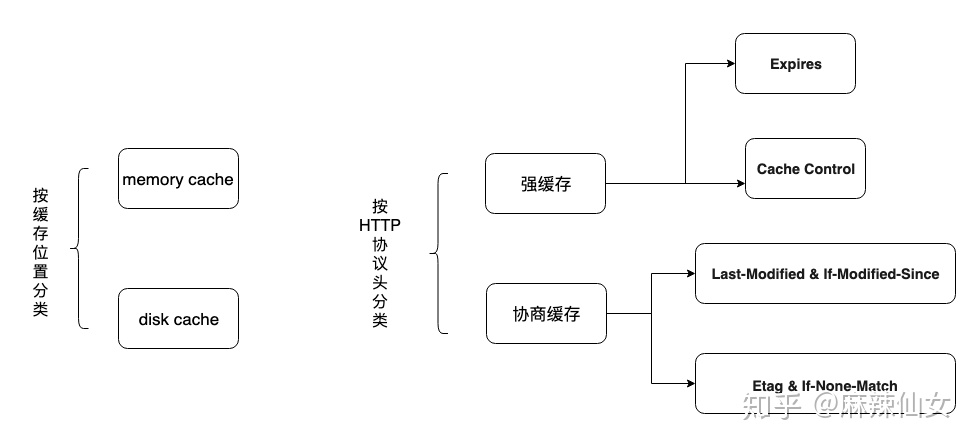
浏览器的缓存有多种分类,按位置划分可以分为内存缓存和硬盘缓存,那么浏览器是如何决定把一个资源缓存到disk中还是memory中呢?其实是根据当前的内存使用率决定的,如果内存使用率很高,要缓存的资源较大,浏览器就会将该资源直接缓存到硬盘中,但是如果内存充足,浏览器会优先将资源缓存到内存中,因为内存相比于硬盘,没有I/O操作,读取速度更快。
还可以按照HTTP协议规范来分类,可以分为强缓存和协商缓存,网上有很多对这些字段取值含义的详细解读,我们就简单介绍。首先强缓存是由响应头的两个字段来决定的:Expires和Cache Control,其中Expires是HTTP1.0的规范,Cache Control是HTTP1.1的。
协商缓存由两组字段决定,注意是两组。其中Last-Modified是响应头,if-Modified-Since是请求头,只要服务器设置好响应头即可,发送请求时浏览器会自主把请求头带过去。
Etag也是指响应头的值,If-None-Match是请求头,这一组比上一组更精确,是对文件的哈希值。
接下来再看浏览器命中强缓存和协商缓存的主要流程:
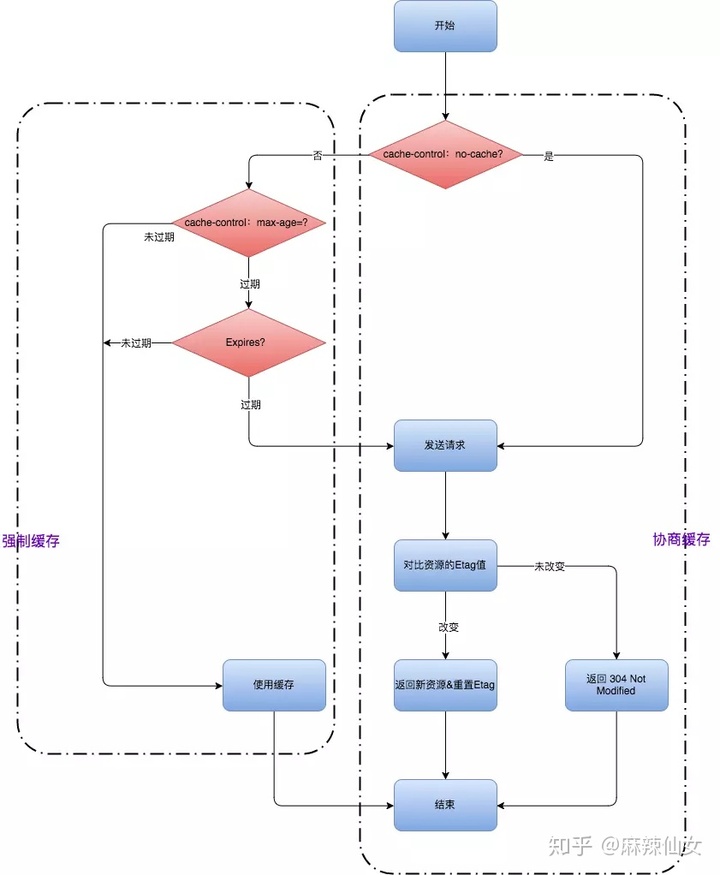
图片来自网络,侵删
3. 实践验证答案
用node写了一个存放静态文件的服务器,
tailorsira/bloggithub.com
可以把文件down下来,启用步骤如下:
- npm install
- npm start
- 浏览器输入http://127.0.0.1:3000/index.html 即可开始验证
- 要修改响应头的话,就直接修改app.js文件即可,有的我注释掉了,可以一一开启注释代码验证上面的四个问题。
为避免有小懒虫懒得验证,直接在这里公布答案:
1.不设置任何缓存策略的情况下,请求只有一次。这是浏览器本身做的优化,在解析html文件时,如果监测到两个资源的地址相同,那么只会请求一次。
2.设置Cache-Control是no-cache,也是相同资源只有一次请求,no-cache并不是一定没有缓存,而是无法命中强缓存,但是还可以继续查找是否能命中协商缓存。
3.改成no-store之后,请求就有两次了,这也正好验证了no-store和no-cache的区别,no-store是绝对不走缓存,每次请求都去服务器请求新资源。
4.改成max-age,这个值设置为一年,请求也只会走一次,而且在浏览器当前TAB刷新页面,会发现Network中Size一栏不是具体的文件大小,而是from cache,这是因为已经命中了浏览器的缓存策略,所以再次缓存时,是去缓存中取资源。
4. 结合业务谈应用
了解了缓存的原理后,如何用来优化我们的项目呢?所有站点资源大致分为两类:
1.不经常变化的资源,比如打包出来的第三方库JS,给这类资源设置一个较长的缓存周期,比如一年
Cache-Control: max-age=31536000设置了这个字段后,就命中了强缓存策略,那么如果在一年内我们修改了这个文件,如何让用户端能够强制请求最新资源呢?
答案就是哈希,在webpack打包时给这类资源加上contentHash,一旦资源内容有更新,打包出来的资源的哈希值也会更新,用户端去加载资源时,去缓存中找不到符合这个哈希值版本的资源文件,自然会去服务端请求最新的资源。
2.经常变化的资源,比如模板文件html,这类文件的请求URL通常不会变化,但是内容会经常变化,因为每次项目更新,插入到html文件中的js或者css可能有更新。
Cache-Control: no-cache协商缓存响应头设置成no-cache,配合协商缓存一起使用,浏览器每次都会去服务器核对资源有没有更新,如果资源没有更新,那么会返回一个304的状态码,不会返回真实的响应体,这种形式相比于命中强缓存,虽然无法节省那次网络请求,但是如果命中了协商缓存,会节省返回的响应体体积,也算是性能优化的一种。
三、本地缓存
本地缓存有很多种,SessionStorage、LocalStorage、indexedDB、WebSQL,今天主讲LocalStorage,因为这个是在前端业务项目中应用最广泛的。
1. 先来看个面试题
- https://a.test.com 和 https://b.test.com 能否共享localStorage?
- https://a.test.com 和 https://test.com 能否共享localStorage?
答案:不能
- 因为localStorage也有同源策略的限制,不能跨域。
- 让子域名无法继承父域名的LS,这点和cookie的差别很大。
2.应用场景
- 提升用户体验
- 页面传参
常用的有这两个,一个是为了提升用户体验,节省页面渲染时间,我们会先去缓存数据,再去请求接口数据,请求到了新数据的话,再去更新页面。
那技术很简单,业务很复杂,目前你的APP中既有客户端、又有weex、RN和H5,每个业务不同的团队在维护,没有一个统一的处理规范的话,如果LS被滥用了,很容易就会被存满,因为现在基本IOS、安卓或者浏览器的LS容量就是5M左右,如果用户不主动去清除LS的话,那存满了之后,后面的业务就存不进去了。
那在这个场景中,即便是存不进去了,只要我能拿到接口的数据,影响也不大,但是下面这个应用场景,就会有很大风险了。如果我用LS来共享两个页面的数据,A页面存不进去,B页面当然也就取不出参数,业务肯定就有问题了。
所以针对上面这两种应用场景,我们还是要确认LS的一些使用规范,避免滥用。
3. 什么场景才需要缓存?
1.重要页面重要数据
2.离线也能浏览的页面
我们思考一个问题,什么样的页面才适合缓存数据呢? 当然是重要页面,比如首页和大促用的会场页面,那像一些PVUV比较低的二级页就不建议再缓存接口数据了。
另外就是有离线浏览需求的页面,那针对跨页面传递数据的需求,也有其他的可替代的解决方案,比如通过url传递,或者改造成单页应用,或者改造接口。具体应用哪种方案要看业务场景。
4. 项目规范
存满了之后,如何处理?如果你的业务中只是把LS当作缓存使用,那就不需要数据备份,只要从接口中能拿到数据即可。这种情况下,如果存储的时候发现存满了,全部清掉即可。
伪代码如下:
function saveStorage (key, data) {
try {
localStorage.setItem(key, data);
} catch (e) {
if (e.code === QUOTA_EXCEEDED_ERR_CODE) {
clearStorage();
localStorage.setItem(key, data);
}
}
}四、扩展
本地缓存不只是有localStorage,还有indexedDB和websql,但是没有在前端普及,大概是因为前端需要了解写数据库的基本知识才能用好它,而且他们的API又臭又长,所以在此推荐一个开源库:https://github.com/localForage/localForage
这个库简化了indexedDB的API,可以和使用LS一样简单,感兴趣的小伙伴可以down来看看。















 1594
1594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









