







之前看了ConcurrentSkipListMap的源码,未做总结,今天做个总结,关于ConcurrentSkipListMap其实网上有很多文章,博主今天就不通篇大论,挑些精简的来说。
首先跳表中维护一层时,即值存在level1时的底层数据结构为:

当添加第二个元素时,通过抛硬币算法算出!=0时,这里我们只考虑加了一层level,底层数据结构的演化为:



其实这张图就如网上很多的跳表结构图一样,画的没问题,但是其实不能完全提现ConcurrentSkipListMap底层完全的数据结构,在这些图中其实还维护了一种node的关系,不受level或者index的影响,如图所示: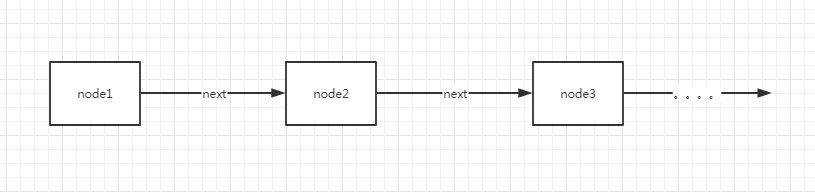
从大的方面讲,跳表是通过HeadIndex跟Index这种层级及索引关系查找数据,其实最底层还是通过层级及索引关系查找到对应的node,博主在看源码时就产生了一个疑惑,为什么源码中维护的HeadIndex的数据结构所维护的node关系在跳表的数据结构图中提现不出来,看了很久才终于明白。所以想完全了解跳表的结构,并根据源码分析,还是要结合着两张图:

最后补充一点,官网原话为:
Indexing uses skip list parameters that maintain good search
performance while using sparser-than-usual indices: The
hardwired parameters k=1, p=0.5 (see method doPut) mean
that about one-quarter of the nodes have indices. Of those that
do, half have one level, a quarter have two, and so on (see
Pugh's Skip List Cookbook, sec 3.4). The expected total space
requirement for a map is slightly less than for the current
implementation of java.util.TreeMap.大概意思是:索引使用跳跃表参数来保持良好的搜索性能,同时使用比通常少的索引:硬连接参数k=1, p=0.5(参见方法doPut)意味着大约四分之一的节点有索引。其中,有一半的人只有一个level,四分之一的人有两个level,以此类推。从这句话可以知道,并不是所有node节点都有Index与之对应:

总结来说,就是两个相邻Index的node并不一定是直接相关联的(nodePre.next != nodeAfter),中间可能存在多个node节点,只是这些node节点并未生成对应的Index。















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









