







简介:二叉树作为关键数据结构,在编译器设计、文件系统等领域有广泛应用。本课程深入讲解在VC++环境下使用C++语言对二叉树进行创建、插入、删除和遍历等操作。包括先序、中序、后序三种经典遍历方法,并探讨层序遍历以及非递归中序遍历的实现。还涉及使用图形库实现二叉树的可视化,以更直观地理解和调试代码。学生将通过实践项目,学习基本的C++语法,结构体操作,递归与循环控制,以及图形编程,全面提升编程能力。 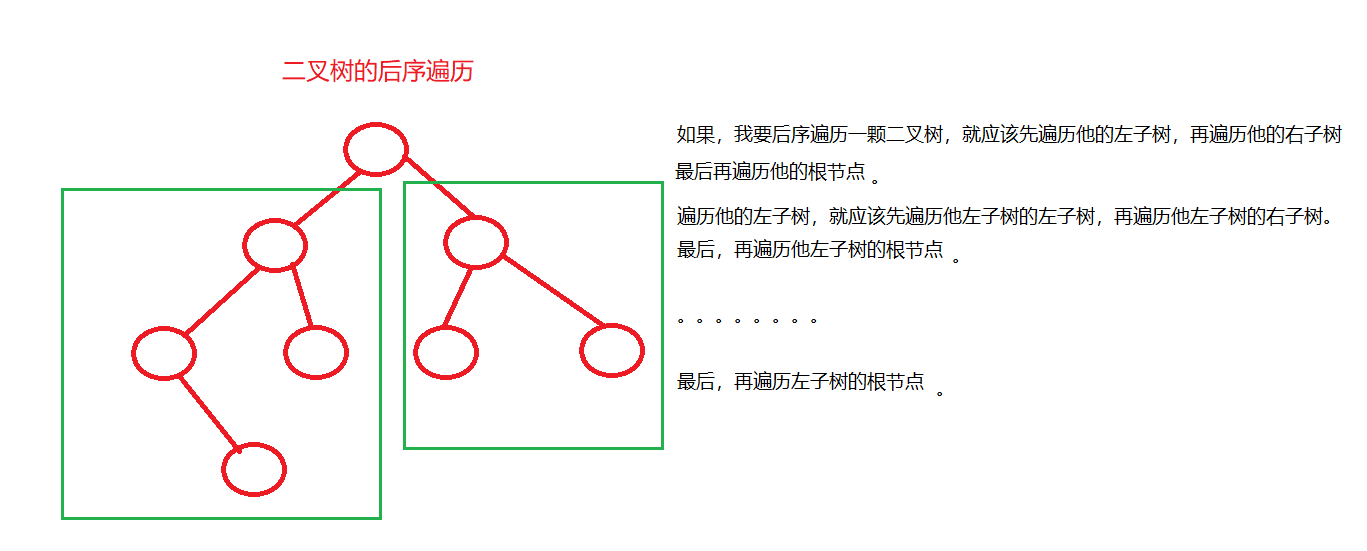
1. 二叉树数据结构介绍
1.1 二叉树基本概念
二叉树是每个节点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”。在二叉树的第五层,最多会有16个节点,呈现指数级增长。这一性质让二叉树在存储和查询方面表现优异。
1.2 二叉树的类型
- 完全二叉树:除了最后一层,其他每一层的节点数都达到最大,并且最后一层的节点都靠左排列。
- 满二叉树:每一层的节点数都达到最大。
- 平衡二叉树(AVL树):任何节点的两个子树的高度最大差别为1,这保证了树的平衡,使得搜索效率为O(log n)。
1.3 二叉树的存储方式
二叉树可以通过顺序存储或链式存储。顺序存储使用数组,需要根据完全二叉树的性质计算节点位置。链式存储则通过指针连接每个节点,更加灵活且节省空间。
以上是对二叉树基础概念和类型的概述。接下来,我们将深入探讨二叉树在不同领域的应用案例。
2.1 二叉树在计算机科学中的应用
2.1.1 数据库索引
数据库索引是利用二叉树高效组织和查询数据的典型例子。在数据库系统中,数据通常是以行的形式存储在数据文件中,而索引则提供了快速访问这些数据的能力。通过构建B树或B+树等二叉树的变种,数据库索引能够快速定位到特定的数据行。
索引的构建过程通常涉及到数据的插入、删除和查询操作,这些操作在B树中都是通过二叉树的性质来优化的。例如,当插入一个新值时,索引会找到正确的位置,保证树的有序性。这个过程中,树的平衡性至关重要,因为它直接影响到索引操作的效率。
在查询操作中,利用二叉树的性质可以实现对数据的快速查找。比如,在B树中,查找过程类似于二叉搜索树,只是每个节点可能包含多个键值和指针。树的平衡性保证了操作可以在对数时间内完成,大大提高了查询效率。
-- SQL示例:创建索引
CREATE INDEX idx_column_name ON table_name (column_name);
2.1.2 表达式解析
二叉树广泛用于计算机语言处理中的表达式解析。在解析数学表达式时,比如 2 * (3 + 4) ,可以使用二叉树来表示操作符和操作数之间的关系。这种表示方法称为抽象语法树(AST)。
在构建AST的过程中,运算符的优先级决定了树的结构。操作数通常作为叶节点,而操作符则是非叶节点。通过遍历这个树,可以有效地计算表达式的值。
// C++示例代码:创建表达式树节点
struct TreeNode {
char value;
TreeNode *left;
TreeNode *right;
TreeNode(char x) : value(x), left(nullptr), right(nullptr) {}
};
2.1.3 哈夫曼编码
哈夫曼编码是一种广泛应用于数据压缩的编码技术。它通过构建最优二叉树(哈夫曼树)来实现数据的高效压缩。在这个过程中,字符根据频率被赋予不同长度的二进制编码,频率高的字符被赋予较短的编码,频率低的字符则被赋予较长的编码。
构建哈夫曼树的过程包括将字符频率视为权值,然后通过合并权值最小的两个节点形成新节点,直到只剩下一个节点。这个过程中,二叉树的性质使得编码具有前缀性质,保证了编码的唯一可译性。
// C++示例代码:哈夫曼树节点定义
struct HuffmanNode {
char data; // 存储字符
int freq; // 字符频率
HuffmanNode *left, *right; // 左右子树指针
HuffmanNode(char data, int freq) : data(data), freq(freq), left(nullptr), right(nullptr) {}
};
2.2 二叉树在实际问题中的应用
2.2.1 人工智能决策树
在人工智能领域,决策树是一种流行的预测建模技术。它使用树形结构来代表可能的决策过程以及其可能的结果、成本或其他概率。每个内部节点代表一个属性上的测试,每个分支代表测试的结果,而每个叶节点代表一个类的标签或决策结果。
构建决策树的过程涉及特征选择、树的生成以及剪枝,以优化树的复杂度和预测性能。二叉树的性质使得决策树在分类和回归任务中都非常有用。
# Python示例代码:决策树分类器使用
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf = clf.fit(X_train, y_train) # X_train: 特征集, y_train: 标签集
2.2.2 文件系统的目录结构
在文件系统设计中,二叉树也发挥着重要的作用。特别是在Unix和类Unix系统中,目录结构通常以二叉树的形式组织,其中每个目录或文件可以看作是树中的节点。
在这样的结构中,路径名可以被解析为从根节点(通常表示为 / )到目标文件节点的一系列节点引用。二叉树的性质使得文件系统的遍历、搜索和管理变得高效。
2.2.3 游戏开发中的场景管理
在游戏开发中,场景图常常使用二叉树来组织,以便有效地进行空间分割、视锥剔除和碰撞检测。每个节点代表场景中的一个对象,而子节点则代表子对象或组件。
场景图的构建通常从根节点开始,按层次结构组织,使得渲染和逻辑更新可以高效地进行。二叉树的层次性特别适合于实现递归渲染函数。
// C++伪代码:场景图节点类定义
class SceneNode {
public:
void render() { /* 渲染逻辑 */ }
SceneNode *parent;
SceneNode *left;
SceneNode *right;
};
以上案例展示了二叉树在计算机科学和实际问题中的多样化应用,充分证明了其在算法设计和数据组织中的重要性。通过深入分析这些应用,我们可以更好地理解和掌握二叉树在解决实际问题中的强大能力。
3. VC++环境下二叉树基本操作实现
在本章中,我们将探讨如何在VC++环境下实现二叉树的基本操作,这包括定义二叉树节点、进行插入与删除操作、查找特定值,以及维持树的平衡。我们将深入分析每个操作的实现逻辑,并通过代码示例和逻辑说明,使读者能够理解并掌握如何在VC++中高效地实现这些功能。
3.1 二叉树节点的定义与创建
3.1.1 结构体定义
在C++中,二叉树的节点通常通过结构体来定义。下面是一个简单的结构体定义示例:
struct TreeNode {
int value; // 节点存储的数据
TreeNode *left; // 左子节点指针
TreeNode *right; // 右子节点指针
// 构造函数初始化节点值及指针
TreeNode(int val) : value(val), left(nullptr), right(nullptr) {}
};
逻辑说明:上述代码定义了一个名为 TreeNode 的结构体,它包含了三个成员: value 存储节点的值, left 和 right 是分别指向左右子节点的指针。在构造函数中,我们将节点值初始化为 val ,并将左右子节点指针初始化为 nullptr ,表示没有子节点。
3.1.2 节点的初始化与内存分配
创建二叉树节点时,需要正确地分配内存。以下是创建一个新节点的示例:
TreeNode* createNode(int value) {
return new TreeNode(value);
}
逻辑说明:函数 createNode 接收一个整数 value 作为参数,并返回一个指向新创建的 TreeNode 实例的指针。通过 new 关键字动态分配内存,确保节点对象在堆上创建。这样,节点的生命周期将不再局限于函数作用域,允许我们构建更大的树结构。
3.2 二叉树的插入与删除操作
3.2.1 插入算法实现
插入操作需要考虑将新节点插入到树的合适位置。以下是插入节点的伪代码:
void insert(TreeNode*& root, int value) {
if (root == nullptr) {
root = createNode(value);
} else if (value < root->value) {
insert(root->left, value);
} else {
insert(root->right, value);
}
}
逻辑说明:函数 insert 接收一个指向树根节点的引用和一个值 value 作为参数。如果根节点为空,那么直接创建一个新的节点并将其赋值给根节点。如果新值小于根节点的值,递归地在左子树中插入节点;如果大于根节点的值,递归地在右子树中插入节点。这个过程将继续直到找到合适的位置插入新节点。
3.2.2 删除节点的策略
删除节点的操作相对复杂,因为要考虑多种情况。以下是删除节点的伪代码:
void deleteNode(TreeNode*& root, int value) {
if (root == nullptr) return;
if (value < root->value) {
deleteNode(root->left, value);
} else if (value > root->value) {
deleteNode(root->right, value);
} else {
if (root->left == nullptr) {
TreeNode* temp = root->right;
delete root;
root = temp;
} else if (root->right == nullptr) {
TreeNode* temp = root->left;
delete root;
root = temp;
} else {
TreeNode* minRight = findMin(root->right);
root->value = minRight->value;
deleteNode(root->right, minRight->value);
}
}
}
逻辑说明:函数 deleteNode 首先检查根节点是否存在,如果不存在直接返回。如果要删除的值小于根节点的值,则递归地在左子树中删除节点;如果大于根节点的值,则递归地在右子树中删除节点。如果找到了要删除的节点,根据不同的情况执行以下操作:
- 如果节点没有子节点,直接删除该节点,并将父节点的指针指向
nullptr。 - 如果节点只有一个子节点,将父节点的指针指向该子节点。
- 如果节点有两个子节点,找到右子树中最小的节点,将该节点的值复制到需要删除的节点中,然后递归地在右子树中删除那个最小的节点。
3.3 二叉树的查找与平衡
3.3.1 查找特定值
在二叉树中查找特定值是基本操作之一。以下是查找节点的伪代码:
TreeNode* findNode(TreeNode* root, int value) {
if (root == nullptr || root->value == value) {
return root;
} else if (value < root->value) {
return findNode(root->left, value);
} else {
return findNode(root->right, value);
}
}
逻辑说明:函数 findNode 接收一个节点的指针和一个值 value 作为参数。如果当前节点为空或者当前节点的值等于要查找的值,则返回该节点的指针。如果要查找的值小于当前节点的值,则递归地在左子树中查找;否则,递归地在右子树中查找。
3.3.2 平衡二叉树的调整
在一些应用中,为了优化搜索操作,可能需要使用平衡二叉树,例如AVL树或红黑树。调整树的平衡通常涉及到旋转操作。以下是左旋的伪代码:
TreeNode* leftRotate(TreeNode* y) {
TreeNode* x = y->right;
TreeNode* T2 = x->left;
// 执行旋转
x->left = y;
y->right = T2;
// 更新父节点
updateParent(y, x);
return x;
}
逻辑说明:左旋操作涉及到一个节点 y 和它的右子节点 x 。我们首先保存 x 的左子节点 T2 。然后,将 x 的左子节点指针指向 y ,将 y 的右子节点指针指向 T2 。完成旋转后,需要更新 y 和 x 的父节点指针,确保树结构的完整性。
调整平衡通常需要在插入或删除操作后进行,这可能涉及一系列的旋转操作,以保持树的平衡性。由于篇幅限制,这里不再展开更多细节。
接下来的章节中,我们将深入探讨二叉树的经典遍历方法,这些方法是理解树结构和实现复杂操作的基础。
4. 二叉树经典遍历方法
4.1 先序、中序、后序遍历的递归实现
在数据结构中,遍历是实现树结构操作的基础。二叉树的遍历方法主要分为三种:先序遍历、中序遍历和后序遍历。本节将详细介绍这三种遍历方式的递归实现及其算法逻辑。
4.1.1 遍历算法的递归逻辑
递归方法是实现遍历的最直观方式。递归的思路是将问题分解为小问题,直到可以很容易地解决为止。在二叉树遍历中,递归函数通常包括三个步骤:
- 处理当前节点。
- 遍历左子树。
- 遍历右子树。
这些步骤对于三种遍历方法都是通用的,但它们处理当前节点的顺序不同。
先序遍历
先序遍历的顺序是:首先处理根节点,然后先序遍历左子树,最后先序遍历右子树。以下为伪代码:
PREORDER(node)
IF node IS NOT NULL THEN
PROCESS(node)
PREORDER(node.left)
PREORDER(node.right)
END IF
中序遍历
中序遍历的顺序是:首先中序遍历左子树,然后处理根节点,最后中序遍历右子树。中序遍历是二叉搜索树中查找节点的关键。
INORDER(node)
IF node IS NOT NULL THEN
INORDER(node.left)
PROCESS(node)
INORDER(node.right)
END IF
后序遍历
后序遍历的顺序是:首先后序遍历左子树,然后后序遍历右子树,最后处理根节点。
POSTORDER(node)
IF node IS NOT NULL THEN
POSTORDER(node.left)
POSTORDER(node.right)
PROCESS(node)
END IF
4.1.2 算法的时间复杂度分析
对于二叉树的遍历,每个节点都被访问一次,所以无论使用哪种遍历方法,其时间复杂度都为 O(n),其中 n 是节点的数量。由于递归调用的栈空间占用,空间复杂度为 O(h),h 为树的高度。
4.2 非递归中序遍历实现
非递归遍历相对于递归版本而言,不使用系统的调用栈,而是使用显式的栈结构来模拟递归过程。本节将介绍如何实现非递归的中序遍历。
4.2.1 使用栈进行遍历
非递归中序遍历使用一个栈来保存将要访问的节点。算法如下:
- 创建一个空栈。
- 将根节点作为起始节点,并将其所有左子节点压入栈中。
- 如果栈不为空,则弹出一个节点: a. 处理该节点。 b. 如果该节点有右子节点,则将右子节点及其所有左子节点压入栈中。
stack<TreeNode*> s;
TreeNode* current = root;
while (current != NULL || !s.empty()) {
while (current != NULL) {
s.push(current);
current = current->left;
}
if (!s.empty()) {
current = ***();
s.pop();
process(current); // 处理节点
current = current->right;
}
}
4.2.2 算法的迭代逻辑与优化
在上述代码的基础上,可以进行优化以减少不必要的遍历。例如,可以检查右子节点是否存在,如果存在,也需要将其所有左子节点压入栈中。
4.3 层序遍历与宽度优先搜索
层序遍历是按照树的层次,从上到下,逐层遍历的。它相当于宽度优先搜索(BFS),在处理树和图的许多问题时非常有用。本节将探讨层序遍历的实现和其在图论中的应用。
4.3.1 队列的使用与层序遍历
层序遍历使用队列来跟踪将要访问的节点。算法流程如下:
- 创建一个空队列。
- 将根节点入队。
- 当队列不为空时,从队列中出队一个节点: a. 处理该节点。 b. 将该节点的左子节点入队(如果存在)。 c. 将该节点的右子节点入队(如果存在)。
queue<TreeNode*> q;
TreeNode* current = root;
q.push(current);
while (!q.empty()) {
current = q.front();
q.pop();
process(current); // 处理节点
if (current->left != NULL) q.push(current->left);
if (current->right != NULL) q.push(current->right);
}
4.3.2 宽度优先搜索在图论中的应用
层序遍历(宽度优先搜索)在图论中同样适用。它按照与根节点的距离对节点进行排序,这在诸如最短路径等问题中非常有用。使用队列结构来实现图的宽度优先搜索,可以有效地遍历所有可达节点。
5. 二叉树的可视化与扩展技术
在数据结构的学习中,可视化技术能够帮助我们更好地理解复杂的概念和算法。二叉树作为基础且重要的数据结构之一,其可视化技术显得尤为重要。通过可视化手段,我们可以直观地看到二叉树的构建过程、数据的存储方式以及节点间的关系等。
5.1 二叉树可视化技术
5.1.1 可视化工具介绍
多种工具可用于二叉树的可视化,包括文本形式的简单输出、图形用户界面(GUI)工具,以及专门的数据结构可视化软件。其中,文本形式的可视化最为简单,通常在控制台中通过字符来表示节点和连接关系。图形用户界面工具则更为直观,常用如WinBGIm、Qt等图形库来创建窗口,并在其中绘制树形结构。
5.1.2 实现二叉树的图形化展示
为了在图形界面中展示二叉树,我们需要完成以下步骤: - 创建窗口并配置绘图环境。 - 定义节点的图形表示,例如使用椭圆形代表节点。 - 实现二叉树的遍历算法,计算每个节点在窗口中的位置。 - 在窗口中绘制二叉树的节点和连接线。 - 实现用户交互,允许用户插入、删除节点,观察这些操作对二叉树结构的影响。
5.2 VC++图形库使用
5.2.1 MFC基础与窗口创建
微软基础类库(MFC)是一个为Windows应用程序提供框架的C++库。使用MFC创建窗口的基本步骤如下:
- 定义一个继承自
CFrameWnd的派生类。 - 在派生类的构造函数中,调用基类的构造函数,并初始化窗口。
- 使用
Create函数创建窗口实例。 - 进入消息循环,处理窗口事件。
示例代码如下:
// MyFrame.h
class MyFrame : public CFrameWnd {
// 构造函数和相关成员函数定义
};
// MyFrame.cpp
MyFrame::MyFrame() {
Create(NULL, _T("二叉树可视化"), WS_OVERLAPPEDWINDOW | WS_VISIBLE,
CRect(0, 0, 800, 600), NULL, NULL);
}
// 使用MyFrame的实现文件中创建窗口实例
MyFrame theApp;
theApp.Run();
5.2.2 图形界面的绘制与事件处理
在MFC中,我们可以使用 OnPaint 函数来绘制图形界面。该函数会在窗口需要重绘时被调用。绘制二叉树时,我们通常会使用 CPaintDC 类来创建设备上下文(DC),然后使用GDI(图形设备接口)函数进行绘制。
示例代码片段:
void MyFrame::OnPaint() {
CPaintDC dc(this); // 设备上下文对象
// 绘制代码,比如绘制二叉树节点和连接线
dc.Rectangle(CRect(node_x, node_y, node_x + node_width, node_y + node_height));
dc.MoveTo(node_x, node_y);
dc.LineTo(parent_x, parent_y);
// ...更多绘图代码
}
5.3 C++基础语法与结构体操作
5.3.1 C++基础语法回顾
在实现二叉树之前,我们需要回顾C++的基本语法,如类的定义、对象的创建、指针的使用等。二叉树节点通常由结构体或类来表示,因此结构体的操作在二叉树的实现中占据重要地位。
5.3.2 结构体在二叉树中的应用
二叉树的节点可以通过结构体来定义,通常包含数据成员和指向子节点的指针。结构体的定义对二叉树的扩展和维护至关重要。
示例代码如下:
struct TreeNode {
int value;
TreeNode* left;
TreeNode* right;
TreeNode(int val) : value(val), left(nullptr), right(nullptr) {}
};
5.4 递归与循环控制结构
5.4.1 递归的原理与应用实例
递归是一种在函数定义中使用函数自身的方法,是实现二叉树遍历算法的重要手段。递归的两个基本要素是基本情况和递归步骤。在二叉树中,递归通常用于先序、中序和后序遍历。
5.4.2 循环控制结构的使用场景
尽管递归在二叉树算法中很常见,但有时候使用循环结构能提供更好的性能和更清晰的逻辑。特别是在需要手动控制栈的情况下,循环可以模拟递归过程。
5.4.3 递归与循环的效率比较
递归与循环的效率比较通常涉及时间和空间复杂度的考量。递归函数可能会导致较大的栈空间使用,特别是在深度较大的树结构中,可能会导致栈溢出。循环结构通常可以避免这种情况,但有时代码的可读性会降低。
通过本章节的介绍,我们了解了二叉树可视化的方法和工具,以及如何在VC++环境下使用图形库进行图形化展示。同时,我们也回顾了C++的基础语法以及结构体在二叉树中的应用,并对递归和循环控制结构进行了比较。在后续的章节中,我们将进一步探讨二叉树的遍历方法和应用案例。
简介:二叉树作为关键数据结构,在编译器设计、文件系统等领域有广泛应用。本课程深入讲解在VC++环境下使用C++语言对二叉树进行创建、插入、删除和遍历等操作。包括先序、中序、后序三种经典遍历方法,并探讨层序遍历以及非递归中序遍历的实现。还涉及使用图形库实现二叉树的可视化,以更直观地理解和调试代码。学生将通过实践项目,学习基本的C++语法,结构体操作,递归与循环控制,以及图形编程,全面提升编程能力。















 2150
2150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









