






1、python手动实现二维卷积(一种丑陋但容易背的写法)
2、pytorch手动实现自注意力和多头自注意力
- 自注意力
- 多头自注意力
3、图像缩放
步骤:
- 通过原始图像和比例因子得到新图像的大小,并用零矩阵初始化新图像。
- 由新图像的某个像素点(x,y)映射到原始图像(x’,y’)处。
- 对x’,y’取整得到(xx,yy)并得到(xx,yy)、(xx+1,yy)、(xx,yy+1)和(xx+1,yy+1)的值。
- 利用双线性插值得到像素点(x,y)的值并写回新图像。
双线性插值实现:将每个像素点坐标(x,y)分解为(i+u,j+v), i,j是整数部分,u,v是小数部分,则f(i+u,j+v) = (1-u)(1-v)f(i,j)+uvf(i+1,j+1)+u(1-v)f(i+1,j)+(1-u)v* f(i,j+1)。
opencv实现细节:将新图像像素点映射回原图像时,SrcX=(dstX+0.5)* (srcWidth/dstWidth) -0.5,SrcY=(dstY+0.5) * (srcHeight/dstHeight)-0.5,使得原图像和新图像几何中心对齐。因为按原始映射方式,55图像缩放成33图像,图像中心点(1,1)映射回原图会变成(1.67,1.67)而不是(2,2)。
4、图像旋转实现
旋转矩阵:
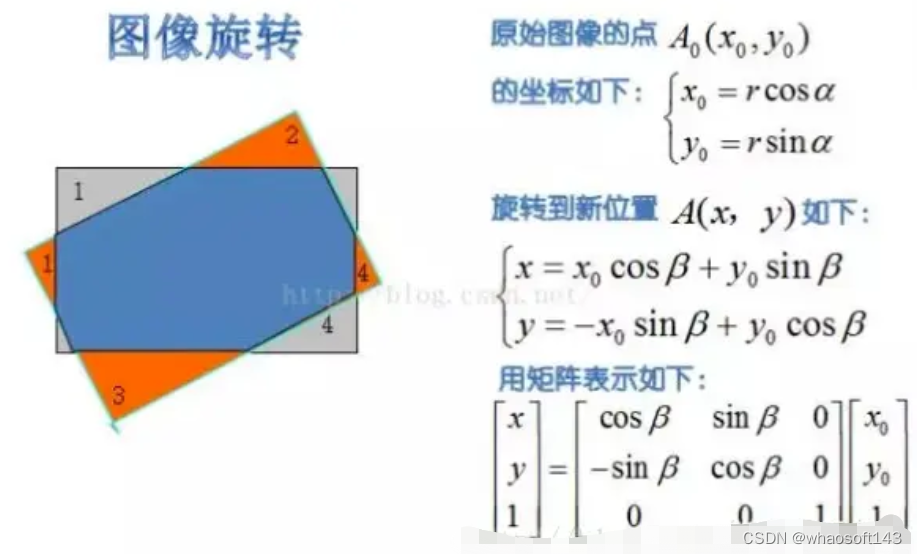
实现思路:
- 计算旋转后图像的min_x,min_y,将(min_x,min_y)作为新坐标原点(向下取整),并变换原图像坐标到新坐标系,以防止旋转后图像超出图像边界。
- 初始化旋转后图像的0矩阵,遍历矩阵中每个点(x,y),根据旋转矩阵进行反向映射(旋转矩阵的逆,np.linalg.inv(a)),将(x,y)映射回原图(x0,y0),同样将x0和y0拆分为整数和小数部分:i+u,j+v,进行双线性插值即可。从而得到旋转后图像每个像素(x,y)的值。
5、RoI Pooling实现细节
RoI Pooling需要经过两次量化实现pooling:
第一次是映射到feature map时,当位置是小数时,对坐标进行最近邻插值。
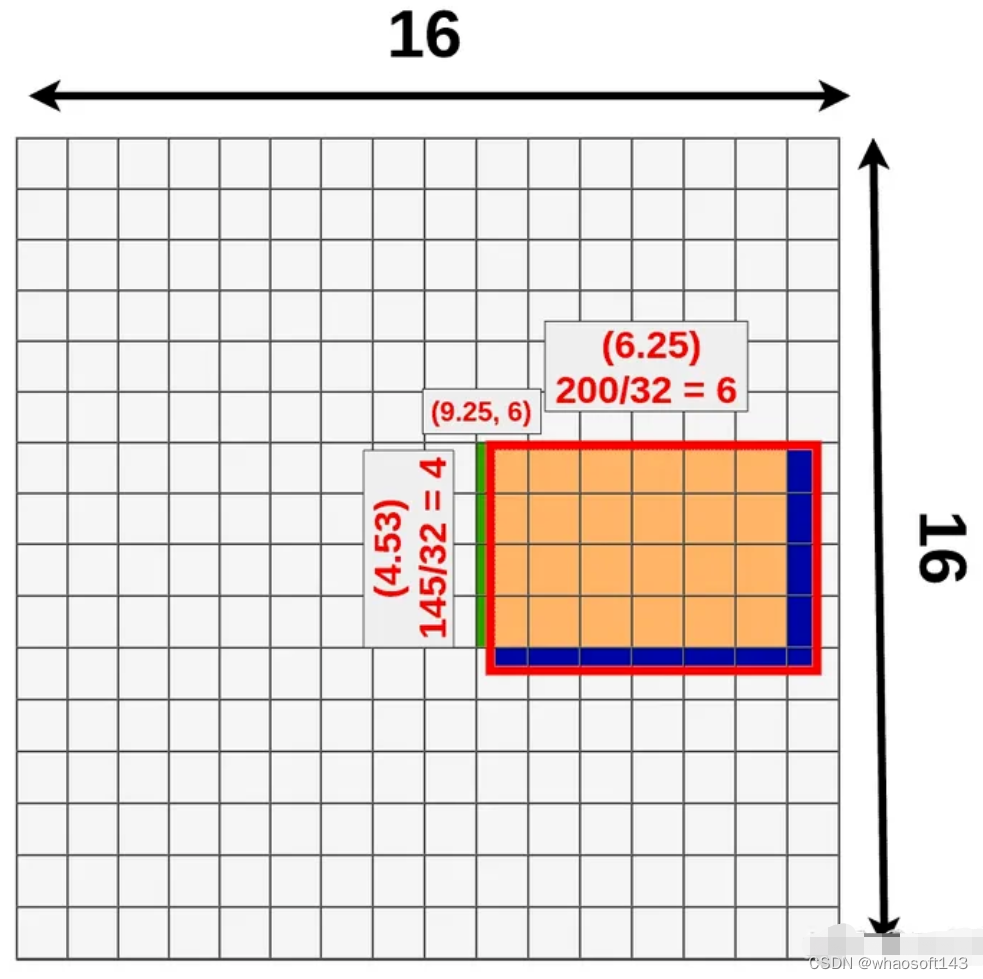
第二次是在pooling时,当RoI size不能被RoI Pooling ouputsize整除时,直接舍去小数位。如4/3=1.33,直接变为1,则RoI pooling变成对每个1* 2的格子做pooling,pooling方式可选max或者average。
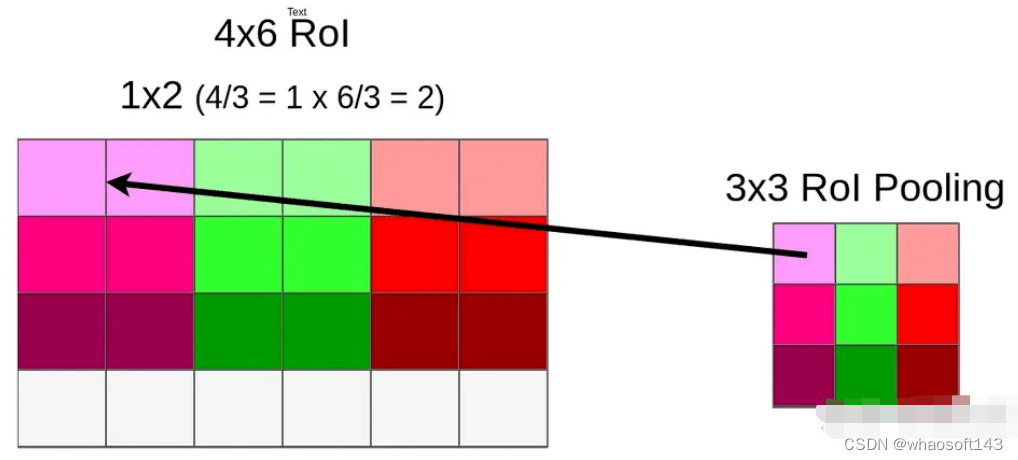
6、RoIAlign实现细节
RoIAlign采用双线性插值避免量化带来的特征损失:
将RoI平分成outputsize* outputsize个方格,对每个方格取四个采样点,采样点的值通过双线性插值获得,最后通过对四个采样点进行max或average pooling得到最终的RoI feature。
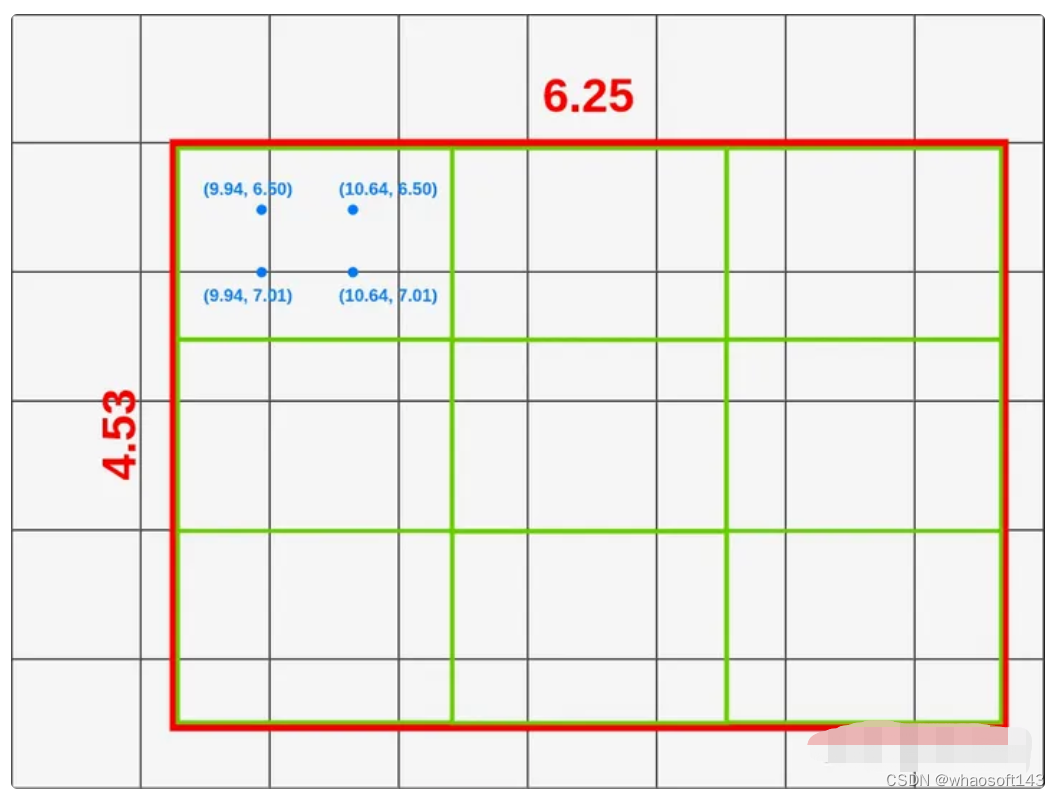
7、2D/3D IoU实现
8、手撕NMS















 9532
9532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









