







执行流程
- 创建一个map函数处理一个基于key/value对的数据集合,输出中间数据,并写入磁盘
- 创建一个reduce函数来合并处理中间数据,具有相同key值的value调用被分布到多台机器上
reduce可以分布到多台机器上,例如hash(key) mod R, R为分区数目,一个job包含多个task,每个reduce任务产生一个输出文件,因此有R个输出文件。
实现模型
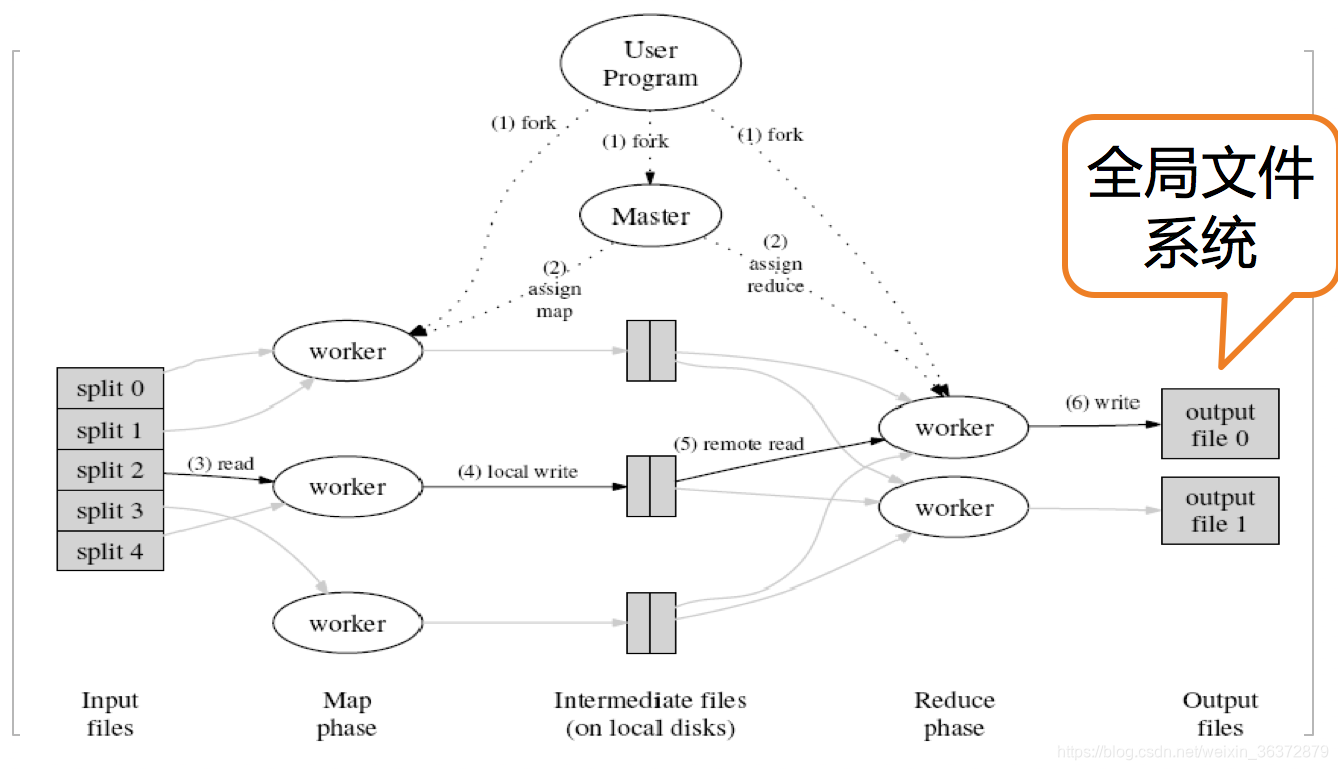
执行过程
- 首先调用MapReduce库,将输入文件分成M个数据片段(split)。用户程序在集群中创建(fork)大量程序副本。
- 程序副本中,有一个特殊的程序(master),其他程序都早worker
- map任务的workder读取相关的输入数据片段(split),从中解析出key-value对,输出并缓存在内存中
- 缓存中的key-value通过分区函数分成R个区域之后,写入到本地硬盘上,然后将存储位置传递给master
- reduce worker接收到master发来的数据存储位置,使用RPC读取数据,读取之后对key进行排序,是具有相同的key聚合在一起
- reduce worker输出
- master唤醒用户程序,对MapReduce调用返回
master执行了O(M+R)个调度,在内存中保存O(M*R)个状态














 9935
9935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









