







首先训练过程就不再多说了,训练完之后会得到最重要的两个文件,
一个是网络结构文件 deploy.prototxt ,一个是训练完的权重文件,我使用的是NVcaffe+digits训练工具训练,
经过多次的训练,目前准确度达到84%,如下图
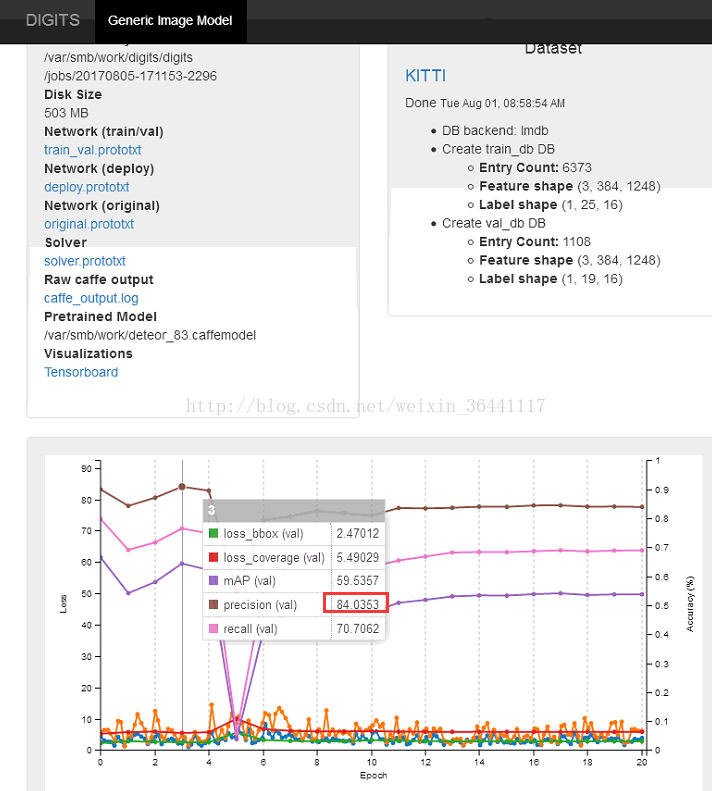
可以看出叠代3是准确度最高的,因此我们下载这次的叠代结果
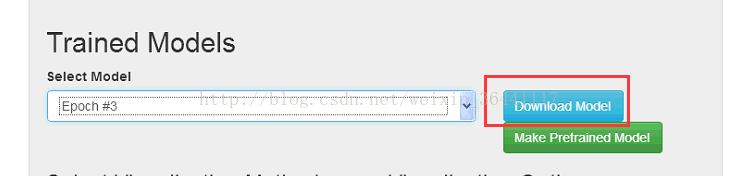
下载完之后就可以得到权重文件与结构文件
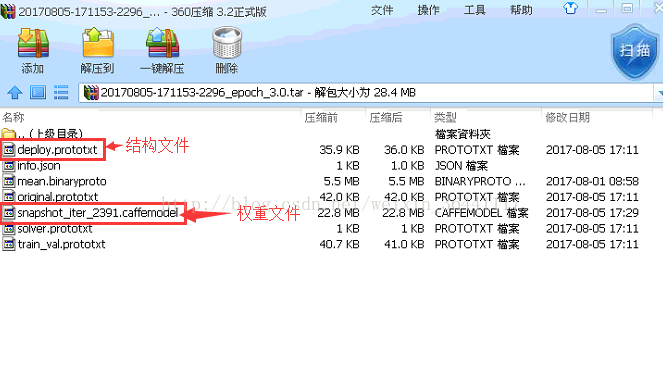
再来撰写代码
# -*- coding:utf-8 -*-
# 用于模型的单张图像分类操作
import os
os.environ['GLOG_minloglevel'] = '2' # 将caffe的输出log信息不显示,必须放到import caffe前
import caffe # caffe 模块
from caffe.proto import caffe_pb2
from google.protobuf import text_format
import numpy as np
import cv2
import matplotlib.pyplot as plt
import time
# 分类单张图像img
def detection(img, net, transformer):
im = caffe.io.load_image(img)
net.blobs['data'].data[...] = transformer.preprocess('data', im)
start = time.clock()
# 执行测试
net.forward()
end = time.clock()
print('detection time: %f s' % (end - start))
# 查看目标检测结果
#print(net.blobs['bbox-list'].data)
loc = net.blobs['bbox-list'].data[0]
#查看了结构文件发现在CAFFE一开始图像输入的时候就已经将图片缩小了,宽度1248高度384
#然后我们在net.blobs['bbox-list'].data得到的是侦测到的目标座标,但是是相对于1248*384的
#所以我们要把座标转换回相对原大小的位置,下面im.shape是保存在原尺寸的宽高,
for l in range(len(loc)):
xmin = int(loc[l][0] * im.shape[1] / 1248)
ymin = int(loc[l][1] * im.shape[0] / 384)
xmax = int(loc[l][2] * im.shape[1] /1248)
ymax = int(loc[l][3] * im.shape[0] / 384)
#在该座标位置画一个方框
cv2.rectangle(im, (xmin, ymin), (xmax, ymax), (55 / 255.0, 255 / 255.0, 155 / 255.0), 2)
# 显示结果
plt.imshow(im, 'brg')
plt.show()
#CPU或GPU模型转换
#caffe.set_mode_cpu()
#caffe.set_device(0)
caffe.set_mode_gpu()
caffe_root = '/var/smb/work/mycode/'
# 网络参数(权重)文件
caffemodel = caffe_root + 'module/detectnet/snapshot_iter_2391.caffemodel'
# 网络实施结构配置文件
deploy = caffe_root + 'module/detectnet/deploy.prototxt'
img_root = caffe_root + 'data/'
# 网络实施分类
net = caffe.Net(deploy, # 定义模型结构
caffemodel, # 包含了模型的训练权值
caffe.TEST) # 使用测试模式(不执行dropout)
# 加载ImageNet图像均值 (随着Caffe一起发布的)
print(os.environ['PYTHONPATH'])
mu = np.load(os.environ['PYTHONPATH'] + '/caffe/imagenet/ilsvrc_2012_mean.npy')
mu = mu.mean(1).mean(1) # 对所有像素值取平均以此获取BGR的均值像素值
# 图像预处理
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', mu)
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
# 处理图像
#while 1:
img = caffe_root + 'data/peds-001.jpg'
detection(img,net,transformer)
建议看上面这份代码的时候连同结构一起看,代码中loc = net.blobs['bbox-list'].data[0]
其中的bbox-list 是在结构文件最后面的一个数据保存检测到目标的座标
input: "data"
input_shape {
dim: 1
dim: 3
dim: 384 //这个就是图片预处理时就先将高度缩放到384
dim: 1248 //这个就是图片预处理时就先将宽度缩放到1248
}layer {
name: "deploy_transform"
type: "Power"
bottom: "data"
top: "transformed_data"
power_param {
shift: -127.0
}
}
.............为了减少篇幅此处省略一大部分代码....................
layer {
name: "bbox/regressor"
type: "Convolution"
bottom: "pool5/drop_s1"
top: "bboxes"
param {
lr_mult: 1.0
decay_mult: 1.0
}
param {
lr_mult: 2.0
decay_mult: 0.0
}
convolution_param {
num_output: 4
kernel_size: 1
weight_filler {
type: "xavier"
std: 0.03
}
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "cluster"
type: "Python"
bottom: "coverage"
bottom: "bboxes"
top: "bbox-list" //这里是最后输出的数据,实际上就是目标的座标
python_param {
module: "caffe.layers.detectnet.clustering"
layer: "ClusterDetections"
param_str: "1248, 352, 16, 0.6, 3, 0.02, 22, 1"
}
}

可以看出确实将车子的部份框出来了















 2796
2796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









