






字符集基础
字符集:数据库中的字符集包含两层含义
各种文字和符号的集合,包括各国家文字,标点符号,图形符号,数字等。
字符的编码方式,即二进制数据与字符的映射规则;
字符集分类:
ASCII:美国信息互换标准编码;英语和其他西欧语言;单字节编码,7位(bits)表示一个字符,共128字符。
GBK:汉字内码扩展规范;中日韩汉字、英文、数字;双字节编码;共收录了21003个汉字,GB2312的扩展。
utf-8:Unicode标准的可变长度字符编码;Unicode标准(统一码),业界统一标准,包含世界上数十种文字的系统;utf-8使用一至4个字节为每一个字符编码。
其他常见字符集:utf-32,utf-16,big5(繁体字),latin1()
mysql字符集:
查看字符集:

mysql> show character set;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| binary | Binary pseudo charset | binary | 1 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
| gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.00 sec)
新增字符集:
在编译mysql时用--with-charset=gbk 来新增字符集

字符集与字符序(字符排序的规则)
charset 和 collation
字符集与字符序是一对多的关系,但一个字符集至少有一个字符序
collation:字符序,字符的排序与比较规则,每个字符集都有对应的多套字符序。
不同的字符序决定了字符串在比较排序中的精度和性能不同。
查看字符序
mysql> SHOW COLLATION ;
mysql的字符序遵从命名惯例:
以_ci(表示大小写不敏感)
以_cs(表示大小写敏感)
以_bin(表示用编码值进行比较)
字符集设置级别
charset 和 collation的设置级别:
服务器级>>数据库级>>表级>>列级
服务器级
系统变量(可动态设置):
--character_set_server:默认的内部操作字符集
--character_set_system:系统元数据(字段,表名等)字符集
设置:
使用命令直接设置
配置文件中设置:mysqld,
数据库级(数据库中存储数据的默认字符集)
create database db_name character set latin1 collate latin1_swedish_ci;
-character_set_database:当前选中数据库的默认字符集
主要影响load data 等语句的默认字符集;create database的字符集如果不设置,默认使用character_set_server的字符集。
表级
mysql>create table tbl(...) default charset=utf-8 default collate=utf8_bin
数据存储字符集使用规则:
使用列集的character set 设定值
若列级字符集不存在,则使用对应表级的default character set 设定值;
若表级字符集不存在,则使用数据库级的default character set 设定值
若数据库字符集不存在,则使用服务器级character_set_server设定值
实践
查看字符集
show [global] variables like 'character%'
show [global] variables like 'collation%'
mysql> SHOW VARIABLES LIKE '%CHARACTER%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
mysql> SHOW VARIABLES LIKE '%collation%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | utf8_general_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
修改字符集
修改服务器级字符集
set global character_set_server=utf8; (全局)
修改表级字符集
alter table tbl convert to character set XXX;(表)
mysql> alter table stu convert to character set utf8;
客户端连接与字符集
连接与字符集
-character_set_client:客户端来源数据使用的字符集(客户端程序发过来的SQL用什么来编码的)
-character_set_conection:连接层字符集(做中间层转换)
-character_set_results:查询结果字符集(返回给客户端程序用的字符集)
一般可以统一设置(推荐):
msyql>set names utf8;
也可以统一叫做连接字符集;
在配置文件中:
default-character-set = utf8
客户端连接字符集
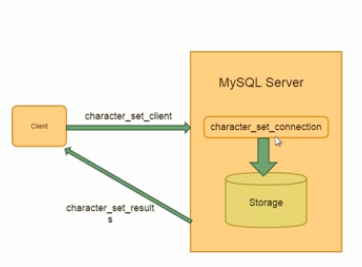
常见乱码原因:
数据存储字符集不能正确编码(不支持)client发来的数据:client(utf8)->storage(latin1)
程序连接使用的字符集与通知mysql的character_set_client,character_set_conection,character_set_results 等不一致或不兼容。(告诉mysql:set names gbk ;程序连接使用的字符集一致)
1.甚至表本身utf8,而设置 set names gbk, 程序连接也使用 gbk;
此时向表中插入汉字,依然可以显示而并不乱码,因为虽然程序连接使用gbk编码,mysql内部会将gbk转换成utf8来显示;
2.表utf8,set names utf8,但是 程序连接使用 gbk,此时向表中插入汉字,是乱码的。
load data 出现乱码:
aiapple@ubuntu:~$ file test.t
test.t: UTF-8 Unicode text
aiapple@ubuntu:~$ cat test.t
你好
mysql> show variables like '%char%';
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | gbk |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
mysql>load data infile '/home/aiapple/test.t' into table t;
此时会出现乱码,即告知数据库的character_set_database 的字符集与程序使用的文件test.t 不一样;
更改set character_set_database = utf8 则能正常显示;
这里与 普通告知mysql字符集 set names xxx 区别开来,毕竟是导入表到一个数据库当中,应该使数据库的字符集与文件的字符集相同
客户端连接与字符集
使用建议:
创建数据库/表时显示的指定字符集,不使用默认
连接字符集与数据存储字符集设置一致,推荐使用utf8
驱动程序连接时显示指定字符集(set names xxx)
客户端的设置:

三要素:
1.程序驱动或客户端的字符集(在客户端设置)
2.告知mysql的字符集(set names xxx)
3.数据存储的字符集(表结构的字符集alter table tbl convert to character set xxx)
前两个必须一致才不会出现乱码,推荐三个都设置成一致
需求:在系统运行了一段时间,有了一定的数据,后发现字符集不能满足要求需要重新修改,又不想丢弃这段时间的数据。
alter database character set xxx 或者alter table tablename character set xxx;这两条命令只对想创建的表或者记录生效
方法:先将数据导出,经过适当的调整重新导入才可完成。
以下模拟的是将latin1字符集的数据库修改成GBK字符集的数据库的过程
1)导出表结构
mysqldump -uroot -p --default-character-set=gbk -d WY_yun >createtab.sq
--default-character-set表示设置以什么字符集连接;-d表示只导出表结构,不导出数据
2)手动修改creatatab.sql中表结构定义中的字符集为新的字符集
3)确保记录不在更新,导出所有记录
mysqldump -uroot -p --quick --no-create-info --extended-insert --default-character-set=latin1 WY_yun > data.sql
-quick:该选项用于转存储大的表。它强制mysqldump 从服务器一次一行地检索表中的行,而不是检索所有的行,并在输出前将它缓存到内存中。
--no-create-info:不写重新创建么个转存储表的create table 语句
--extended-insert:使用包括几个VALUES列表的多行insert语法。这样使转存储文件更小,重载文件时可以加速插入
--default-character-set=latin1:按照原有的字符集导出所有数据,这样导出的文件中,所有中文都是可见的,不会保存成乱码
4)修改数据的字符集为新字符集---打开data.sql,将set names latin1 修改成 set names gbk
5)使用新得字符集创建新的数据库
mysql> create database na default charset gbk;
6)将新字符集的表结构导入新库;创建表,执行createtab.sql
mysql -uroot -p na
7) 将新字符集的数据文件导入新库;导入数据,执行data.sql
mysql -uroot -p na < data.sql
似乎实验没有成功可以去提问?
总结
字符集与字符序是1:N
字符序是字符的排序与比较规则及字符的精度和性能;
表级别字符集修改:alter table stu convert to character set utf8;
三个连接相关字符集统一设置:set names utf8;
常见乱码原因
load数据时,因让数据库级别的字符集与文件相同;
三要素:
程序驱动或客户端的字符集(在客户端设置)
告知mysql的字符集(set names xxx)
数据存储的字符集(表结构的字符集alter table tbl convert to character set xxx)
运行一段时间后发现数据乱码,如何保存数据;















 4646
4646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









