






1 术语
Table
一个表包含多行
Row
一行包含:行键,一到多个列,列关联了值。
行是按行键(Row key)的字典顺序排序的,即按照字母顺序,或者数字大小顺序,由小到大排序。这样做是为了相关行的数据彼此相邻地存储。
行键是未解释的字节。空字节数组用来指示表名称空间的开始和结束。
Column
由Column Family和Column Qualifier构成,以:分隔。
Column Family
列族物理地组合一组列和它们的值。
每个列族有一系列存储属性,例如它的值是否应该被缓存到内存中,数据如何压缩,行键如何编码。
表中的每一行都有相同的列族,即使那行的指定列族没有存储任何值。在文件系统中,列族的所有成员都存储在一起。列族名被添加到文件系统路径。由于调谐和存储规范是在列族级完成的,因此建议所有列族成员具有基本相同的访问模式和大小特性。
Column Family必须由可打印字符组成。
Column Qualifier
可由任意二进制字符组成。
将列限定符添加到列族中,以提供给定数据块的索引。
列族是在表创建时定义的,而列限定符是可变的并且行之间的列限定符差别可以很大。
Cell
row key,Column Family、Column Qualifier构成的元组唯一确定一个Cell,Cell包含了这个元组和cell中存储的内容以及代表数据版本的时间戳(timestamp)。
Timestamp
时间戳与每个值一起写入,并且是给定版本的值的标识符。默认情况下,时间戳表示数据写入时RegionServer的时间,但当将数据放入到单元格中时,也可以指定不同的时间戳值。
2 概念视图
我们通过一个表格来展示概念视图。
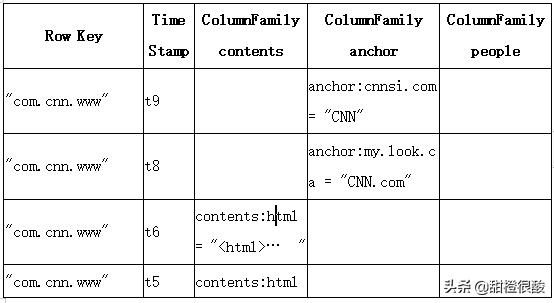
表中涉及三个列族:contents,anchor,people
第3,4,5,6行都有列contents:html,第1行有列anchor:cnnsi.com,第2行有列anchor:my.look.ca,最后一行有列contents:html和people:author。
Amandeep Khurana的文章Introduction to hbase Schema Design概要
HBase的数据模型是稀疏的、分布式的、持久稳固的多维map。这个map是a row key, column key, 和a timestamp索引的。人们认为HBase是一种键值型存储,面向列族的数据库,版本map的map。
HBase也有行和列的概念,这是与RDBMS相同的地方,但却又不同。给出一些概念:
Table:HBase将数据组织成表,表名是字符和字符的组合,表名可以被用于文件系统路径中。
Raw:一个表中数据按行存储,每一行被row key 唯一标识。Row key没有数据类型,总是被做为byte[]来对待。
Column Family:每一行内的数据按Column Family分组。Column Family名称由字符和字符的组合,表名可以被用于文件系统路径中。
Column Qualifier:Column Qualifier定位了Column Family中的数据。同Row key一样没有类型,总是被做为byte[]来对待。
Cell:ow key, column family, 和column qualifier一起标识一个Cell,数据作为Cell的值被存储在Cell中,值也是byte[]。
Timestamp:一个Cell的版本,版本由版本号标识,默认为数据写入Cell时的时间戳。如果写入数据时不指定时间戳,那么默认为当前时间的时间戳。读取数据的时候如果不指定时间戳,那么默认返回最新的一个时间戳。可以为每个列族设置单元格时间戳的数量,默认是三个。
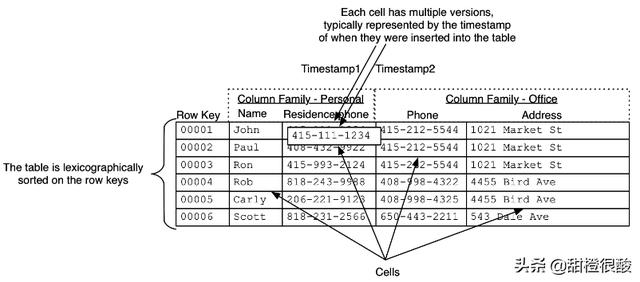
HBase API中同样包括上述概念,提供三种数据操作:Get,Put,Scan。Get和Put操作需要指定row key。
可将HBase理解为多维的Map:
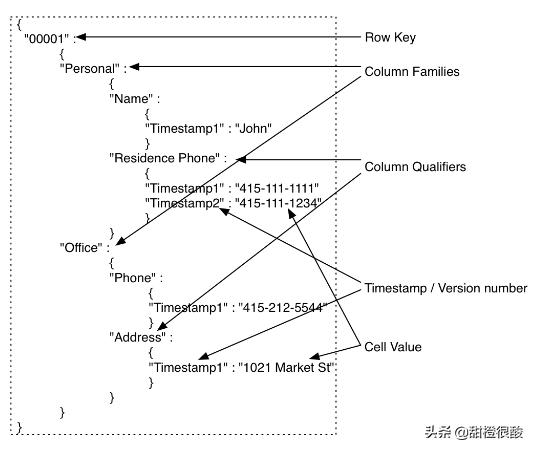
row key 映射为列族表,column family映射为column qualifier表,column qualifier映射为timestamp表,每一个timestamp映射为值。row key等价于RDBMS中的主键。
可以将HBase理解为键值对的集合。

这里键就是 row key,值就是其余的值,包括列族名,列分隔符等。
还可以将键认为是row key, column family, column qualifier, timestamp的组合,值就是实际存储在Cell中的数据。如果深入底层存储的话,就会看到,当读取指定一行的一个Cell时,最终读取的是一块数据,这块数据包含了这个cell,但同时很可能也包含了其他cell。这体现了,在HBase内部,Key被认为是[row key, column family, column qualifier, timestamp],值就是实际存储在Cell中的数据。
HBase表设计原理
设计HBase表就是回答如下问题:
1)row key的结构是怎样的,包含什么。
2)应该有多少个列族
3)列族包含什么样的数据
4)每个列族多少个列
5)列名是什么,尽管不必事先定义好列名。
6)Cell中的值是什么
7)每个cell有几个版本
需要注意的几点:
1)索引仅存在于Key上,这里的key就是上文说的[row key, column family, column qualifier, timestamp]。
2)按row key键排序的,表的每个Region负责row key空间的一部分,并有开始row key 和结束row key指定范围。
3)HBase中存储的任何值都是byte[]。除此之外无别的类型。
4)只有行级的原子性,没有跨行的原子性,意味着不支持多行事物。
5)表创建的时候就要定义列族。
3 物理视图
ColumnFamily anchor

ColumnFamily contents
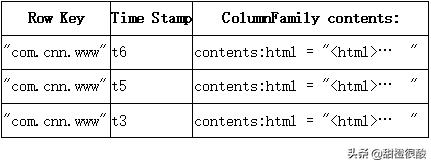
在概念视图中的空单元不会被存储,一个列族的数据会存储在一起。
4 Namespace(名称空间)
名称空间从逻辑上将表分组,与RDBMS中的数据库概念相似。这种抽象概念为即将实现的多租户相关特性(multi-tenancy related features)奠定了基础:
· 配额管理(HBASE-8410)-限制命名空间可消耗的资源量(即Regions、Tables)
· 命名空间安全管理(Hbase9206)-为租户提供另一级别的安全管理。
· Region服务器分组(HBASE-6721)-一个名称空间或表可被限制在RegionServer的子集范围内,这样能够确保粗粒度的隔离。
命名空间可以被创建,删除,修改。
创建名称空间my_ns:create_namespace 'my_ns'
在指定的空间my_ns中建表my_table:create 'my_ns:my_table', 'fam'
删除名称空间:drop_namespace 'my_ns'
修改名称空间:
alter_namespace 'my_ns', {METHOD => 'set', 'PROPERTY_NAME' => 'PROPERTY_VALUE'}
有两类预定义的Namespace:
hbase:系统命名称空间,用于包含HBase内部表。
default:创建表时,如果没有为表指定命名空间,系统会指定一个默认的命名空间,即default。
5 Versions(版本)
版本是一个指定的长整型数。例如使用方法java.util.Date.getTime() 或System.currentTimeMillis()获得的值。这两个方法返回值格式为:
the number of milliseconds since January 1, 1970, 00:00:00 GMT。
所以和本地时间是不同的。
HBase版本是降序排列的,因此访问HBase时,最新的数据首先被找到。
如果对一个Cell的多个写操作使用了相同的版本,最后执行的写操作结果可访问。
执行对一个Cell的写操作时,版本可以不是增大的。
指定版本数量
一列可包含的版本的最大数量是列模式的一部分,并且在创建表的时候指定,或者使用alter修改,或者使用HColumnDescriptor.DEFAULT_VERSIONS(3.0版本将要移除,使用ColumnFamilyDescriptorBuilder)修改。0.96及之后的版本默认为1,之前的版本默认为3。
hbase> alter ‘t1′, NAME => ‘f1′, VERSIONS => 5
可以为一个列族指定版本的最小数量,HBase 0.98.2起,可以为新创建的列指定全局默认的版本数量的最大值,即配置hbase-site.xml中的hbase.column.max.version。
版本与操作
Get/Scan
使用Table.get
Get操作是在Scan操作基础上实现的。
执行Get操作而没有明确指定版本,那么返回的是拥有最大值版本号的Cell,但这个Cell值可能不是最新写入的数据。
通过以下设置可以改变默认的行为:
Get.setMaxVersions()设置返回多个版本。
Get.setTimeRange()设置不返回最新版本。
例:
public static final byte[] CF = "cf".getBytes();
public static final byte[] ATTR = "attr".getBytes();
...
Get get = new Get(Bytes.toBytes("row1"));
get.setMaxVersions(3); // 将返回最新的三个版本
Result r = table.get(get);
byte[] b = r.getValue(CF, ATTR); //返回当前版本的值
List kv = r.getColumn(CF, ATTR);//返回所以版本的值
Put
如果键(由行、列族、列限定符、版本号共同定位一个键)存在就更新,不存在就插入新行。使用Table.put或Table.batch。
Put操作总是产生新的版本号,即某个时间戳。默认地Put操作使用服务器的System.currentTimeMillis()值作为版本号。可以自己指定版本(一个长整型),这意味着可以指定过去或者将来的时间,或使用一个和时间无关的长整型。
最好不要自己指定时间戳,因为HBase内部使用会使用这个时间戳,例如用他计算生命周期。
Delete
从表中删除一行,使用Table.delete。
HBase没有修改指定值的操作,因此处理删除操作的策略是通过创建一个被称为墓碑的标记实现的。这些墓碑联同已删除的数据会在执行大合并(major compactions)时被清除。
当删除一行数据时,HBase会为这一行的每一个列族设置一个墓碑标记。删除一行同时指定了版本或者使用System.currentTimeMillis(),意味着会删除所有小于等于此指定版本的Cell。如果指定的版本比任何版本都大,那么整行会被删掉。
有三种内部删除标识:
删除一列的指定版本,删除一列的所有版本,删除指定列族(列族被删除了,意味着属于这个列族的所有列都被删除了)。
如果为列族设置KEEP_DELETED_CELLS选项,那么删掉的Cell会被保留而不会真正删除。
通过hbase.hstore.time.to.purge.deletes设置可配置时间量,如果没有设置这个值或者将其设置为0,下次发生大合并时数据和标记都会被清除。否则当大合并发生在(毫秒为单位)
deletetime = timestamp +hbase.hstore.time.to.purge.deletes
之后时,数据会被删除。其中timestamp 为墓碑标记。
当前的限制
下面这些限制在hbase-2.0.0中已经解决。
Delete操作覆盖Put操作
即使Put操作在Delete之后发生,那么起作用的还是Delete。删除操作会写一个墓碑标识,只有下次大合并的时候才会处理墓碑和数据。一个put操作即使是在delete之后提交的,那么当put操作成功后,使用Get依然无法访问数据。这样只有在大合并发生以后Put操作才又起作用。如果你总是使用增大的版本号,那么Put操作总会起作用的。
大合并改变查询结果
创建一个Cell,有三个版本t1,t2,t3,最大版本数设置为2,那么只会返回t2,t3,如果删除t2或t3,t1才会出现。
可选的新版本和在HBase-2.0.0中删除的特性
在hbase-2.0.0中可以通过设置列的NEW_VERSION_BEHAVIOR属性为true 指定备用版本和删除操作(为了设置column family descriptor的属性,一定要先对表disable,然后再改变column family descriptor的属性)。
hbase-2.0.0版本消除了之前的一些限制,hbase-2.0.0的新特性如下:
Delete操作总是覆盖Put操作
如果Delete和Put这两个操作作用于同一个位置,即:相同的row, column family, qualifier 和timestamp ,不论哪一个先到达服务器,总是Delete起作用。
大合并不会改变查询结果
版本记帐也会因为版本被删除而考虑到版本总数的变化。这是为了确保在大合并(major compaction)情况下不会改变结果。
考虑到Cell MVCC,会耗费更多的CPU,测试来看会慢0%-25%。
如果进行复制,建议运行新的串行复制特性(hbase-2.0.0中没有这个特性,以后的版本或许会添加)。
文章Bending time in HBase选读
可以认为时间是HBase数据版本自动化控制机制。
在BigTable这篇论文中使用{row key, column key}来映射一个cell。每个cell包含了多个版本,由timestamp索引。
HBase基本不会重写数据,而仅仅是追加。通过压缩处理过程,数据文件偶尔会重写。数据文件是基本的键值对集合,键是{row key, column key, time}(column key应该包含两部分:Column Family和Column Qualifier)。每次当使用Put向已有cell中写数据时,新的键值对被追加到存储文件,即使指定已有时间戳也是如此。依赖于垃圾收集设置,废弃的数据将在大合并期间被清除。
有两种自动的版本清理机制:
如果指定最大版本,那么当数据版本超过这个设置时,最老的版本会被删除(标记删除)
指定TTL,如果版本比TTL老,那么会被删除。
6 Sort Order(排序)
所有的对HBase数据模型的操作返回值都是经过排序的。排序顺序依次为:Row(RowKey),ColumnFamily,Column Qualifier,Timestamp。
7 Column Metadata(列元数据)
不会在列族内部键值对实例之外存储任何列元数据。获得一个列族的所有列的方式就是访问所有行。
8 Joins(联接)
HBase不支持如同RDBMS一样的联接特性,但可以通过其他的方式实现相似的功能。
有两种策略:
一是将关联数据写入一张表,形成一张“宽表”。
二是在应用层实现表联接,例如使用MapReduce。
9 ACID
原子性(Atomicity):一个操作要么全成功,要么全失败。
一致性(Consistency):所有操作导致表直接从一个有效状态转换到另一个有效的状态。
隔离性(Isolation):数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。
持久性(Durability):一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
可见性(Visibility):对于一个update操作,如果后续的读操作可以获得update已提交的数据,那么这个update就是可见的。
HBase不是一种遵从ACID的数据,但他具有一些特性。
涉及到的API
Read APIs:get,scan
Write APIs:put,batch put,delete
Combination (read-modify-write) APIs:incrementColumnValue,checkAndPut
Atomicity
1)所有的改变都是具有行原子性。操作返回success那么操作全部成功;返回failure操作全部失败;如果操作超时,要么全成功,要么全失败。
2)即使改变涉及到一行的多个列族,依然具有行原子性。
3)不具有多行原子性。例如一个插入多条数据的操作,可能只成功修改了部分行。这种与批量插入操作相关的API会返回一个成功表示成功代码的列表,但其实有的记录插入成功,有的失败,有的超时。
4)checkAndPut和compareAndSet (CAS)操作很像。
5)每一行的突变有明确的顺序,而不会出现交叉的情形。例如,写入a=1,b=1,c=1,另一个写入操作为a=2,b=2,c=2,那么对此行来说,要么是a=1,b=1,c=1,要么是a=2,b=2,c=2,但一定不会类似于a=1,b=2,c=1这种情形。要注意,这种特性只是针对单行,对于多行不适用。
Consistency和Isolation
1)通过API访问会获得整行数据。当调用API返回多行时,只获取了某行的一部分数据这种情况是不可能发生的。
2)对于列族亦是如此。例如获得整行数据的get操作执行的同时,发生了许多突变1,2,3,4,5(可以理解为突变的序号是1,2,3,4,5),此get操作会返回完整的一行,这行数据已经存在于突变i与突变i+1之间的某一时间点,i取值范围是从1到5。
3)在整个的编辑历史中,行的状态之后向前移动。
Scans的Consistency
Scan不是表的一致性视图,也不会展示快照隔离。但其具有如下特性:
1)通过Scan返回的任何行都是一个一致视图(例如,整行的版本存在于某个时间点)
2)Scan所体现的数据的视图总是和Scan开始执行的时候一样新。为实现这一特性,必须满足一下规则:
A) 例如,如果客户端A插入数据X,然后客户端B与服务器通信,客户端B发起的任何Scan包含的数据和X一样新。
B) 一个scan必须能够反映scanner创建之前提交的所有突变,并可能会反映scanner创建之后提交的突变。
C) Scan必须包括scan之前所有写入的数据(除了scan之后数据发生了改变,这种情况下,反映的可能是数据的变化)。
这和关系型数据库的读隔离级别相似。
Visibility
1) 当某一客户端的对突变的响应为success,那么随后这一客户端和所有通过旁通道与HBase通信的客户端都能看到这一突变。
2) 一行一定不能展现被称为时间旅行的特性。意思就是,如果一系列的突变使一行的状态连续地变化,那么任何一系列并发读都将返回这些状态的子序列。例如使用incrementColumnValue操作一行的多个cell,那么客户端一定不能看到任何被删掉的cell,不论在突变发生后使用API的哪个读操作。
3) 读操作返回的一个cell的任何版本保证是持久化的。
Durability
1)所有可见的数据都是持久化数据,也就是说永远不会读取不在磁盘上的数据。
4) 任何返回success的操作(增删改,且操作不抛异常)都会被持久化。
5) 任何返回failure的操作都不会被持久化。
6) 所有合理的失败情景都不会影响到本文档的其他保证。
Tunability
有时处于性能的考虑,hbase提供了几个调节参数:
1)Visibility被调整为每次读取都可以stale reads或time travel。
2)Durability可能被调整为周期性的。
注解
1)intra-row scanning不保证一致视图,例如一个RPC调用获取一行的一部分,接下来的RPC调用获得另一部分。当你设置一个限制Scan.next(Scan.setBatch(int batch)设置)能返回多少值时,Intra-row scanning就会发生。
2)在HBase的上下文中,持久化到磁盘意味着hflush()调用了事物日志。实际上并不意味着数据被刷写到磁性介质上了,而仅仅是数据被写入操系统缓存在所有日志副本上。整个数据中心停电的情况下,编辑的内容可能没有真正被持久化。
3)Puts操作要么全成功要么全失败,假如他们真的被发送给RegionServer。如果使用了writebuffer,直到writebuffer被填满或者明确地执行flushed,那么Puts才会被发送给RegionServer。















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









