






位运算
- 与( AND),
a & b,对于每一个比特位,只有两个操作数相应的比特位都是1时,结果才为1,否则为0。 - 或(OR),
a | b,对于每一个比特位,当两个操作数相应的比特位至少有一个1时,结果为1,否则为0。 - 异或(XOR),
a ^ b,对于每一个比特位,当两个操作数相应的比特位有且只有一个1时,结果为1,否则为0。 - 非(NOT),
~ a,反转操作数的比特位,即0变成1,1变成0。 - 左移,
a << b,将 a 的二进制形式向左移 b (< 32) 比特位,右边用0填充。 - 有符号右移,
a >> b, 将 a 的二进制表示向右移 b (< 32) 位,丢弃被移出的位,并且使用复制最左侧的一位填充。 - 无符号右移,
a >>> b, 将 a 的二进制表示向右移 b (< 32) 位,丢弃被移出的位,并使用 0 在左侧填充,所以结果总是非负。
示例:
9 << 2 // 36
// 00000000 00000000 00000000 00001001 -> 00000000 00000000 00000000 00100100 -> 36
9 >> 2 // 2
// 00000000 00000000 00000000 00001001 -> 00000000 00000000 00000000 00000010 -> 2
-9 >> 2 // -3
// 11111111 11111111 11111111 11110111 -> 11111111 11111111 11111111 11111101 -> -3
-9 >>> 2 // 1073741821
// 11111111 11111111 11111111 11110111 -> 00111111 11111111 11111111 11111101 -> 1073741821
8 & 7 //相当于二进制1000 & 0111 -> 0000 -> 0
8 | 7 //相当于二进制1000 | 0111 -> 1111 -> 15
8 ^ 7 //相当于二进制1000 ^ 0111 -> 1111 -> 15
注意:
- 异或就是不进位的加法。
- 负数的二进制表示法,先取反,再加1。
比如-9的二进制表示,求解过程如下:
- 先求出原码: 00000000 00000000 00000000 00001001
- 求出反码: 11111111 11111111 11111111 11110110
- 再加1得补码:11111111 11111111 11111111 11110111
时间空间复杂度
常见的时间复杂度按照从小到大的顺序排列,有以下几种:

常见的空间复杂度有 O(1)、O(n) 和 O(n^2)。
数据结构
数据结构分类:
- 逻辑结构:反映数据之间的逻辑关系;
- 集合:结构中的数据元素除了同属于一种类型外,别无其它关系。(无逻辑关系), 如
一维数组、Map、Set - 线性结构 :数据元素之间一对一的关系(线性表),如
一维数组,队列,栈,链表,线性表 - 树形结构 :数据元素之间一对多的关系(非线性),如
二叉树 - 图状结构或网状结构: 结构中的数据元素之间存在多对多的关系(非线性),如
二维数组
- 存储结构:数据结构在计算机中的表示;
- 顺序存储数据结构
- 链式存储数据结构
- 索引存储数据结构
- 散列存储数据结构
大家需要掌握以下几种:
- 数组
- Map、Set
- 栈
- 队列
- 链表
- 树(这里我们着重讲二叉树)
- 堆
数组
数组的创建: 有两种方式,const arr = [1, 2, 3, 4]或 const arr = new Array()。
数组的访问与遍历: 访问通过访问索引下标arr[0],遍历有for、forEach、map等方法,从效率上讲,for是最快的。
二维数组,又叫矩阵。二维数组的初始化,不要用fill完成const arr =(new Array(7)).fill([]),否则填充的是同一个数组的引用。而应该使用for来初始化。
const len = arr.length
for(let i=0;i<len;i++) {
// 将数组的每一个坑位初始化为数组
arr[i] = []
}
数组API: concat、some、join、sort、push(添加到尾部)、pop(删除尾部)、unshift(添加到头部)、shift(删除头部)、slice(返回一个截取的新数组)、splice(修改原有数组)。
splice() 方法通过删除或替换现有元素或者原地添加新的元素来修改数组,并以数组形式返回被修改的内容。此方法会改变原数组。
示例:
const months = ['Jan', 'March', 'April', 'June'];
// 在index 1位置插入
months.splice(1, 0, 'Feb');
console.log(months); //["Jan", "Feb", "March", "April", "June"]
// 在index 4位置替换
months.splice(4, 1, 'May');
console.log(months); // ["Jan", "Feb", "March", "April", "May"]
// 在index 2位删除一个元素
months.splice(2, 1);
console.log(months); // ["Jan", "Feb", "April", "May"]
// 在倒数第二2位 删除一个元素
months.splice(-2, 1);
console.log(months); // ["Jan", "Feb", "May"]
slice() 方法返回一个新的数组对象,这一对象是一个由 begin 和 end 决定的原数组的浅拷贝(包括 begin,不包括end)。原始数组不会被改变。
示例:
const animals = ['ant', 'bison', 'camel', 'duck', 'elephant'];
console.log(animals.slice(2)); // ["camel", "duck", "elephant"]
//从index 2位开始,到index 4结束(不包括4)返回
console.log(animals.slice(2, 4)); // ["camel", "duck"]
console.log(animals.slice(1, 5)); // ["bison", "camel", "duck", "elephant"]
Map
Map对象保存键值对,并且能够记住键的原始插入顺序。任何值(对象或者原始值) 都可以作为一个键或一个值。
一个Map对象在迭代时会根据对象中元素的插入顺序来进行 — 一个 for...of 循环在每次迭代后会返回一个形式为[key,value]的数组。
Map与Object的区别:

Set
Set对象允许你存储任何类型的唯一值,无论是原始值或者是对象引用。
Set对象是值的集合,你可以按照插入的顺序迭代它的元素。 Set中的元素只会出现一次,即 Set 中的元素是唯一的。
let myArray = ["value1", "value2", "value3"];
// 用Set构造器将Array转换为Set
let mySet = new Set(myArray);
mySet.has("value1"); // returns true
// 用...(展开操作符)操作符将Set转换为Array
console.log([...mySet]); // 与myArray完全一致
//数组去重
const numbers = [2,3,4,4,2,3,3,4,4,5,5,6,6,7,5,32,3,4,5]
console.log([...new Set(numbers)])
// [2, 3, 4, 5, 6, 7, 32]
栈
栈是一种后进先出(LIFO,Last In First Out)的数据结构。只用 pop 和 push 完成增删的“数组”。
function Stack(){
// 用let创建一个私有容器,无法用this选择到dataStore;
let dataStore = [];
// 模拟进栈的方法
this.push = function(element){
dataStore.push(element);
};
// 模拟出栈的方法,返回值是出栈的元素。
this.pop = function(){
return dataStore.pop();
};
// 返回栈顶元素
this.peek = function(){
return dataStore[dataStore.length-1];
};
// 是否为空栈
this.isEmpty = function(){
return dataStore.length === 0
};
// 获取栈结构的长度。
this.size = function(){
return dataStore.length;
};
// 清除栈结构内的所有元素。
this.clear = function(){
dataStore = [];
}
}
一个单独的栈结构生成了,我们来测试一下。
let stack = new Stack();
stack.push(1);
stack.push(2);
stack.push(5);
stack.peek(); // return 5
stack.size(); // return 3
stack.clear();
stack.peek(); // undefined
应用场景:JavaScript引擎中的调用栈就是最直接的应用。
- 当我们写递归时,一定要设定出口,否则就会因为函数调用只进栈不出栈,而导致最终栈溢出。
- Redux与Koa的中间件洋葱模型也是栈的典型应用。
- 闭包函数由于要保持内部变量的引用,在执行完之后并不会退栈。
队列
队列是一种先进先出(FIFO,First In First Out)的数据结构。只用 push 和 shift 完成增删的“数组”。
首先来看单链队列。
class Queue {
constructor() {
this.queue = []
}
enQueue(item) {
this.queue.push(item)
}
deQueue() {
return this.queue.shift()
}
getHeader() {
return this.queue[0]
}
getLength() {
return this.queue.length
}
isEmpty() {
return this.getLength() === 0
}
}
循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。
但是使用循环队列,我们能使用这些空间去存储新的值。
因为单链队列在出队操作的时候需要 O(n) 的时间复杂度,所以引入了循环队列。循环队列的出队操作平均是 O(1) 的时间复杂度。
class SqQueue {
constructor(length) {
this.queue = new Array(length + 1)
// 队头
this.first = 0
// 队尾
this.last = 0
// 当前队列大小
this.size = 0
}
enQueue(item) {
// 判断队尾 + 1 是否为队头
// 如果是就代表需要扩容数组
// % this.queue.length 是为了防止数组越界
if (this.first === (this.last + 1) % this.queue.length) {
this.resize(this.getLength() * 2 + 1)
}
this.queue[this.last] = item
this.size++
this.last = (this.last + 1) % this.queue.length
}
deQueue() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
let r = this.queue[this.first]
this.queue[this.first] = null
this.first = (this.first + 1) % this.queue.length
this.size--
// 判断当前队列大小是否过小
// 为了保证不浪费空间,在队列空间等于总长度四分之一时
// 且不为 2 时缩小总长度为当前的一半
if (this.size === this.getLength() / 4 && this.getLength() / 2 !== 0) {
this.resize(this.getLength() / 2)
}
return r
}
getHeader() {
if (this.isEmpty()) {
throw Error('Queue is empty')
}
return this.queue[this.first]
}
getLength() {
return this.queue.length - 1
}
isEmpty() {
return this.first === this.last
}
resize(length) {
let q = new Array(length)
for (let i = 0; i < length; i++) {
q[i] = this.queue[(i + this.first) % this.queue.length]
}
this.queue = q
this.first = 0
this.last = this.size
}
}
应用场景:JavaScript运行时中的消息队列就是队列的典型应用。
链表
链表和数组相似,它们都是有序的列表、都是线性结构(有且仅有一个前驱、有且仅有一个后继)。不同点在于,链表中,数据单位的名称叫做“结点”,而结点和结点的分布,在内存中可以是离散的。
function ListNode(val) {
this.val = val;
this.next = null;
}
const node = new ListNode(1)
node.next = new ListNode(2)
在链表中间添加或删除元素时,需要变更前驱结点和目标结点的 next 指针指向。
class Node {
constructor(v, next) {
this.value = v
this.next = next
}
}
class LinkList {
constructor() {
// 链表长度
this.size = 0
// 虚拟头部
this.dummyNode = new Node(null, null)
}
find(header, index, currentIndex) {
if (index === currentIndex) return header
return this.find(header.next, index, currentIndex + 1)
}
addNode(v, index) {
this.checkIndex(index)
// 当往链表末尾插入时,prev.next 为空
// 其他情况时,因为要插入节点,所以插入的节点
// 的 next 应该是 prev.next
// 然后设置 prev.next 为插入的节点
let prev = this.find(this.dummyNode, index, 0)
prev.next = new Node(v, prev.next)
this.size++
return prev.next
}
insertNode(v, index) {
return this.addNode(v, index)
}
addToFirst(v) {
return this.addNode(v, 0)
}
addToLast(v) {
return this.addNode(v, this.size)
}
removeNode(index, isLast) {
this.checkIndex(index)
index = isLast ? index - 1 : index
let prev = this.find(this.dummyNode, index, 0)
let node = prev.next
prev.next = node.next
node.next = null
this.size--
return node
}
removeFirstNode() {
return this.removeNode(0)
}
removeLastNode() {
return this.removeNode(this.size, true)
}
checkIndex(index) {
if (index < 0 || index > this.size) throw Error('Index error')
}
getNode(index) {
this.checkIndex(index)
if (this.isEmpty()) return
return this.find(this.dummyNode, index, 0).next
}
isEmpty() {
return this.size === 0
}
getSize() {
return this.size
}
}
注意:
const arr = [1,2,3,4]这样的纯数字数组对应的内存是连续的。而如果const arr = ['haha', 1, {a:1}]对应的内存就是非连续的了。- 链表的内存是非连续的。
- 链表的插入/删除效率较高(O(1)),而访问效率较低(O(n));数组的访问效率较高(O(1)),而插入效率较低(O(n))。
二叉树
- 它可以没有根结点,作为一棵空树存在
- 如果它不是空树,那么必须由根结点、左子树和右子树组成,且左右子树都是二叉树。
它的结构分为三块:
- 数据域
- 左侧子结点(左子树根结点)的引用
- 右侧子结点(右子树根结点)的引用
// 二叉树结点的构造函数
function TreeNode(val) {
this.val = val;
this.left = this.right = null;
}
按照顺序规则的不同,遍历方式有以下四种:
- 先序遍历: 根结点 -> 左子树 -> 右子树
- 中序遍历: 左子树 -> 根结点 -> 右子树
- 后序遍历: 左子树 -> 右子树 -> 根结点
- 层次遍历: BFS(广度优先搜索)
按照实现方式的不同,遍历方式又可以分为以下两种:
- 递归遍历(先、中、后序遍历)
- 迭代遍历(层次遍历)
所谓的“先序”、“中序”和“后序”,“先”、“中”、“后”其实就是指根结点的遍历时机。
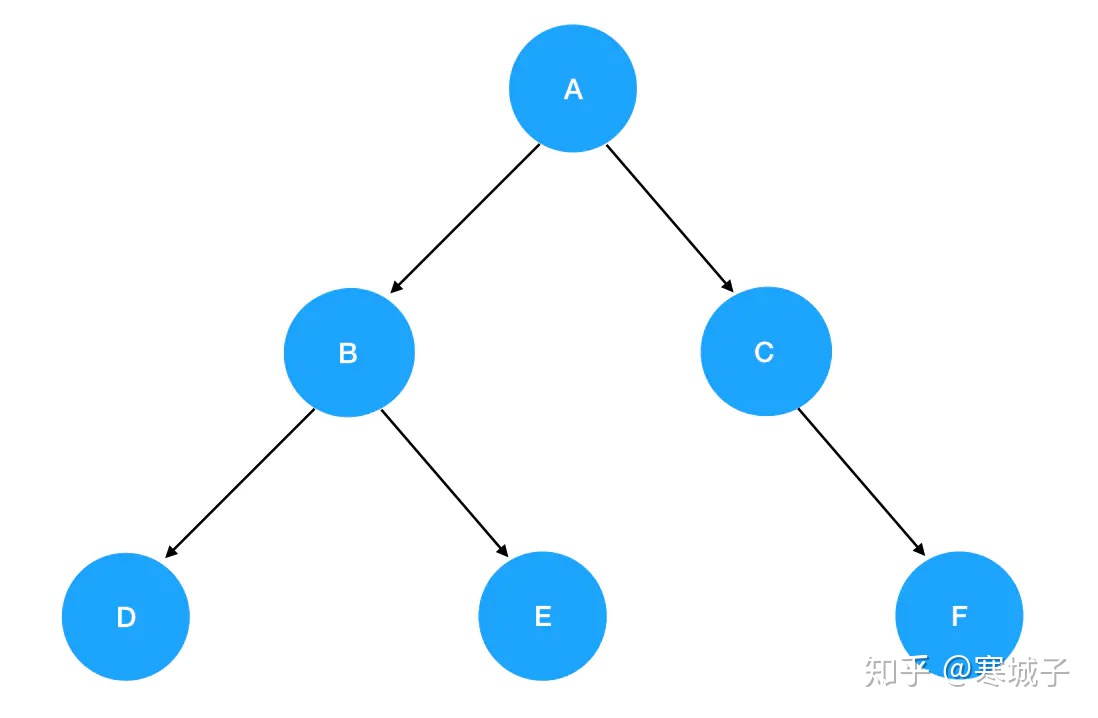
先序遍历
结果:A B D E C F
示例:
function preorder(root) {
// 递归边界,root 为空
if(!root) {
return
}
// 输出当前遍历的结点值
console.log('当前遍历的结点值是:', root.val)
// 递归遍历左子树
preorder(root.left)
// 递归遍历右子树
preorder(root.right)
}
中序遍历
结果:D B E A C F
示例:
// 所有遍历函数的入参都是树的根结点对象
function inorder(root) {
// 递归边界,root 为空
if(!root) {
return
}
// 递归遍历左子树
inorder(root.left)
// 输出当前遍历的结点值
console.log('当前遍历的结点值是:', root.val)
// 递归遍历右子树
inorder(root.right)
}
后序遍历
结果:D E B F C A
示例:
function postorder(root) {
// 递归边界,root 为空
if(!root) {
return
}
// 递归遍历左子树
postorder(root.left)
// 递归遍历右子树
postorder(root.right)
// 输出当前遍历的结点值
console.log('当前遍历的结点值是:', root.val)
}
堆
二叉树的一种,满足以下条件:
- 任意节点大于或小于它的所有子节点(大根堆、小根堆)
- 总是一完全树,即除了最底层,其它层的节点都被元素填满
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。















 699
699

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









