







1.Pytorch 模型保存与加载,并在加载的模型基础上继续训练
只保存参数;(官方推荐)
torch.save(model.state_dict(), path) #只保存参数
#特别地,如果还想保存某一次训练采用的优化器、epochs等信息,可将这些信息组合
#起来构成一个字典,然后将字典保存起来
state = {'model': model.state_dict(), 'optimizer': optimizer.state_dict(), 'epoch': epoch}
torch.save(state, path)
#加载
model.load_state_dict(torch.load(path))
#针对上述第二种以字典形式保存的方法,加载方式如下
checkpoint = torch.load(path)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
epoch = checkpoint(['epoch'])ps:只保存参数的方法在加载的时候要事先定义好跟原模型一致的模型,并在该模型的实例对象(假设名为model)上进行加载,即在使用上述加载语句前已经有定义了一个和原模型一样的Net, 并且进行了实例化 model=Net( )
下面给出一个具体的例子程序,该程序只保存最新的参数
#-*- coding:utf-8 -*-
import torch as torch
import torchvision as tv
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as transforms
from torchvision.transforms import ToPILImage
import torch.backends.cudnn as cudnn
import datetime
import argparse
# 参数声明
batch_size = 32
epochs = 10
WORKERS = 0 # dataloder线程数
test_flag = True #测试标志,True时加载保存好的模型进行测试
ROOT = '/home/pxt/pytorch/cifar'
log_dir = '/home/pxt/pytorch/logs/cifar_model.pth' # 模型保存路径
# 加载MNIST数据集
transform = tv.transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
train_data = tv.datasets.CIFAR10(root=ROOT, train=True, download=True, transform=transform)
test_data = tv.datasets.CIFAR10(root=ROOT, train=False, download=False, transform=transform)
train_load = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=WORKERS)
test_load = torch.utils.data.DataLoader(test_data, batch_size=batch_size, shuffle=False, num_workers=WORKERS)
# 构造模型
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 64, 3, padding=1)
self.conv2 = nn.Conv2d(64, 128, 3, padding=1)
self.conv3 = nn.Conv2d(128, 256, 3, padding=1)
self.conv4 = nn.Conv2d(256, 256, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(256 * 8 * 8, 1024)
self.fc2 = nn.Linear(1024, 256)
self.fc3 = nn.Linear(256, 10)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = self.pool(F.relu(self.conv4(x)))
x = x.view(-1, x.size()[1] * x.size()[2] * x.size()[3])
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
device = torch.device("cuda" if use_cuda else "cpu")
#model = Net().cuda()
model = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 模型训练
def train(model, train_loader, epoch):
model.train()
train_loss = 0
for i, data in enumerate(train_loader, 0):
x, y = data
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
y_hat = model(x)
loss = criterion(y_hat, y)
loss.backward()
optimizer.step()
train_loss += loss
loss_mean = train_loss / (i+1)
print('Train Epoch: {}t Loss: {:.6f}'.format(epoch, loss_mean.item()))
# 模型测试
def test(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for i, data in enumerate(test_loader, 0):
x, y = data
x = x.cuda()
y = y.cuda()
optimizer.zero_grad()
y_hat = model(x)
test_loss += criterion(y_hat, y).item()
pred = y_hat.max(1, keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
test_loss /= (i+1)
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)n'.format(
test_loss, correct, len(test_data), 100. * correct / len(test_data)))
def main():
# 如果test_flag=True,则加载已保存的模型
if test_flag:
# 加载保存的模型直接进行测试机验证,不进行此模块以后的步骤
checkpoint = torch.load(log_dir)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
epochs = checkpoint['epoch']
test(model, test_load)
return
for epoch in range(0, epochs):
train(model, train_load, epoch)
test(model, test_load)
# 保存模型
state = {'model':model.state_dict(), 'optimizer':optimizer.state_dict(), 'epoch':epoch}
torch.save(state, log_dir)
if __name__ == '__main__':
main()在加载的模型基础上继续训练
在训练模型的时候可能会因为一些问题导致程序中断,或者常常需要观察训练情况的变化来更改学习率等参数,这时候就需要加载中断前保存的模型,并在此基础上继续训练,这时候只需要对上例中的 main() 函数做相应的修改即可,修改后的 main() 函数如下:
def main():
# 如果test_flag=True,则加载已保存的模型
if test_flag:
# 加载保存的模型直接进行测试机验证,不进行此模块以后的步骤
checkpoint = torch.load(log_dir)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
start_epoch = checkpoint['epoch']
test(model, test_load)
return
# 如果有保存的模型,则加载模型,并在其基础上继续训练
if os.path.exists(log_dir):
checkpoint = torch.load(log_dir)
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
start_epoch = checkpoint['epoch']
print('加载 epoch {} 成功!'.format(start_epoch))
else:
start_epoch = 0
print('无保存模型,将从头开始训练!')
for epoch in range(start_epoch+1, epochs):
train(model, train_load, epoch)
test(model, test_load)
# 保存模型
state = {'model':model.state_dict(), 'optimizer':optimizer.state_dict(), 'epoch':epoch}
torch.save(state, log_dir)2. tqdm 进度条 pip install tpdm
import time
from tqdm import *
for i in tqdm(range(1000)): # 传入可迭代对象
time.sleep(.01)
pbar = tqdm(["a", "b", "c", "d"])
for char in pbar: # 可以为进度条设置描述
# 设置描述
pbar.set_description("Processing %s" % char)
time.sleep(1)3. lmdb pip install lmdb
赵剑行:lmdb 数据库zhuanlan.zhihu.com#LMDB的全称是Lightning Memory-Mapped Database(快如闪电的内存映射数据库)
import lmdb
import os, sys
def initialize():
env = lmdb.open("lmdb_dir")
return env
def insert(env, sid, name):
txn = env.begin(write=True)
txn.put(str(sid).encode(), name.encode())
txn.commit()
def delete(env, sid):
txn = env.begin(write=True)
txn.delete(str(sid).encode())
txn.commit()
def update(env, sid, name):
txn = env.begin(write=True)
txn.put(str(sid).encode(), name.encode())
txn.commit()
def search(env, sid):
txn = env.begin()
name = txn.get(str(sid).encode()).decode()
return name
def display(env):
txn = env.begin()
cur = txn.cursor()
for key, value in cur:
print(key.decode(), value.decode())
env = initialize()
print("Insert 3 records.")
insert(env, 1, "Alice")
insert(env, 2, "Bob")
insert(env, 3, "Peter")
display(env)
print("Delete the record where sid = 1.")
delete(env, 1)
display(env)
print("Update the record where sid = 3.")
update(env, 3, "Mark")
display(env)
print("Get the name of student whose sid = 3.")
name = search(env, 3)
print(name)
#------------------------------------
"""
Insert 3 records.
1 Alice
2 Bob
3 Peter
Delete the record where sid = 1.
2 Bob
3 Peter
Update the record where sid = 3.
2 Bob
3 Mark
Get the name of student whose sid = 3.
Mark
"""3. PyYaml pip install pyyaml
Pytorch日积月累www.zhihu.com
# -*- coding:utf-8 -*-
import yaml
#https://www.zhihu.com/column/c_1244271799468482560
f = open(r'dataconfig.yml')
dic = yaml.load(f, Loader=yaml.FullLoader)
print (type(dic), dic) # type(dic) <class 'dict'>
dic2 = {'name': 'Tom Smith', 'age': 37, 'spouse': {'name': 'Jane Smith', 'age': 25},
'children': [{'name': 'Jimmy Smith', 'age': 15},
{'name1': 'Jenny Smith', 'age1': 12}]}
f_s = open(r'dataconfig2.yml','w')
yaml.dump(dic2, f_s)4. Pytorch中的Conv1d()和Conv2d()函数
Pytorch中的Conv1d()和Conv2d()函数_潘多拉星系的专栏-CSDN博客blog.csdn.net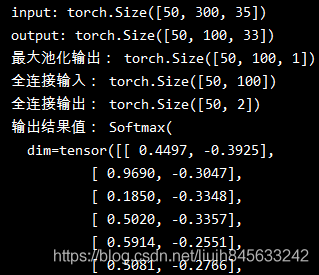


一般来说,一维卷积nn.Conv1d()用于文本数据,只对宽度进行卷积,对高度不卷积。通常,输入大小为word_embedding_dim * max_sent_length,其中,word_embedding_dim为词向量的维度,max_sent_length为句子的最大长度。卷积核窗口在句子长度的方向上滑动,进行卷积操作。
输入:批大小为50,句子的最大长度为35,词向量维度为300
目标:句子分类,共2类
import torch
import torch.nn as nn
# max_sent_len=35, batch_size=50, embedding_size=300
conv1 = nn.Conv1d(in_channels=300, out_channels=100, kernel_size=3)
input = torch.randn(50, 35, 300)
# batch_size x max_sent_len x embedding_size -> batch_size x embedding_size x max_sent_len
input = input.permute(0, 2, 1)
print("input:", input.size())
output = conv1(input)
print("output:", output.size())
# 最大池化
pool1d = nn.MaxPool1d(kernel_size=35-3+1)
pool1d_value = pool1d(output)
print("最大池化输出:", pool1d_value.size())
# 全连接
fc = nn.Linear(in_features=100, out_features=2)
fc_inp = pool1d_value.view(-1, pool1d_value.size(1))
print("全连接输入:", fc_inp.size())
fc_outp = fc(fc_inp)
print("全连接输出:", fc_outp.size())
# softmax
m = nn.Softmax()
out = m(fc_outp)
print("输出结果值:", out)- 原始输入大小为(50, 35, 300),经过permute(0, 2, 1)操作后,输入的大小变为(50, 300, 35);
- 使用1个window_size为3的卷积核进行卷积,因为一维卷积是在最后维度上扫的,最后output的大小即为:50*100*(35-3+1)=50*100*33
- output经过最大池化操作后,得到了数据维度为:(50,100,1)
- 经过(输入特征=100,输出特征=2)的全连接层,数据维度就变为了:(50,2)
- 再经过softmax函数就得到了属于两个类别的概率值
eg: 假设 embedding_size=256, feature_size=100, window_sizes=[3,4,5,6], max_text_len=35
class TextCNN(nn.Module):
def __init__(self, config):
super(TextCNN, self).__init__()
self.is_training = True
self.dropout_rate = config.dropout_rate
self.num_class = config.num_class
self.use_element = config.use_element
self.config = config
self.embedding = nn.Embedding(num_embeddings=config.vocab_size,
embedding_dim=config.embedding_size)
self.convs = nn.ModuleList([
nn.Sequential(nn.Conv1d(in_channels=config.embedding_size,
out_channels=config.feature_size,
kernel_size=h),
# nn.BatchNorm1d(num_features=config.feature_size),
nn.ReLU(),
nn.MaxPool1d(kernel_size=config.max_text_len-h+1))
for h in config.window_sizes ])
self.fc = nn.Linear(in_features=config.feature_size*len(config.window_sizes),
out_features=config.num_class)
if os.path.exists(config.embedding_path) and config.is_training and config.is_pretrain:
print("Loading pretrain embedding...")
self.embedding.weight.data.copy_(torch.from_numpy(np.load(config.embedding_path)))
def forward(self, x):
embed_x = self.embedding(x)
#print('embed size 1',embed_x.size()) # 32*35*256
# batch_size x text_len x embedding_size -> batch_size x embedding_size x text_len
embed_x = embed_x.permute(0, 2, 1)
#print('embed size 2',embed_x.size()) # 32*256*35
out = [conv(embed_x) for conv in self.convs] #out[i]:batch_size x feature_size*1
#for o in out:
# print('o',o.size()) # 32*100*1
out = torch.cat(out, dim=1) # 对应第二个维度(行)拼接起来,比如说5*2*1,5*3*1的拼接变成5*5*1
#print(out.size(1)) # 32*400*1
out = out.view(-1, out.size(1))
#print(out.size()) # 32*400
if not self.use_element:
out = F.dropout(input=out, p=self.dropout_rate)
out = self.fc(out)
return out基于上述代码,具体计算过程如下:
- 原始输入大小为
(32, 35, 256),经过permute(0, 2, 1)操作后,输入的大小变为(32, 256, 35); - 使用1个卷积核进行卷积,可得到1个大小为
32 x 100 x 1的输出,共4个卷积核,故共有4个大小为32 x 100 x 1的输出; - 将上一步得到的4个结果在
dim = 1上进行拼接,输出大小为32 x 400 x 1; view操作后,输出大小变为32 x 400;- 全连接,最终输出大小为
32 x 2,即分别预测为2类的概率大小。
鸢尾花分类 conv1 简单demo
import numpy as np
import torch
import torch.nn as nn
from sklearn.datasets import load_iris
import torch.nn.functional as F
data = load_iris()
X = data.data # 只包括样本的特征,150x4
y = data.target # 样本的类型,[0, 1, 2]
# print(X.shape) # (150, 4)
# print(X[0]) #[5.1 3.5 1.4 0.2]
input = X.reshape(150, 4, 1) # batch_size embedding_size max_sent_len
input = torch.tensor(input, dtype=torch.float32)
target = torch.LongTensor(y)
# conv1
class conv1_model(nn.Module):
"""conv1 文本分类建模 """
def __init__(self):
super(conv1_model, self).__init__()
self.conv1 = nn.Conv1d(in_channels=4, out_channels=10, kernel_size=1)
self.fc = nn.Linear(in_features=10, out_features=3)
def forward(self, x):
x = self.conv1(x)
x = x.view(-1, x.size(1))
out = self.fc(x)
return out
model = conv1_model()
cost = nn.CrossEntropyLoss() #损失函数
# 优化器Adam优化算法,相比SGD可以自动调节学习率
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
for epoch in range(300):
#x, y = [input, target] # 读入一批的数据
for i in range(1, 16):
x, y = input[(i-1)*10:i*10], target[(i-1)*10:i*10]
optimizer.zero_grad()
# 模型预测
predict = model(x)
#print(predict.size(), target.size())
loss = cost(predict, y)
#print("loss ----> ", loss.item())
loss.backward()
optimizer.step()
if epoch % 50 ==0:
# [4.8 3.1 1.6 0.2] [5. 2. 3.5 1. ] [6.9 3.2 5.7 2.3] --> [0, 1, 2]
pre_x = np.array([[4.8, 3.1, 1.6, 0.2], [5., 2., 3.5, 1. ], [6.9, 3.2, 5.7, 2.3]]).reshape(3, 4, 1)
input_x = torch.tensor(pre_x, dtype=torch.float32)
res = model(input_x)
c = F.softmax(res, dim=1).argmax(dim=1)
print("epoch, res ---> ",epoch, c)














 2107
2107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









