







在日常做数据处理中,我们可能或涉及到取不同分组中的前几名。比如,某零售企业经营的业务中,包含“蔬菜”、“水果”、“水产”这3个板块的商品,此时,我们需要计算出每个不同的层级索引中销量(销售数量)前几的记录。
注:本文中所引用的数据纯属虚构(虚拟数据),可自行下载练习使用,不作商业用途。否则后果自负。谢谢!
链接:https://pan.baidu.com/s/1QbiUOQNYO3pyhVgCnkriNA
提取码:u00d
复制这段内容后打开百度网盘手机App,操作更方便哦
1. 构造数据源,小试一下牛刀
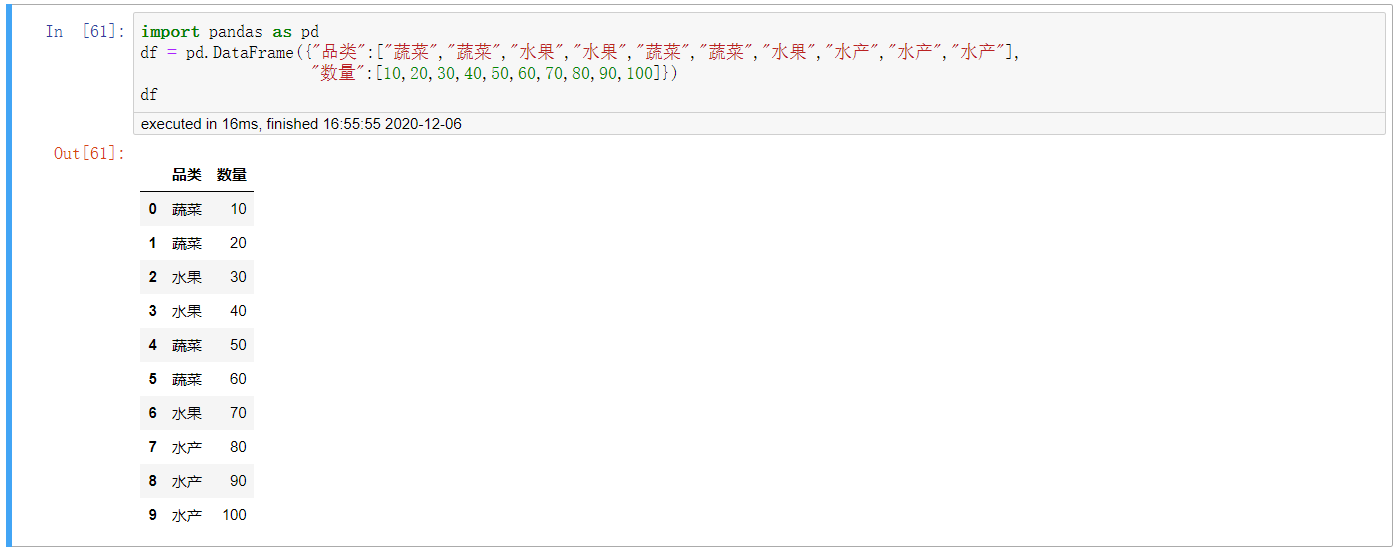
import pandas as pd
df = pd.DataFrame({"品类":["蔬菜","蔬菜","水果","水果","蔬菜","蔬菜","水果","水产","水产","水产"],
"数量":[10,20,30,40,50,60,70,80,90,100]})
df
2. 实操,确认方法是否可行
df.sort_values(["品类", "数量"],ascending=[1,0],inplace=True)
df_group
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1365
1365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









