







点击上方“代码集中营”,设为星标
优秀文章,第一时间送达!
前言:有时候可能需要从网上或者某个网站收集一些数据,这时候就可以用爬虫来实现,不需要手动去收集费时费力。本文使用java的jsoup来实现。
前置条件
JAVA基础:https://www.runoob.com/java/java-tutorial.html
有安装可运行java的编译器(idea等)
有安装mysql(可百度如何安装mysql)
有安装数据库管理工具(Navicat Premium 12等)
用到的jar包
jsoup-1.11.3.jar
mysql-connector-java-8.0.16.jar
jar下载(搜索下载):https://mvnrepository.com/
准备工作
寻找目标网站
因为要简单粗暴,所以找了一个爬取逻辑不复杂的网站
本文所爬目标网站:https://chengyu.911cha.com/pinyin_a_p1.html
在数据库中新建一个表
表名任意、字段任意(例:id、首字母、成语、个数)
具体百度“如何用Navicat新建表和添加字段”
分析目标网站
第一步
在浏览器中按F12观察该网站HTML代码
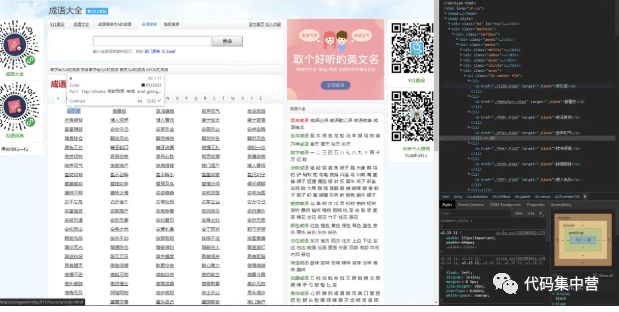
谷歌浏览器为例,可以按ctrl+shift+c。鼠标移动到网页任意地方,右边的代码框会显示当前鼠标停留处的代码。
网站看起来结构并不复杂,甚至还有点整齐。英文字母A-Z一字排开整齐放好了,意味着写爬虫代码时可以不用自己手动输入英文字母A-Z,后面会提到如何自动获取英文字母。
第二步
这是网页分页部分的html代码,会发现多页时代码中会有5个a标签。那么要计算一共有多少也可以用a标签的个数减去2就是真实页数了。
<div class="gclear pp bt center f14">
<span class="gray">首页span>
<a href="pinyin_a_p3.html">末页a>
<span class="gray">|span>
<a href="pinyin_a.html" class="red noline">1a>
<a href="pinyin_a_p2.html">2a>
<a href="pinyin_a_p3.html">3a>
<span class="gray">|span>
<span class="gray">上一页span>
<a href="pinyin_a_p2.html">下一页a>
div>这个网页还存在另一种情况,比如字母o的成语中a标签只有一个那这种就不用减2了。
class="gclear pp bt center f14">class="gray">首页class="gray">末页class="gray">|"pinyin_o.html" class="red noline">1class="gray">|class="gray">上一页class="gray">下一页
开始写代码
项目结构
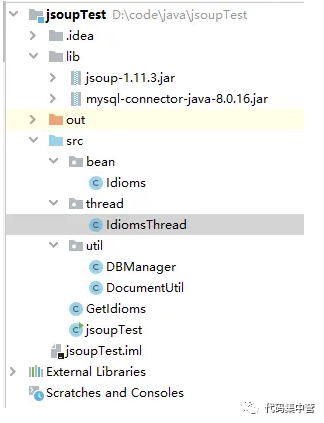
具体代码
Idioms.class
public class Idioms {
private String letter;
private String content;
private int num;
public String getLetter() {
return letter;
}
public void setLetter(String letter) {
this.letter = letter;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}IdiomsThread.class
public class IdiomsThread implements Runnable {
CallBack callBack;
long startTime = System.currentTimeMillis();
long endTime;
String letter;
int letterCount = 0;
private synchronized void insertData(List idiomsList) {
String sql = "insert into 表名 values";
for (int i = 0; i if (i == 0) {
sql = sql + "(id,\'" + idiomsList.get(i).getLetter()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









