







之前写过一篇关于Trie树的介绍:Trie树——在一个字符串集合中快速查找某个字符串。今天就用Trie树来实现敏感词过滤算法。
首先简单介绍一下Trie树的数据结构:
1.根节点不存储字符。
2.Trie树中除了根节点外其余节点都需要存储一个字符,另外还需要一个标记来确定当前节点是否为敏感词中的最后一个字符。
3.每个节点的所有子节点包含的字符都不相同。
了解了Trie树的基本结构,就可以开始思考如何构造我们的敏感词树。我又把这张图搬出来了:
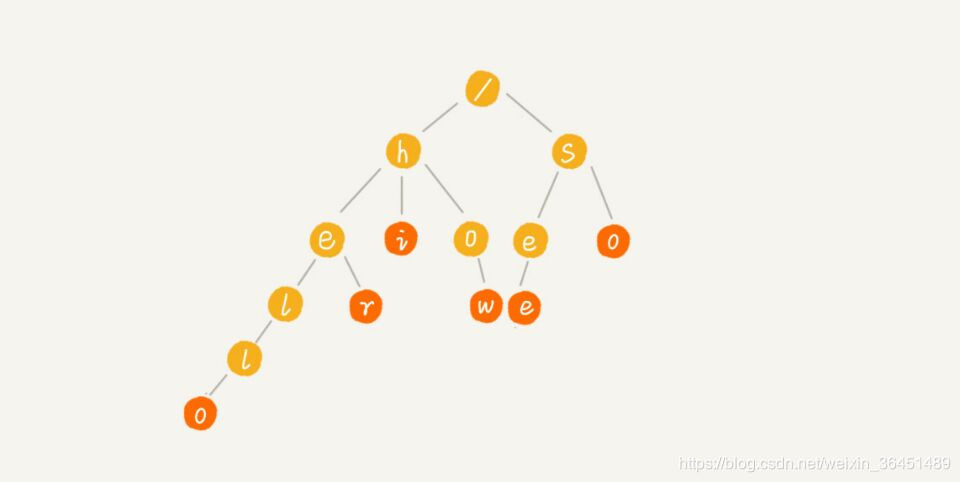
假设我们的敏感词是[hello,her,how,see,so],那么我们的敏感词树就长成上图那样。Trie树的节点数据结构设计:
class TrieNode{
//key为子节点字符,value为字节点的子节点
Map<Character,TrieNode> subnodes = new HashMap<Character, TrieNode>();
//isend标记该节点中的字符是否为为敏感词中的最后一个字符
boolean isend = false;
//添加子节点
void addSubNode(Character key,TrieNode subnode){
subnodes.put(key,subnode);
}
//获取下一个节点
TrieNode getSubNode(Character key){
return subnodes.get(key);
}
//判断是否为最后一个节点
boolean isEnd(){
return isend;
}
//设置标记
void setEnd(boolean end){
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 982
982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









