






绪论
本合集将详细讲述如何实现基于群只能遗传算法的五子棋AI,采用C++作为底层编程语言
本篇将简要讨论实现思路,并在后续的文中逐一展开
了解五子棋
五子棋规则
五子棋是一种经典的棋类游戏,规则简单却充满策略性。游戏在一个19×19的棋盘上进行(也可以使用13×13或15×15的棋盘)。游戏的目标是率先在棋盘上连成五个相同颜色的棋子(横向、纵向或斜向)。
基本规则:
- 棋子:游戏使用两种颜色的棋子,通常为黑白两色。
- 落子:玩家轮流在棋盘上放置自己的棋子。
- 胜利条件:第一个在直线上(横向、纵向或对角线)连成五个棋子的玩家获胜。
五子棋操作简单,规则易懂,但需要很高的策略和技巧才能赢得比赛。
人类玩家是如何下五子棋的?
以下是一些五子棋对决的思路:
控制中心区域
- 中心位置的重要性:棋盘中心的控制对游戏至关重要。控制中心区域可以给你更多的机会去创建和阻止对方的五子连线。
创建威胁
- 连线威胁:尽量让对方必须防守而不能专注于自己的进攻。
- 双活三:如果形成两个三子连线,并且这两个连线不会被对方轻易阻挡,就能够在几步内取得胜利。
防守对方的连线
- 观察对方的棋子布局:注意对方棋子的排列,尤其是对方试图形成的三子、四子连线。
- 及时阻挡:如果对方有连续的三子或四子的排列,应该优先阻挡对方的连线。
预判对方策略
- 猜测对方意图:了解对方的策略,预测对方的下一步棋,提前做出相应的防御或进攻。
AI应该如何模仿?
为了让AI棋手学会下五子棋,甚至超越人类玩家的水平,首先应当有以下步骤:
-
理解棋盘信息:将棋盘的状态转换为程序能够处理的格式。这通常包括将棋盘上每个位置的状态(如空白、黑子或白子)编码为特定的数据结构,以便程序可以进行分析和处理。
-
设定行为集合:定义AI可以执行的操作范围。在五子棋中,AI可以在棋盘上任意未被占据的位置落子。
-
设定决策模式:确定AI的决策方式。本例中,AI采用贪心策略,即在每一步中选择预期回报最高的行动。贪心策略通过评估每个可能的落子位置的即时收益,选择对当前局势最有利的行动。
理解棋盘信息
理论上来讲,能够给AI提供的信息越多,那么AI做出的决策质量就越高,对于棋盘信息可以以格子为单位,评估该格子对于己方、和敌方的价值。
举例来说,如果在此处落子,敌方可以构成五子连珠,那么对于地方而言这是非常高价值的格子,那么在己方回合,当务之急是在此处落子,阻止对方胜利,除非在其它位置落子己方可以胜出。
对此,我们可以对棋盘上每一个可行位置进行打分,评估其对于己方、敌方的价值。
如何定义该位置对己方的价值?
一枚棋子可以在四个方向上与其它棋子连成五子,即:水平、竖直、对角线、主对角线
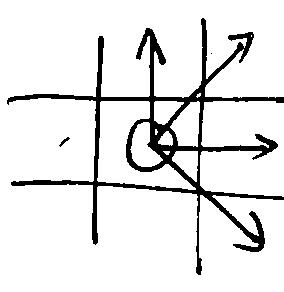
可以采用如下方法判断在某一具体方向上的价值
- 在四个方向中选择某一方向
- 向正方向、负方向分别查找4格,如遇到空格或敌方棋子则提前停止
- 统计己方棋子个数,以及两端的被遮拦情况。
例如对于下图,在该处落子后,形成水平方向上的两子连珠,且一端有遮拦一端无遮拦
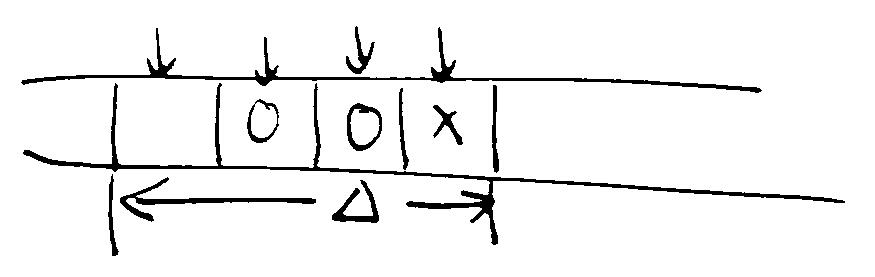
一共可能形成如下几种情形,我们可以依据经验公式评估其价值。
| 子数 | 1子 | 2子 | 3子 | 4子 | 5子 |
|---|---|---|---|---|---|
| 无遮拦 | ③ | ③ | ② | ① | MAX |
| 一端遮拦 | - | - | ③ | ② | ① |
| 两端遮拦 | - | - | - | - | ① |
'-' 表明该位置在该方向上具有的价值较低,不予考虑。然而,如果其他方向上的情况更有利,那么该位置的价值仍然可能非常高。。
接下来,我们可以讨论棋子在多个方向上的价值,一般来说,仅需要考虑最高价值的两个方向。
这是因为两个活三(无遮拦的三子连珠)足以致胜,三个活三并没有明显优势。
| 价值 | 最优方向 | 次优方向 |
|---|---|---|
| Lv1 | MAX | ? |
| Lv1 | ① | ? |
| Lv2 | ② | ② |
| Lv3 | ② | ③ |
| Lv3 | ② | - |
| Lv4 | ③ | ③ |
| Lv4 | ③ | - |
| Lv4 | - | - |
“?” 指代任意情况,例如(MAX-?)对应了(MAX-MAX)、(MAX-①)、(MAX-②)、(MAX-③)、(MAX-'-')
该定义方式将行为的优先级分为了四个等级
- Lv1:下子直接取胜,或在一回合内取胜。
- Lv2:下在大概率在若干回合内取胜。
- Lv3:能够迫使对方一直防御。
- Lv4:收益较低。
如何综合攻防?
若要综合攻防,必须将具体位置对敌方的价值考虑进去。倘若某一位置对敌方来说是高价值的,那我们在此处落子可以破坏敌方阵型,削弱敌方价值,同样我们可以给出如下价值表
| 综合价值排序 | 己方价值 | 敌方价值 | 对应的奖励数值 |
|---|---|---|---|
| 1 | Lv1 | ? | \(2^{20}\) |
| 2 | ? | Lv1 | \(2^{16}\) |
| 3 | Lv2 | ? | \(2^{12}\) |
| 4 | ? | Lv2 | \(2^{8}\) |
| 5 | Lv3 | ? | \(2^{4}\) |
| 6 | Lv4 | ? | \(2^{0}\) |
“?” 指代任意情况,例如(Lv1-?)对应了(Lv1-Lv1)、(Lv1-Lv2)、(Lv1-Lv3)、(Lv1-Lv4)
在进行判断时,应当从上往下逐一判断。
这里给出的奖励数值仅供参考。
总结
在本小节中,我们精心构建了一种全新的综合评估方法,旨在全面衡量棋盘上的每个格子对于己方和敌方的战略价值。通过设计一系列精细的量化指标,我们赋予了AI/计算机深入解读棋盘格局的能力,使其能够准确判断每个格子的具体价值。这一方法为AI/计算机制定决策提供了坚实的数据支撑。
行为集规定与决策制定
为了使AI做出高效的决策,我们首先需要定义一套合适且简洁的行为集合。这意味着AI在做出选择时,不必每次都逐一考虑棋盘上的所有位置。在此基础上,我们需要开发一种策略,帮助AI从众多可能的决策中筛选出最为恰当的一个。通过这种方式,AI能够在复杂的环境中迅速而准确地做出最佳决策。
ROI 感兴趣区域
倘若上一轮你在棋盘中心落子,那么下一轮你不应当在棋盘的最角落落子。
一般来说,在落子时,只有与已有棋子(无论是己方还是敌方)邻接的位子才具有价值,首先我们定义邻接。
考虑棋盘上只有一子的情形,规划出与其具有高价值“联动”的区域如下:
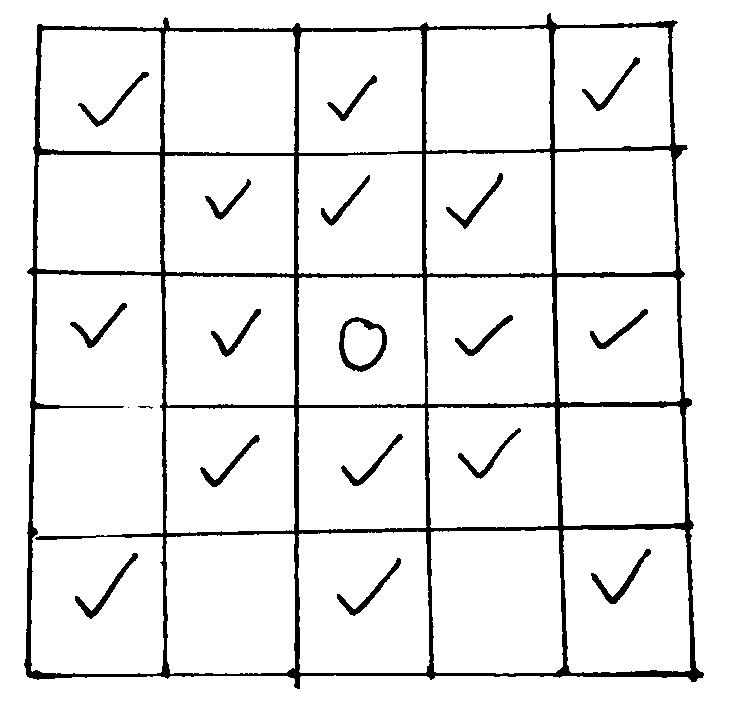
可以给出更具体的定义:
倘若一个格子位于另一格子的水平、竖直、主对角线或副对角线方向上,并且两格子距离小于等于2,那么称这两个格子为邻接关系。进一步的,称距离为1为强邻接,距离为2为弱邻接。
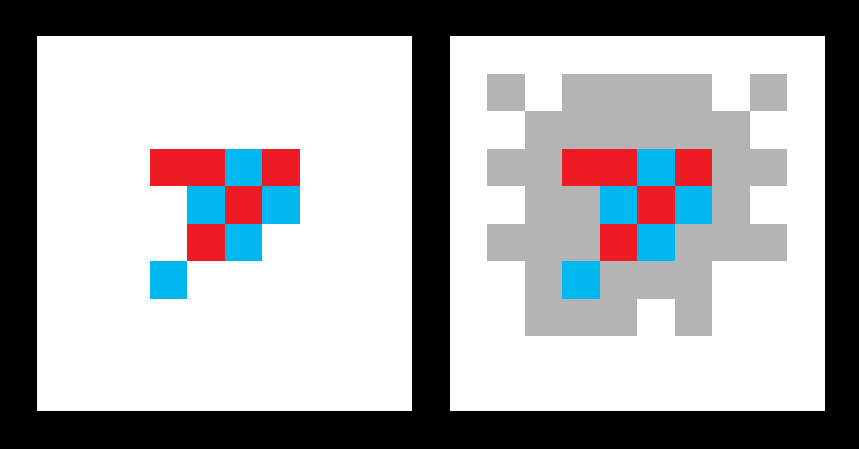
进一步的,我们定义感兴趣区域如下:
满足以下要求之一的空格子为感兴趣区域:
- 该格子是棋盘正中心。
- 该格子与至少一个己方棋子所处格子存在邻接关系。
- 该格子与至少一个敌方棋子所处格子存在强邻接关系。
下图给出了己方落子ROI区域的示例,其中红色为己方棋子,蓝色为对方棋子,灰色表示感兴趣区域。
决策进行
在进行决策前,我们可以评估感兴趣区域中所有格子的价值,假定ROI中格子的个数是\(N\),格子的价值分别是\(x_0, x_1, ..., x_{N-1}\),我们可以采用下述两种方法选择决策
硬最大值 hardmax
选择奖励最大的决策,即
软最大值 hardmax
不同于硬最大值,软最大值以一定几率接受非最优解,其包含一个常量\(K\),常量K越大表示对低价值决策的接受程度越大,当常量\(K\to 0\)时,软最大值退化为硬最大值;当常量\(K\to +\infty\)时,软最大值退化为随机抽取。
结语
下一篇中我们将继续讨论如何训练AI。
在最后,给出一个流程图供大家参考,在后文中我将详细讨论。
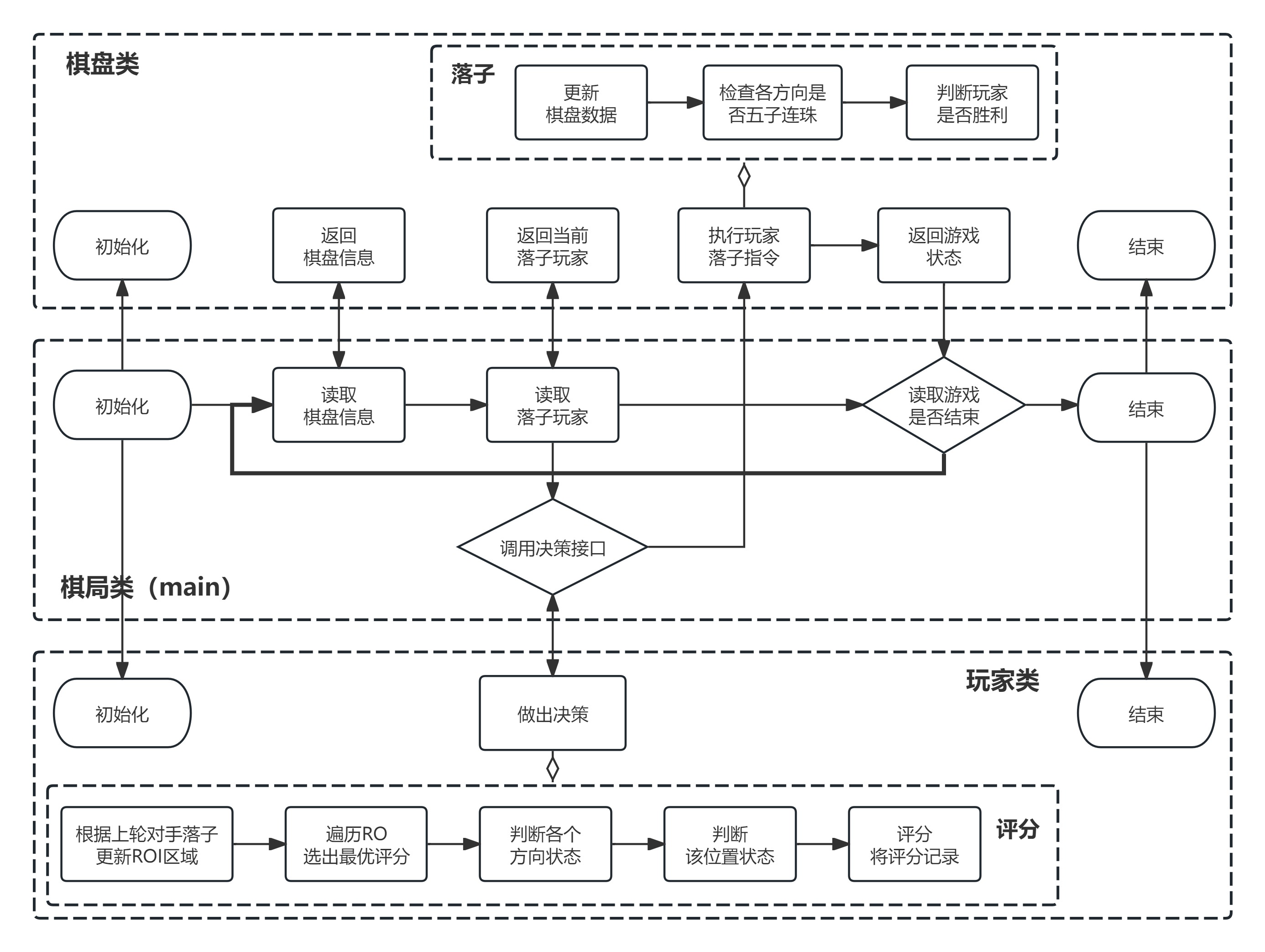 原创作者: SXWisON 转载于: https://www.cnblogs.com/SXWisON/p/18400902
原创作者: SXWisON 转载于: https://www.cnblogs.com/SXWisON/p/18400902















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









