






这个都是以pytorch为例哦~~ 通过6部分讲解~~
为什么要使用多GPU并行训练
简单来说,有两种原因:第一种是模型在一块GPU上放不下,两块或多块GPU上就能运行完整的模型(如早期的AlexNet)。第二种是多块GPU并行计算可以达到加速训练的效果。想要成为“炼丹大师“,多GPU并行训练是不可或缺的技能。
常见的多GPU训练方法:
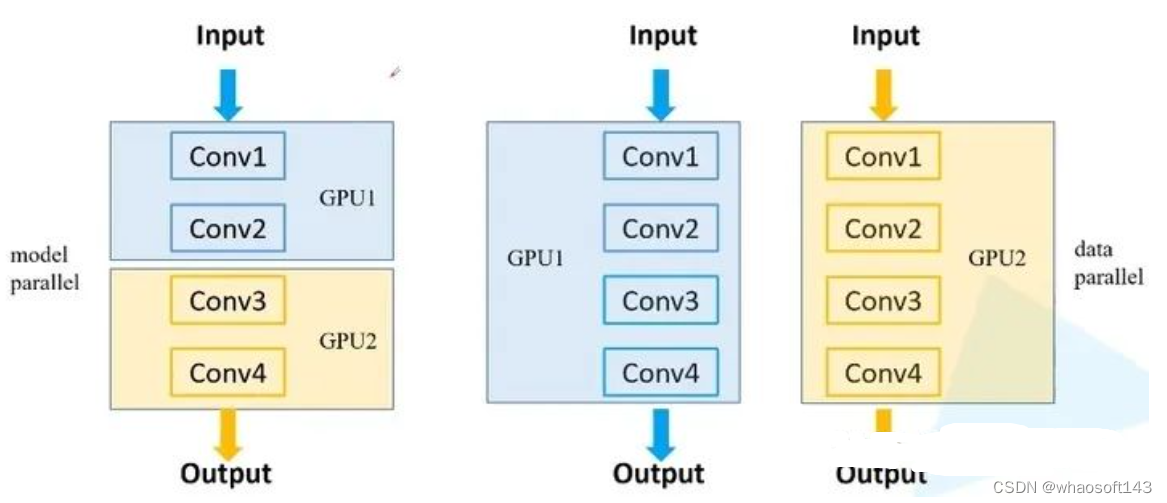
1.模型并行方式:如果模型特别大,GPU显存不够,无法将一个显存放在GPU上,需要把网络的不同模块放在不同GPU上,这样可以训练比较大的网络。(下图左半部分)
2.数据并行方式:将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播。相当于加大了batch_size。(下图右半部分)
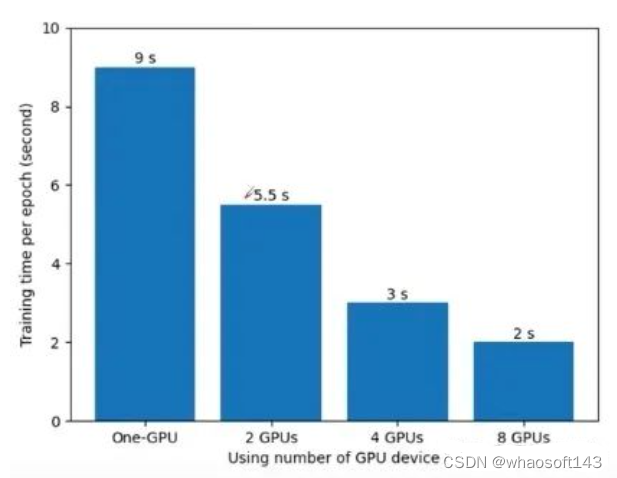
在pytorch1.7 + cuda10 + TeslaV100的环境下,使用ResNet34,batch_size=16, SGD对花草数据集训练的情况如下:使用一块GPU需要9s一个epoch,使用两块GPU是5.5s, 8块是2s。这里有一个问题,为什么运行时间不是9/8≈1.1s ? 因为使用GPU数量越多,设备之间的通讯会越来越复杂,所以随着GPU数量的增加,训练速度的提升也是递减的。
误差梯度如何在不同设备之间通信?
在每个GPU训练step结束后,将每块GPU的损失梯度求平均,而不是每块GPU各计算各的。
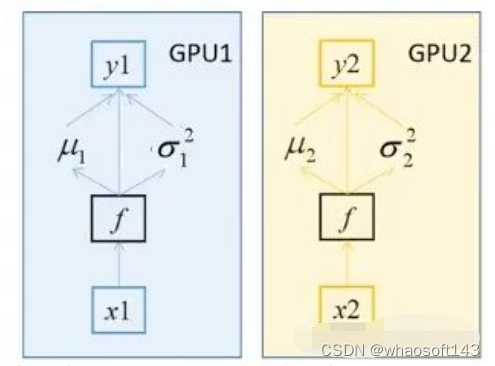
BN如何在不同设备之间同步?
假设batch_size=2,每个GPU计算的均值和方差都针对这两个样本而言的。而BN的特性是:batch_size越大,均值和方差越接近与整个数据集的均值和方差,效果越好。使用多块GPU时,会计算每个BN层在所有设备上输入的均值和方差。如果GPU1和GPU2都分别得到两个特征层,那么两块GPU一共计算4个特征层的均值和方差,可以认为batch_size=4。注意:如果不用同步BN,而是每个设备计算自己的批次数据的均值方差,效果与单GPU一致,仅仅能提升训练速度;如果使用同步BN,效果会有一定提升,但是会损失一部分并行速度。
下图为单GPU、以及是否使用同步BN训练的三种情况,可以看到使用同步BN(橙线)比不使用同步BN(蓝线)总体效果要好一些,不过训练时间也会更长。使用单GPU(黑线)和不使用同步BN的效果是差不多的。
两种GPU训练方法:DataParallel 和 DistributedDataParallel:
- DataParallel是单进程多线程的,仅仅能工作在单机中。而DistributedDataParallel是多进程的,可以工作在单机或多机器中。
- DataParallel通常会慢于DistributedDataParallel。所以目前主流的方法是DistributedDataParallel。
pytorch中常见的GPU启动方式:

注:distributed.launch方法如果开始训练后,手动终止程序,最好先看下显存占用情况,有小概率进程没kill的情况,会占用一部分GPU显存资源。
下面以分类问题为基准,详细介绍使用DistributedDataParallel时的过程:
首先要初始化各进程环境:
在main函数初始阶段,进行以下初始化操作。需要注意的是,学习率需要根据使用GPU的张数增加。在这里使用简单的倍增方法。
实例化数据集可以使用单卡相同的方法,但在sample样本时,和单机不同,需要使用DistributedSampler和BatchSampler。
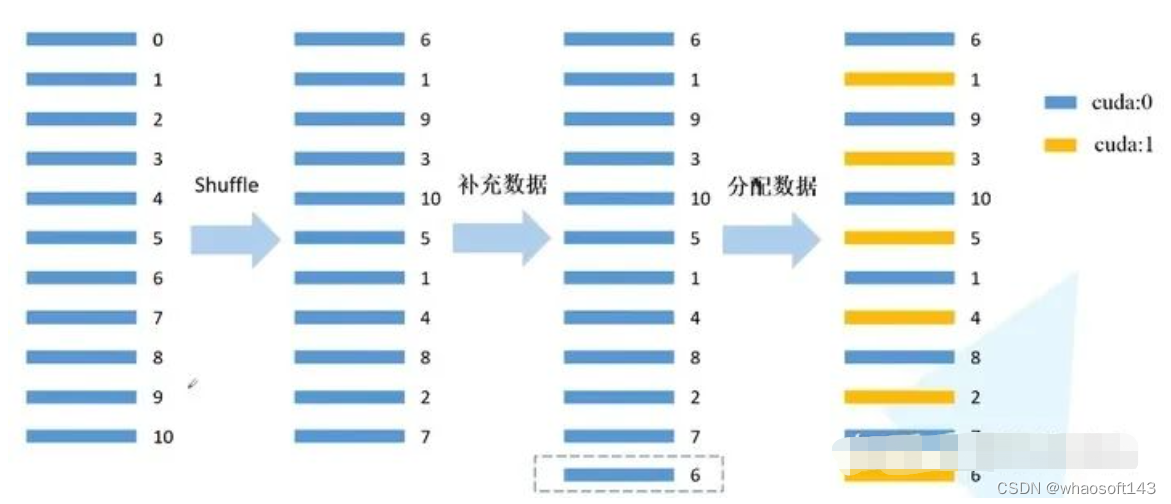
DistributedSampler原理如图所示:假设当前数据集有0~10共11个样本,使用2块GPU计算。首先打乱数据顺序,然后用 11/2 =6(向上取整),然后6乘以GPU个数2 = 12,因为只有11个数据,所以再把第一个数据(索引为6的数据)补到末尾,现在就有12个数据可以均匀分到每块GPU。然后分配数据:间隔将数据分配到不同的GPU中。
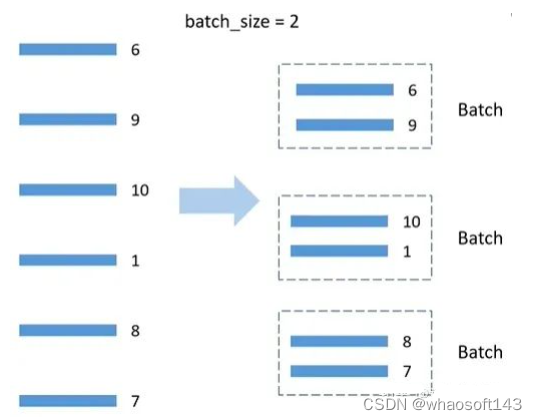
BatchSampler原理: DistributedSmpler将数据分配到两个GPU上,以第一个GPU为例,分到的数据是6,9,10,1,8,7,假设batch_size=2,就按顺序把数据两两一组,在训练时,每次获取一个batch的数据,就从组织好的一个个batch中取到。注意:只对训练集处理,验证集不使用BatchSampler。
接下来使用定义好的数据集和sampler方法加载数据:
如果有预训练权重的话,需要保证每块GPU加载的权重是一模一样的。需要在主进程保存模型初始化权重,在不同设备上载入主进程保存的权重。这样才能保证每块GOU上加载的权重是一致的:
如果需要冻结模型权重,和单GPU基本没有差别。如果不需要冻结权重,可以选择是否同步BN层。然后再把模型包装成DDP模型,就可以方便进程之间的通信了。多GPU和单GPU的优化器设置没有差别,这里不再赘述。
与单GPU不同的地方:rain_sampler.set_epoch(epoch),这行代码会在每次迭代的时候获得一个不同的生成器,每一轮开始迭代获取数据之前设置随机种子,通过改变传进的epoch参数改变打乱数据顺序。通过设置不同的随机种子,可以让不同GPU每轮拿到的数据不同。后面的部分和单GPU相同。
我们详细看看每个epoch是训练时和单GPU训练的差异(上面的train_one_epoch)
接下来看一下验证阶段的情况,和单GPU最大的额不同之处是预测正确样本个数的地方。
需要注意的是:保存模型的权重需要在主进程中进行保存。
如果从头开始训练,主进程生成的初始化权重是以临时文件的形式保存,需要训练完后移除掉。最后还需要撤销进程组。















 700
700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









