







参考Siamese Network (应用篇3) :孪生网络用于图像块匹配 ACCV2016 - 云+社区 - 腾讯云
参看论文:Melekhov I, Kannala J, Rahtu E, et al. Image patch matching using convolutional descriptors with Euclidean distance[C]. asian conference on computer vision, 2016: 638-653.
会议水平:ACCV 2016,
供稿单位:芬兰阿尔托大学计算机科学系、芬兰奥卢大学机器视觉研究中心
Finding correspondences between image regions (patches) is a key factor in many computer vision applications. For example, structure-from-motion, multi-view reconstruction, image retrieval and object recognition require accurate computation of local image similarity. Due to importance of these problems various descriptors have been proposed for patch matching with the aim of improving accuracy and robustness. Many of the most widely used approaches, like SIFT or DAISY descriptors, are based on hand-crafted features and have limited ability to cope with negative factors (occlusions, variation in viewpointetc.) making a search of similar patches more difficult. Recently, various methods based on supervised machine learning have been successfully applied for learning patch descriptors. These methods significantly outperform hand-crafted approaches and inspire our research.(背景这一段话,作者写出了艺术...)
1. 摘要及目标
作者提出一种适用于图像块匹配的的图像描述子(名字起的很好听,convolutional descriptor,卷积描述子)。图匹配是很多计算机视觉应用领域非常基础的问题。作者从最近深度学习在目标检测和分类任务取得的成功受到了启发。作者开发了一个模型,将原始的输入图像块映射成一个低为的特征矢量,那么两个低维特征越小,图像块就越相似,(large otherwise)。作为一个距离测度,作者选用了L2范数,也就是我们说的欧拉距离,这个距离测度很快并广泛用于评价大多数hand-crafteddescriptors,例如SIFT。 作者的方法输出了艺术级的基于L2的描述子,这个描述子可以直接取代SIFT。此外作者采用batch normalization 和 histogram equalization对原始的输入图像进行预处理。结果表明(confirm),这些手段可以进一步提升描述子的性能。最后作者也初步讨论了将Spatial Transformer Network添加到卷积神经网络后面的效益,并提供了初步结果。
目标:
we aim to create a CNN-based discriminative descriptor for patch matching task.
作者想要基于CNN设计一个判别描述子用于图像匹配工作。
2. 方法与细节
我们先看一下正负样本:

(a) positive pairs (b) negative pairs
图一:这是作者给出的正负样本对的实例。孪生网络(不谈论衍生的双通道和空间系数两个事)有三个输入(X0,X1,Y)也就是我们通常说将对抗样本图像对和答案(标签)。对于正样本图像对,他们具有相同的3D结构、方向、尺度、位置大致应该是对应的。但是他们也存在视角和光照的变化。负样本的差异性就很大了...
comment:作者采用这样的数据集还是有点嫌疑的,因为匹配问题有很多应用,但就从多视角重建而言,算是匹配问题中比较简单的问题,如果应用于图像检索领域就更有说服力了。
2.1 方法
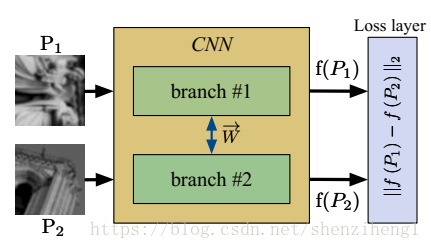
图2. 作者的模型结构
通过作者的模型结构,我们可以很明显的看出来,做的就是为了设计一个tailored metric distance。这个模型模型包括两个相同的特征描述子提取网络(我们一般叫做孪生网络,共享权重和参数)。然后将提取到的特征传递到决策层,可以看到作者在这里直接使用了L2范数,也就是我们说的欧式距离。
comment:关于用全连接层学习一个隐式距离衡量,还是直接利用显示的距离度量?这里我更偏向于显式方法。一方面参数量大大减少;另一方面end-to-end优化方式可以避免特征提取层和决策层不匹配的情况。
损失函数:

普通的hinge损失函数,确实没有亮点...

图3. 正负样本在训练前后的特征距离分布。通过学习可以降低正样本的距离,增加负样本的距离
网络结构:
convBlock[32,3,1,1]-convBlock[64,3,1,1]-pool[2]-convBlock[64,3,1,1]-convBlock[64,3,1,1]-pool[2]-convBlock[128,3,1,1]- convBlock-[128,3,1,1]-pool[3]-convBlock[128,3,1,1]-L2norm.
shorthand notation: convBlock[N,w,s,p] consists of a convolution layer with N filters of size w × w with stride s and padding p, a regularisation layer (ReLU) and batch normalisation, pool[k] is a max-pooling layer of size k×k applied with stride k.
comment: 作者的经验。1.作者对不同的卷积层进行实验,发现这样设计的7层卷模块效果是最好的;2.作者做实验发现,使用全连接层作为效果并不是那么好。(只一点还是很奇怪的,传言中说网络深度越深,越复杂,一般情况下性能更好;3.作者非常受益于批归一化Batch Normalization 和 histogram equalization。
看一下这一部分的结果:

图4. 对于不同模型结构和预处理方法的精度-召回率曲线
comment: Batch Normalization 仅仅是进行了独立同分布的近似处理,收敛速度快是很自然的了,这精度提高的也太多了吧?恐怖...
2.2 细节
1. 直方图均衡化和批归一化可以大大提升描述子的精度
2.作者探索了不同描述子产生的架构,并进行评价 (我猜测这也是作者能中稿的原因,实验做得多)
3.作者探讨了对原始图像进行预处理将可能得到的收益 (batch normalization 刚提出来不久 他就用了...)
4.作者尝试性使用Spatial Transformer Network (我猜测这也是作者能中稿的原因,研究的内容新)
5.数据增强-to prevent overfitting we used the same approach as [8] and augmented training data applying affine transformation by rotating both patches in pairs to 90, 180, 270 degrees and flipping them horizontally and vertically.为了防止过拟合,我们采用仿射变换的方法对训练数据进行数据增强。具体为对图像对进行水平、垂直旋转,以及90,180,270旋转。
3.3 空间变换网络 Spatial Transformer Network
空间变换网络的利用让模型学习了对平移、尺度变换、旋转和更多常见的扭曲的不变性,这也使得模型在一些基准数据集和变换分类上效果最好。可以参考博客:论文笔记:Spatial Transformer Networks(空间变换网络)_Meringue's Blog-CSDN博客
性能上并没有很大的提高
3. 结果 结论


Bold numbers are the best across all algorithms
这篇文章作者利用深度网络为图像块提取描述子。几个亮点:
1.预处理方法还是有必要做一下
2.结合最新的东西做一下,即使可能没啥用... 跟时髦的能力...
4. 补充材料
4.1 利用CNN作为描述子评估图像块相似度的鼻祖文章:
Jahrer, M., Grabner, M., Bischof, H.: Learned local descriptors for recognition and matching. Computer Vision Winter Workshop (2008)
Osendorfer, C., Bayer, J., Urban, S., van der Smagt, P.: Convolutional neural networks learn compact local image descriptors. In: Neural Information Processing - 20th International Conference, ICONIP. (2013) 624{630
第一个采用Siamese Network进行大规模图像匹配研究的(作者的创新点源于此文章):
Lin, T.Y., Cui, Y., Belongie, S., Hays, J.: Learning deep representations for groundto-aerial geolocalization. In: Computer Vision and Pattern Recognition (CVPR),
2015 IEEE Conference on. (2015)
4.2 孪生网络+全连接层进行图像相似度测度研究的:
comment:对于用一组全连接层作为决策网络,我还是持有保留意见的,全连接层确实可以学习到一个非常复杂的度量矩阵,但是参数有点多,在追求速度的应用上还是要谨慎。
Zagoruyko, S., Komodakis, N.: Learning to compare image patches via convolutional neural networks. In: The IEEE Conference on Computer Vision and Pattern
Recognition (CVPR). (2015)
comment:这篇文章我们进行研究过的,唯一的一个纠结点在于最后一个全连接层输出上,作者虽然利用一个神经网络的全连接层进行降维输出,但是是否需要进行约束,如增加soft_max或者增加显式的距离判据,还是值得讨论。
Han, X., Leung, T., Jia, Y., Sukthankar, R., Berg, A.C.: Matchnet: Unifying feature and metric learning for patch-based matching. In: The IEEE Conference on Computer Vision and Pattern Recognition (CVPR). (2015)
comment:这篇文章即将进行研读...
Simo-Serra, E., Trulls, E., Ferraz, L., Kokkinos, I., Fua, P., Moreno-Noguer, F.: Discriminative learning of deep convolutional feature point descriptors. Interna-tional Conference on Computer Vision (2015)
comment:这篇文章我们进行研究过的
4.3 Spatial Transformer Network
Jaderberg, M., Simonyan, K., Zisserman, A., Kavukcuoglu, K.: Spatial transformer networks. In: Advances in Neural Information Processing Systems 28. (2015) 2017



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











