






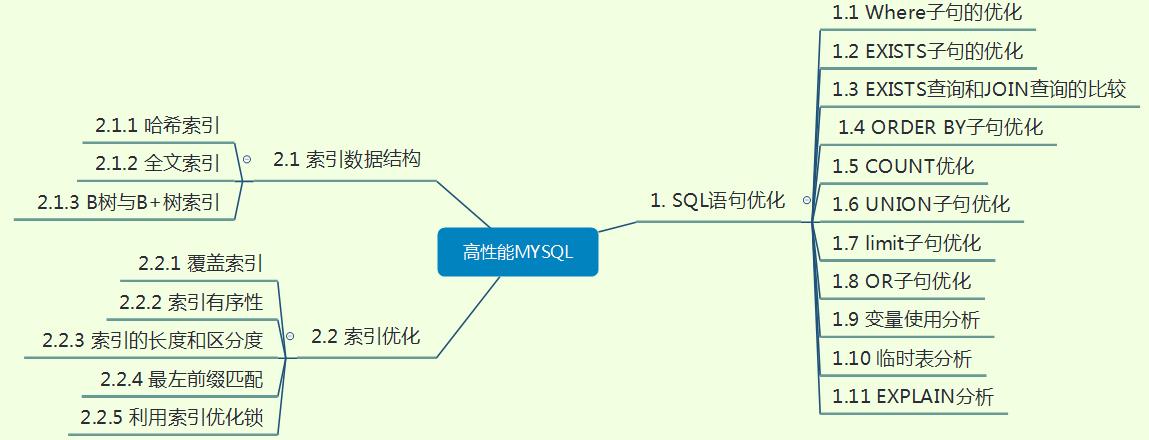
1. SQL 语句优化
1.1 Where 子句的优化
1)MySql 采用自上而下的的顺序解析 Sql 语句,最后再通过 Select 筛选出具体的列,如果有嵌套查询先查询里层,再到外层,根据这个原理,我们可以在 where 之前通过 join 连接表过滤部分数据,最后在 where 条件里过滤掉最多的数据,同时避免使用 having,having 会在 where 过滤后的记录里再次筛选,而 having 会带来排序和统计的行为,会降低查询效率
#避免使用Having
#低效的查询
SELECT col_1,col_2 FROM table_t GROUP BY col_3 HAVING col_3 >10;
#高效的查询
SELECT col_1,col_2 FROM table_t WHERE col_3 >10 GROUP BY col_3 ;
#########################################################
#过滤最多数据的条件放在where里
#低效的查询
SELECT col_1,col_2 FROM table_t WHERE username = '张三' AND 18 < (SELECT COUNT(*) FROM table_2 );
#高效的查询
SELECT col_1,col_2 FROM table_t WHERE 18 < (SELECT COUNT(*) FROM table_2 ) AND username = '张三';
2)where 子句里如果使用不等于运算符!= 或者加法运算符 + 或者字符连接运算符 || 都会无法走索引,导致效率低下
#无法使用索引
SELECT col_1 FROM table_t WHERE userage != 18;
#索引生效
SELECT col_1 FROM table_t WHERE userage <= 17 OR userage >= 19;
#这里使用<=17代替<18,效率会更高,前者直接定位到第一个等于17的记录,后者先定位到第一条等于18的记录,然后继续扫描小于18的记录
#无法使用索引
SELECT col_1 FROM table_t WHERE username || useraddress = 'ab' ;
#索引生效
SELECT col_1 FROM table_t WHERE username ='a' AND useraddress = 'b';
#无法使用索引
SELECT col_1 FROM table_t WHERE WHERE money + 1000 > 2000 ;
#索引生效
SELECT col_1 FROM table_t WHERE money > 1000;
1.2 EXISTS 子句的优化
我们先创建数据库和表,做初始化工作,如果缺乏 MySql 相关基础可以看本系列的第一篇(涵盖 MySql 基础,事务管理和锁并发的内容)
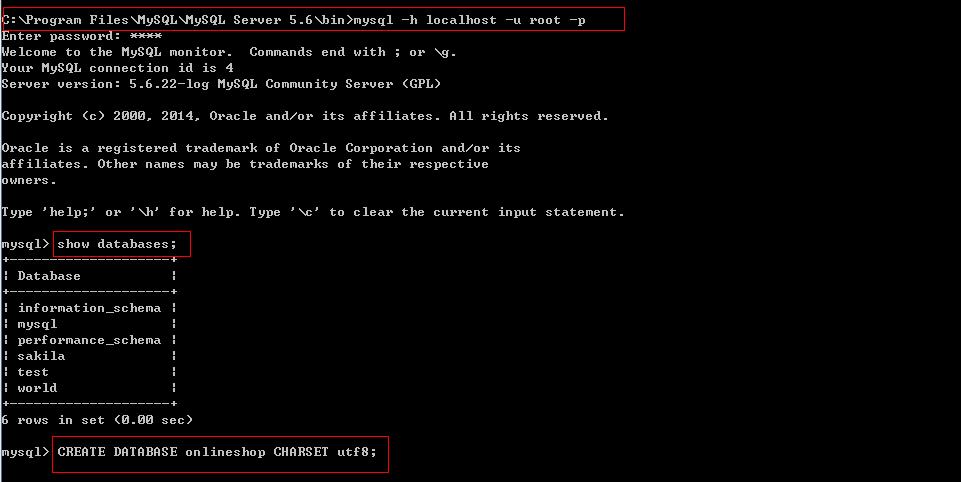
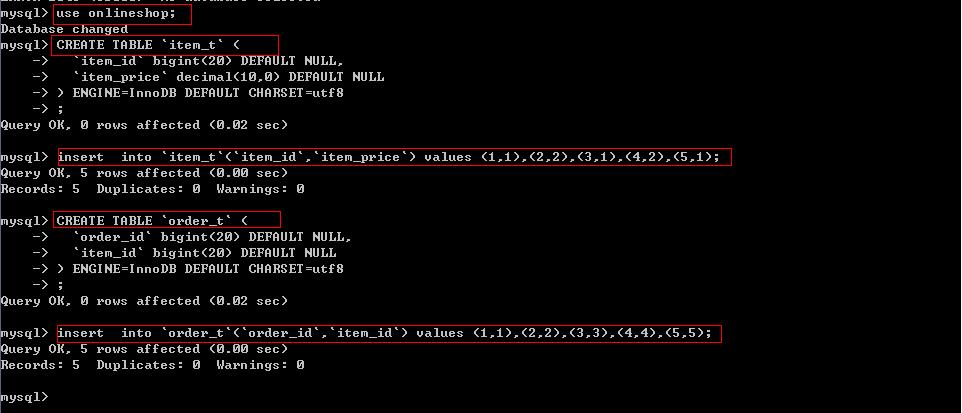
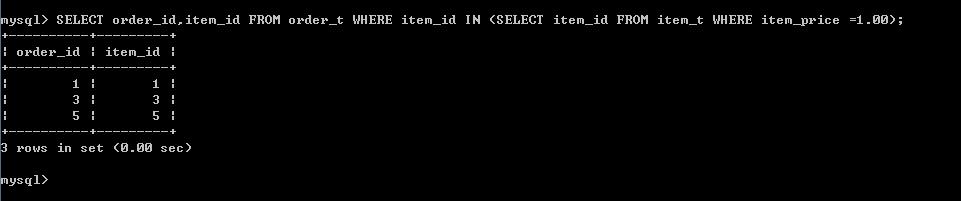
in 子查询会执行一个内部的排序,也就是 MySql 会扫描 order 全表,然后逐行跟 item 表比对,同时子查询的表也进行了一次全表遍历,找到条件 item_ price = 1.00 的行,效率是很低的,所以 MySql 内部会自动优化 in 变成 exists,我们看到的是 exists 的结果,exists 会先做子查询,筛选匹配的数据,然后做判断,存在返回 true,不存在返回 false,比 in 子查询高效(同理,用 not exists 替代 not in),但是当表数据量很大时,查询效果也不理想,这时我们可以用连接查询来代替 exists 子查询















 4440
4440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









