






一、一致性非锁定读
一致性的非锁定读是指InnoDB存储引擎通过行多版本控制(multi versioning)的方式来读取当前执行时间数据库中行的数据。如果读取的行正在执行DELETE或UPDATE操作。这时读取操作不会因此去等待行上的锁释放。相反地,InnoDB存储引擎会去读取行的一个快照数据。
如下图所示:
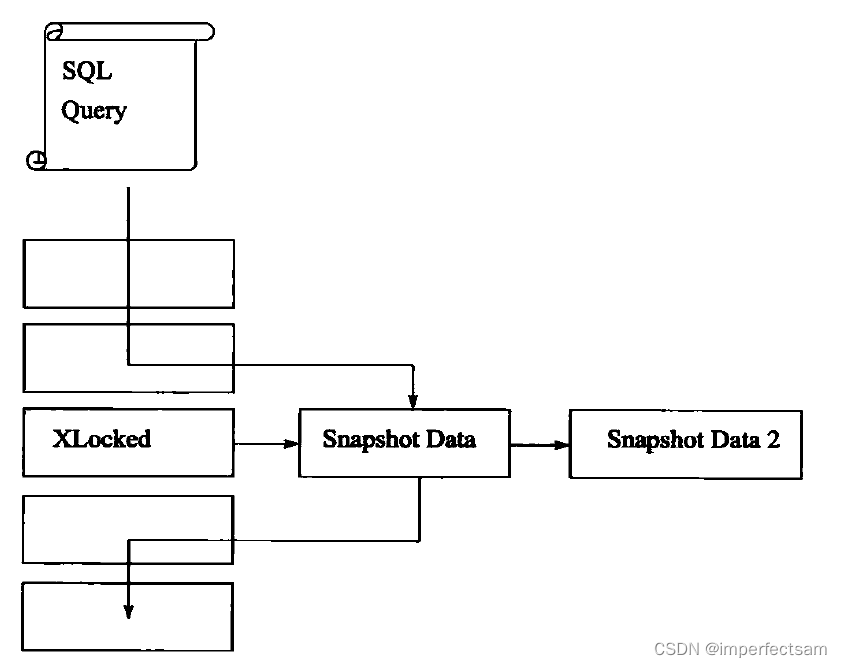
上图直观地展现了InoDB存储引擎一致性的非锁定读。之所以称其为非锁定读。之所以称其为非锁定读,因为不需要等待访问的行上X锁的释放。快照数据是指该行的之前版本的数据,该实现是通过undo段来完成。而undo用来在事务中回滚数据,因此快照数据本身是没有额外的开销。此外,读取快照数据是不需要上锁的,因为没有事务需要对历史的数据进行修改操作。
可以看到,非锁定读机制极大地提高了数据库的并发性。在InnoDB存储引擎的默认设置下,这是默认的读取方式,即读取不会占用和等待表上的锁。但是在不同事务隔离级别下,读取的方式不同,并不是在每个事务隔离级别下都是采用非锁定的一致性读。此外,即使都是使用非锁定的一致性读,但是对于快照数据的定义也各不相同。
通过上图可以知道,快照数据其实就是当前行数据之前的历史版本,每行记录可能有多个版本。就图所显示的,一个行记录可能有不止一个快照数据,一般称这种技术为行多版本技术。由此带来的并发控制,称之为多版本并发控制(Multi VersionConcurrency Control,MVCC)。
在事务隔离级别READ COMMITTED和REPEATABLE READ(InnoDB存储引擎的默认事务隔离级别)下,noDB存储引擎使用非锁定的一致性读。然而,对于快照数据的定义却不相同。在READ COMMITTED事务隔离级别下,对于快照数据,非一致性读总是读取被锁定行的最新一份快照数据。而在REPEATABLE READ事务隔离级别下,对于快照数据,非一致性读总是读取事务开始时的行数据版本。
接下来我们通过这个例子来验证一下:
首先我们创建表z,执行以下SQL:
```sql
DROP TABLE IF EXISTS `z`;
CREATE TABLE `z` (
`a` int(11) NOT NULL,
`b` int(11) NULL DEFAULT NULL,
PRIMARY KEY (`a`) USING BTREE,
INDEX `b`(`b`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = latin1 COLLATE = latin1_swedish_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of z
-- ----------------------------
INSERT INTO `z` VALUES (1, 1);
INSERT INTO `z` VALUES (3, 1);
INSERT INTO `z` VALUES (5, 3);
INSERT INTO `z` VALUES (7, 6);
INSERT INTO `z` VALUES (10, 8);
这里我们实验的是REPEATABLE READ这种隔离级别下的情况:
然后分别在会话A和会话B中执行以下顺序SQL:
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN; | |
| 2 | SELECT * FROM z WHERE b=3; | |
| 3 | BEGIN; | |
| 4 | UPDATE z SET a=5,b=2 WHERE b=3; | |
| 5 | SELECT * FROM z WHERE b=3; | |
| 6 | COMMIT; | |
| 7 | SELECT * FROM z WHERE b=3; | |
| 8 | COMMIT; |
这里我们通过在xshell中开启两个会话来实现。

这里我们可以清晰地看到会话A中三次查询读取的数据都是相同的,这样子就可以验证到在REPEATABLE READ事务隔离级别下,对于快照数据,非一致性读总是读取事务开始时的行数据版本(即会话A中的事务开始时的数据版本)。
并且这里我们可以观察到当我们在时间点2会话A进行查询的时候,并没有对b=3这行加上任何锁,因为会话B中在时间点4的SQL能够顺利地执行。
这里在时间点4进行了update这一个SQL对b=3上加了X锁,但是并不影响时间点5会话A的查询。这也验证了一点如果读取的行正在执行DELETE或UPDATE操作,这时读取操作不会因此去等待行上锁的释放。
然后我们再实验的是READ COMMITTED这种隔离级别下的情况:
这里需要首先在会话A和会话B中分别设置当前会话的事务隔离级别为READ COMMITTED,因为MySQL默认的是REPEATABLE READ隔离级别。
set session transaction isolation level read committed;
然后分别在会话A和会话B中执行以下顺序SQL:
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN; | |
| 2 | SELECT * FROM z WHERE b=3; | |
| 3 | BEGIN; | |
| 4 | UPDATE z SET a=5,b=2 WHERE b=3; | |
| 5 | SELECT * FROM z WHERE b=3; | |
| 6 | COMMIT; | |
| 7 | SELECT * FROM z WHERE b=3; | |
| 8 | COMMIT; |
执行的会话结果如下:
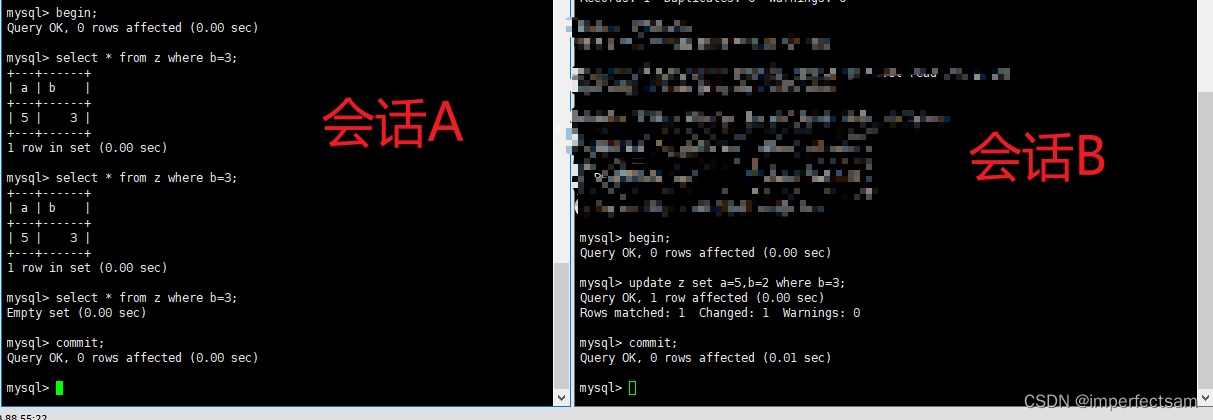
这里我们可以看到在时间点7会话A中执行的SQL再次查询的时候发现为空,没有数据了,与RR隔离级别有所不同。
注意:从数据库理论的角度来说,其违反了事务ACID中I的特性,即隔离性。这个后续文章会详细讲解一下。此文章只是简单地验证了一下。
二、一致性锁定读
在默认配置下,即事务的隔离级别为REPEATABLE READ模式下,InnoDB存储引擎的SELECT操作是使用一致性非锁定都的。但是在某些情况下,用户需要显式地去对数据库读取操作进行加锁以保证数据逻辑的一致性。而这要求数据库支持加锁语句,即使是对于SELECT的只读操作。InnoDB存储引擎对于SELECT语句支持两种一致性的锁定读(locking read)操作:
SELECT .....FOR UPDATE
SELECT ..... LOCK IN SHARE MODE
SELECTFOR UPDATE对读取的行记录加一个X锁,其他事务不能对已锁定的行加上任何锁。SELECT…LOCK IN SHARE MODE对读取的行记录加一个S锁,其他事务可以向被锁定的行加S锁,但是如果加X锁,则会被阻塞。
对于一致性非锁定读,即使读取的行已被执行了SELECT·FOR UPDATE,也是可以进行读取的,这和之前讨论的情况一样。此外,SELECT…FOR UPDATE,SELECT…LOCK IN SHARE MODE必须在一个事务中,当事务提交了,锁也就释放了。因此在使用上述两句SELECT锁定语句时,务必加上BEGIN,START TRANSACTION或者SET AUTOCOMMIT-0。
这里我们可以看一下以下这个例子:
这里我们实验的是REPEATABLE READ这种隔离级别下的情况:
然后分别在会话A和会话B中执行以下顺序SQL:
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | BEGIN; | |
| 2 | SELECT * FROM z WHERE b=3 LOCK IN SHARE MODE; | |
| 3 | BEGIN; | |
| 4 | SELECT * FROM z WHERE b=3; | |
| 5 | SELECT * FROM z WHERE b=3 LOCK IN SHARE MODE; | |
| 6 | SELECT * FROM z WHERE b=3 FOR UPDATE; | |
| 7 | COMMIT; | |
| 8 | COMMIT; |

时间点2会话A对b=3这一行数据加上了S锁
时间点3会话B对b=3这一行数据进行了一次一致性非锁定读,并且成功返回数据
时间点4会话B对b=3这一行数据进行了一次S锁,根据上篇文章的介绍S锁与S锁之间是能够共存的,所以这里成功地返回了数据
时间点5会话B对b=3这一行数据进行了一次X锁,根据上篇文章的介绍S锁与X锁之间是互斥的,所以这里会话B就进入了阻塞















 2107
2107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









