







作为一种很犀利的序列化的格式,avro在大数据量传输的时候很有优势。记录下。
1: .avsc 文件
{
"namespace": "com.avro.bean",
"type": "record",
"name": "UserBehavior3",
"fields": [
{"name": "userId", "type": "long"},
{"name": "itemId", "type": "long"},
{"name": "categoryId", "type": "int"},
{"name": "behavior", "type": "string"},
{"name": "timestamp", "type": "long"}
]
}这里定义上字段名称,以及对应的字段类型。
目录结构如下:
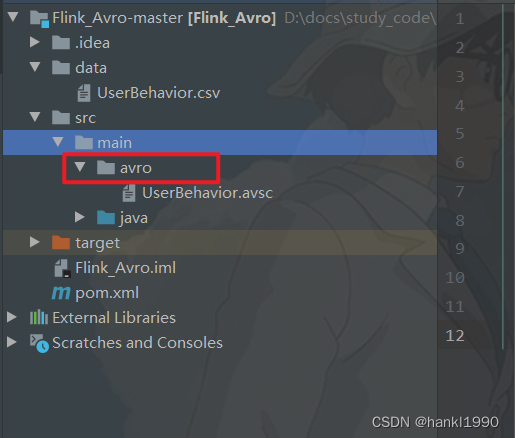
- 放在main下一会儿要编译,不一定非得放到main下,也可以放到别的目录下,但是要注意和pom文件里的对齐。

-
比如我放到另外的目录下: 那么对应的配置我们改为对应的目录即可: "namespace": "com.avro.bean",这里定义了我们放置的目录
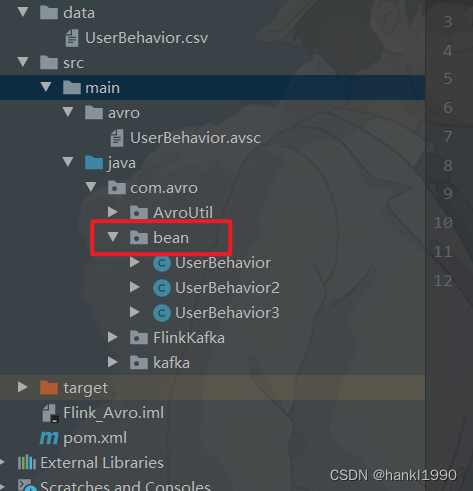
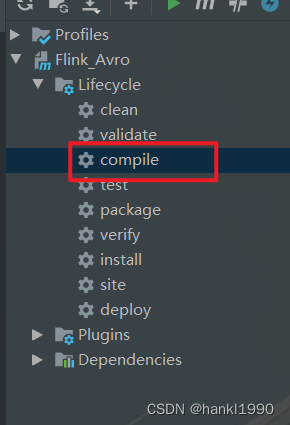
2:执行compile
java bean就自动生成了。
备注:需要引入的依赖:
<build>
<plugins>
<plugin>
<groupId>org.apache.avro</groupId>
<artifactId>avro-maven-plugin</artifactId>
<version>1.8.2</version>
<executions>
<execution>
<phase>generate-sources</phase>
<goals>
<goal>schema</goal>
</goals>
<configuration>
<sourceDirectory>${project.basedir}/src/main/avro/</sourceDirectory>
<outputDirectory>${project.basedir}/src/main/java/</outputDirectory>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<!-- 这个版本不要太老,如果是1.6或者以下的话 会报错,虽说不影响产生javabean -->
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
</plugins>
</build>














 3256
3256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









