









给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words, 返回所有二维网格上的单词 。单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
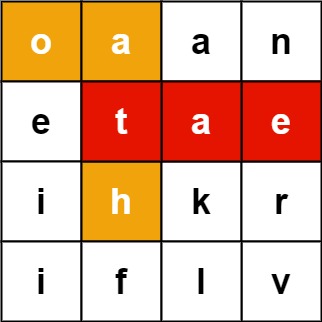
输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"] 输出:["eat","oath"]
示例 2:

输入:board = [["a","b"],["c","d"]], words = ["abcb"] 输出:[]
前言
本题共四种解法,其中解3能达到时间空间双百,均击败100%;解4能达到时间最优击败100%,但空间较差,击败30%这样。解3、4时间性能稳定击败99.3%以上。解1、2性能中等,解1时间性能在56-59%之间,空间65%+;解2时间性能46-49%,空间稳定击败99%+。
解3、4时间性能极优的原因是:新增了一个剪枝。在处理上下左右时并不是使用数组得到四个方向,而是增加了代码长度简化了处理。本题解中代码部分注释较为详尽,因此实现原理上不作过多说明。运行提交时自行删除注释可提升部分性能。
本题的一个大坑在于,如果将字符矩阵board作为深搜函数的参数,需要使用引用类型,否则妥妥超时,官方解就是加了引用才没超时。即dfs(vector<vector<char>>& board, xxx, xxx),若为dfs(vector<vector<char>> board, xxx, xxx)可以说基本必超时。当然把board复制给一个全局变量,减少函数传参board也行。这题其实还可以用双前缀树实现,但是性能肯定会拉,毕竟字符矩阵生成前缀树会存在太多无用分支。只要是将字符矩阵生成所有可能单词的前缀树,就会有较多无用分支,就会拉低性能,所以这里就不实现了。
1、前缀树 + dfs
先将words所有单词加入前缀树。然后遍历字符矩阵所有字符,从该字符开始检索匹配前缀树,若匹配成功,则加入单词到结果矩阵,并且前缀树节点删掉该终止标志。其实还能再优化,在前缀树递归匹配到叶子结点时,可以删除叶子结点。这一点在解4实现了。这样可以缩减已匹配的节点,减少重复查找已匹配的路径。
具体代码实现如下:
// 212. 单词搜索 II:即相当于一个n * m的字符矩阵,其中横、竖相邻的字符可以连成单词,并且可以横竖组合,移动任意。可以左到右,也可以右到左;可以
// 上到下,也可以下到上。矩阵行、列最多为12
// 现在给出一个词库words,为一维数组,找出词库的所有单词中能在字符矩阵中连成的所有单词。words最多3*10^4个单词
// 因为单词可以从字符矩阵中任意字符出发,从1个字符构造到m*n个字符的单词,那么最多构造出m^2 * n^2个单词,当然暴力解也是可以的
// 由字符矩阵从前缀树中搜索匹配单词。刚好和我的方法相反,我是由前缀树,到字符矩阵或非去重前缀图中去搜,所以超时。
// 淦,感觉被耍了,好低级的方法。纯粹就是先生成前缀树,然后遍历字符矩阵中的各个字符,去查找前缀树是否有匹配的字符,若找到单词,
// 则加入结果数组中即可。
// 和官方解1答案一模一样,而且部分细节,自认为优化了,然后我超时?怀疑官方解1走后门过的所有用例。
// 超时原因很明显,就是函数传参中的字符矩阵参数较大,如若不使用引用传值,调用dfs函数次数过多,此时board变量为参数复制传值,
// 就会导致超时。将board函数参数改为引用&类型就通过了。但其实之前还是不能通过,官方上调了时间阈值才过的。
// 原因是官方解题器在处理unordered_set时会性能远劣于set,官方已作为问题单处理。
// 最终优化:
// 在上调时间阈值前,优化特别多才提交通过。即将board复制给一个全局变量,然后删掉函数参数中的board,改为使用全局变量,使得
// 理论性能远优于官方解1,才保证稳过的。
// 时间小优56-59,空间很优46-82,基本65+。
// 优化尝试:
// 将dfs递归函数改成函数内定义函数。
// function<void (int, int, int, int, Trie3*)> dfs = [&](int row, int col, int r, int c, Trie3* root)
// 时间略差32-52,基本44;空间很优21-90,基本75+。所以不建议改。
class Trie3 {
public:
string word = "";
unordered_map<char, Trie3*> children; // 记录所有孩子节点
Trie3(): word("") {}
// 往前缀树中添加单词
void addWord(const string& w) {
Trie3* node = this;
for(auto &&ch : w) {
if(node->children.find(ch) == node->children.end()) {
node->children[ch] = new Trie3;
}
node = node->children[ch];
}
node->word = w;
}
};
class Solution {
public:// .
const int dirs3[4][2] = {{-1, 0},{1, 0},{0, -1},{0, 1}}; // 定义上下左右四个方向
vector<string> result;
vector<vector<char>> b; // 等于字符矩阵,减少参数传参
// 深搜匹配单词
void dfsFindAllWords(int row, int col, int r, int c, Trie3* root) {
char ch = b[r][c];
// 检查子节点是否存在该字符,若不存在则返回false
if(root->children.find(ch) == root->children.end()) {
return;
}
root = root->children[ch]; // root指向子节点
// 先检查当前节点是否为单词结束节点,若为则加入结果set
if(root->word.size() > 0) {
result.emplace_back(root->word);
root->word = "";
}
b[r][c] = '#'; // 标志当前位置已访问
int r_new = 0, c_new = 0; // 记录新的行、列
// 遍历四个方向
for(auto &&dir : dirs3) {
r_new = r + dir[0], c_new = c + dir[1];
// 当前节点未遍历过则深搜
if(r_new >= 0 && r_new < row && c_new >= 0 && c_new < col && b[r_new][c_new] != '#') {
dfsFindAllWords(row, col, r_new, c_new, root);
}
}
b[r][c] = ch;
}
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
Trie3* root = new Trie3;
// 先生成前缀树
for(auto &&word : words) {
root->addWord(word);
}
b = board;
int row = board.size(), col = board[0].size();
// 遍历字符矩阵,找出所有可以匹配的单词
for(int i = 0; i < row; i++) {
for(int j = 0; j < col; j++) {
dfsFindAllWords(row, col, i, j, root);
}
}
return result;
}
};2、set+dfs
这一个实现更加简单粗暴,相当于将解1的前缀树用unordered_set完全给替代了,使用unordered_set存储了words中的所有单词。仍然是从字符矩阵所有字符开始查找,但不同的是这个dfs到10层则退出深搜,因为题目规定单词最长长度为10。dfs搜索长度不超过10的串str,若str在unordered_set出现,则加入到结果数组,并从unordered_set删除该单词str。时间略逊于解1,但是空间性能稳定击败99%以上。
代码实现如下:
// 不用前缀树,直接把所有word存到unordered_set中,然后遍历字符矩阵,用一样的方式深搜查找单词,当深度达到10时,停止继续深搜,
// 因为题目明确规定单词长度最多10.
// 因为要遍历一遍字符矩阵的每个字符,然后深搜,深搜时会上传字符矩阵,所以一定要使用引用才不会超时,
// 否则调用dfs函数次数过多,此时board变量为参数复制传值,就会导致超时。将board函数参数改为引用&类型即可.
// 时间性能一般46-47;空间性能极优99+。
// 小优化:
// 将函数参数全部提取成全局变量实现,board、row、col。时间性能提升一点点46-49;空间下降一点98-99。因此建议不改
class Solution {
public:
static constexpr int dirs3[4][2] = {{-1, 0},{1, 0},{0, -1},{0, 1}}; // 定义上下左右四个方向
unordered_set<string> all_words3;
vector<string> result3;
// 深搜匹配单词
void dfsFindAllWords(vector<vector<char>>& board, int row, int col, int r, int c, string pre) {
char ch = board[r][c];
// 当前找到匹配的单词,则存入结果数组中,并从set集合中删除单词
if(all_words3.find(pre) != all_words3.end()) {
all_words3.erase(pre);
result3.emplace_back(pre);
}
// 若当前字符长度大于10则返回,终止深搜
if(pre.size() == 10) {
return;
}
board[r][c] = '#'; // 标志当前位置已访问
int r_new = 0, c_new = 0; // 记录新的行、列
// 遍历四个方向
for(auto &&dir : dirs3) {
r_new = r + dir[0], c_new = c + dir[1];
// 当前节点未遍历过则深搜
if(r_new >= 0 && r_new < board.size() && c_new >= 0 && c_new < board[0].size() && board[r_new][c_new] != '#') {
dfsFindAllWords(board, row, col, r_new, c_new, pre + board[r_new][c_new]);
}
}
board[r][c] = ch;
}
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
all_words3.insert(words.begin(), words.end());
int row = board.size(), col = board[0].size();
// 遍历字符矩阵,深搜找出所有可以匹配的单词,存入结果矩阵
for(int i = 0; i < row; ++i) {
for(int j = 0; j < col; ++j) {
dfsFindAllWords(board, row, col, i, j, string(1, board[i][j]));
}
}
return result3;
}
};3、剪枝+dfs
这个其实是针对本题用了一定取巧的方式,泛用性不算特别强。该方法遍历一遍字符矩阵,然后记录矩阵中的所有字符以及对应下标到一个map[ch, vector<pair<x, y>>]中。然后遍历words中的所有单词word,从map[word[0]]中的所有位置开始匹配,查看该单词是否能匹配。
重点:该题性能高的最关键点在于剪枝,在搜索一个单词时,会先遍历一遍该单词中,若单词中出现map中没有的字符,则说明字符矩阵中没有该字符。进而说明该单词绝对无法在字符矩阵中生成。然后跳到下一个单词。第二个较为关键的点在于,对于单词的处理。若单词长度大于5,且前面四个字符均相等,则翻转该单词,再去字符矩阵中查找。例如:aaaab 变为baaaa。因为既然aaaab能找到,那么一定能找到逆序的baaaa。这样做的好处在于节省起点个数,例如从4个a为起点展开搜索,肯定劣于从b为起点展开搜索
具体代码实现如下:
// 212. 单词搜索 II:即相当于一个n * m的字符矩阵,其中横、竖相邻的字符可以连成单词,并且可以横竖组合,移动任意。可以左到右,也可以右到左;可以
// 上到下,也可以下到上。矩阵行、列最多为12
// 现在给出一个词库words,为一维数组,找出词库的所有单词中能在字符矩阵中连成的所有单词。words最多3*10^4个单词
// 因为单词可以从字符矩阵中任意字符出发,但是因为单词规定最长长度为10,所以从1个字符构造到10个字符的单词
// 该方法其实是针对题目钻了空子,使用契合的方式,来实现时间、空间均99+的极优性能。没有借鉴性,自己实现一遍就不用管了。
// 时间极优99.3-100,基本99.9;空间极优99.3-99.9。
class Solution {
public:
// 上下左右四个方向深搜检索单词word,使用取巧的方式,代码长度换减少判断
bool dfsFindWord(vector<vector<char>>& board, int r, int c, const string& word, int index) {
// 若当前index = word.size - 1,则说明单词完全匹配,返回true
if(index == word.size() - 1) {
return true;
}
char temp = board[r][c], ch = word[++index];
board[r][c] = 0; // 标记当前节点已访问
int new_r = 0, new_c = 0; // 记录新行、列
// 上
new_r = r - 1;
if(new_r >= 0 && board[new_r][c] == ch) {
// 若找到单词,则直接返回
if(dfsFindWord(board, new_r, c, word, index)) {
board[r][c] = temp;
return true;
}
}
// 下
new_r = r + 1;
if(new_r < board.size() && board[new_r][c] == ch) {
// 若找到单词,则直接返回
if(dfsFindWord(board, new_r, c, word, index)) {
board[r][c] = temp;
return true;
}
}
// 左
new_c = c - 1;
if(new_c >= 0 && board[r][new_c] == ch) {
// 若找到单词,则直接返回
if(dfsFindWord(board, r, new_c, word, index)) {
board[r][c] = temp;
return true;
}
}
// 右
new_c = c + 1;
if(new_c < board[0].size() && board[r][new_c] == ch) {
// 若找到单词,则直接返回
if(dfsFindWord(board, r, new_c, word, index)) {
board[r][c] = temp;
return true;
}
}
board[r][c] = temp;
return false;
}
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
vector<string> result = {}; // 记录能匹配的单词
unordered_map<char, vector<pair<int, int>>> indexs; // 记录字符矩阵所有字符的矩阵下标
int row = board.size(), col = board[0].size();
// 字符矩阵元素存入map中
for(int i = 0; i < row; ++i) {
for(int j = 0; j < col; ++j) {
indexs[board[i][j]].emplace_back(i, j);
}
}
// 遍历words中所有单词
for(auto &&word : words) {
bool flag = false;
// 检查word所有字符是否字符矩阵中都能找到
for(auto &&ch : word) {
// 若找不到则直接搜索下一个单词
if(indexs.find(ch) == indexs.end()) {
flag = true;
break;
}
}
// 当前word中存在字符矩阵中找不到的字符,不再判别该单词
if(flag) {
continue;
}
string new_word = word;
// 若当前单词长度前四个字母都相同,则翻转一下生成新单词,如:aaaab 变为 baaaa
if(word.size() > 5 && word[0] == word[1] && word[1] == word[2] && word[2] == word[3]) {
reverse(new_word.begin(), new_word.end());
}
// 从word的第一个字符开始检索该单词,看能否找到。遍历map中所有该字符的坐标
for(auto &&[r, c] : indexs[new_word[0]]) {
if(dfsFindWord(board, r, c, new_word, 0)) {
result.emplace_back(word);
break;
}
}
}
return result;
}
};
4、前缀树+剪枝+dfs
分析:
该实现其实就是在解3的基础上,将words所有单词先生成前缀树,然后用相同的剪枝做法,从前缀树根节点开始到字符矩阵中搜索。
不同的是,解3的匹配单词,解4是匹配前缀树的子节点,当节点为单词终止字符时,则将单词存入结果数组中。
并且该解法优化的一点在于,当节点为叶子结点时,先检查是否为单词终止字符(因为该叶子结点可能是不断删除叶子以后才变成的叶子结点,其保留的单词可能早就被取走了),再删除叶子结点。这样就能删掉已经找出所有单词的路径,节省重复路径搜索。
理论性能应该明显优于解3,毕竟前缀树对words进行了合并,不用遍历那么多单词字符,但实际时间性能却还略逊与解3,差0.5%这样。空间性能不用说,肯定远逊于解3。如果words的单词量再往上递增,应该是解4时间性能最优。
具体代码实现如下:
// 212. 单词搜索 II:即相当于一个n * m的字符矩阵,其中横、竖相邻的字符可以连成单词,并且可以横竖组合,移动任意。可以左到右,也可以右到左;可以
// 上到下,也可以下到上。矩阵行、列最多为12
// 现在给出一个词库words,为一维数组,找出词库的所有单词中能在字符矩阵中连成的所有单词。words最多3*10^4个单词
// 因为单词可以从字符矩阵中任意字符出发,但是因为单词规定最长长度为10,所以从1个字符构造到10个字符的单词,那么最多构造出
// m^2 * n^2个单词,
// 该方法其实是针对题目钻了空子,使用契合的方式,来实现时间、空间均99+的极优性能。没有借鉴性,自己实现一遍就不用管了。
// 时间极优99-100,空间极优99。
// 优化:
// 使用前缀树改进一遍。
// 其实时间性能似乎反而下降了一点,空间性能下降极其多。时间性能98.8-99.9,基本99.3+;空间很差27-35,基本33+.
class Solution {
public:
vector<string> result = {}; // 记录能匹配的单词
struct trie {
unordered_map<char, trie*> children;
string word;
trie(): word("") {};
trie* addWord(const string& w) {
trie* node = this;
for(auto &&ch : w) {
if(node->children.find(ch) == node->children.end()) {
node->children[ch] = new trie;
}
node = node->children[ch];
}
return node;
}
};
// 上下左右四个方向深搜检索单词word,使用取巧的方式,代码长度换减少判断
bool dfsFindWord(vector<vector<char>>& board, int r, int c, trie*& root) {
// 若当前root节点为单词末尾节点,则加入单词。并删除该节点的单词
if(root->word.size() > 0) {
result.emplace_back(root->word);
root->word = "";
}
// 若当前遍历到前缀树叶子结点,则说明匹配成功,删除叶子结点
if(root->children.size() == 0) {
return true;
}
char temp = board[r][c];
board[r][c] = 0; // 标记当前节点已访问
bool flag = true; // 记录当前root的所有孩子节点是否都匹配
char ch; trie* node; // 记录当前前缀树节点对应字符、子节点
int new_r = 0, new_c = 0; // 记录新行、列
// 遍历当前root的所有子节点
for(auto it = root->children.begin(); it != root->children.end();) {
ch = it->first, node = it->second;
// 遍历上下左右四个方向进行匹配
// 上
new_r = r - 1;
if(new_r >= 0 && board[new_r][c] == ch) {
// 若找到单词,则直接返回
if(dfsFindWord(board, new_r, c, node)) {
++it;
// 如果匹配到了叶子结点,则删除叶子结点
if(node->children.size() == 0) {
root->children.erase(ch);
}
continue;
}
}
// 下
new_r = r + 1;
if(new_r < board.size() && board[new_r][c] == ch) {
// 若找到单词,则直接返回
if(dfsFindWord(board, new_r, c, node)) {
++it;
// 如果匹配到了叶子结点,则删除叶子结点
if(node->children.size() == 0) {
root->children.erase(ch);
}
continue;
}
}
// 左
new_c = c - 1;
if(new_c >= 0 && board[r][new_c] == ch) {
// 若找到单词,则直接返回
if(dfsFindWord(board, r, new_c, node)) {
++it;
// 如果匹配到了叶子结点,则删除叶子结点
if(node->children.size() == 0) {
root->children.erase(ch);
}
continue;
}
}
// 右
new_c = c + 1;
if(new_c < board[0].size() && board[r][new_c] == ch) {
// 若找到单词,则直接返回
if(dfsFindWord(board, r, new_c, node)) {
++it;
// 如果匹配到了叶子结点,则删除叶子结点
if(node->children.size() == 0) {
root->children.erase(ch);
}
continue;
}
}
flag = false; // 当前有root的孩子节点未匹配
++it;
}
board[r][c] = temp;
return flag;
}
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
unordered_map<char, vector<pair<int, int>>> indexs; // 记录字符矩阵所有字符的矩阵下标
int row = board.size(), col = board[0].size();
// 字符矩阵元素存入map中
for(int i = 0; i < row; ++i) {
for(int j = 0; j < col; ++j) {
indexs[board[i][j]].emplace_back(i, j);
}
}
trie* root = new trie;
// 遍历words中所有单词,将符合条件的单词加入前缀树,并适当控制翻转
for(auto &&word : words) {
bool flag = false;
// 检查word所有字符是否字符矩阵中都能找到
for(auto &&ch : word) {
// 若找不到则直接搜索下一个单词
if(indexs.find(ch) == indexs.end()) {
flag = true;
break;
}
}
// 当前word中存在字符矩阵中找不到的字符,不再判别该单词
if(flag) {
continue;
}
string new_word = word;
// 若当前单词长度前四个字母都相同,则翻转一下生成新单词,如:aaaab 变为 baaaa
if(word.size() > 5 && word[0] == word[1] && word[1] == word[2] && word[2] == word[3]) {
reverse(new_word.begin(), new_word.end());
}
// 加入前缀树,并使得末尾节点指向原单词
(root->addWord(new_word)->word) = word;
}
// 从前缀树根节点的所有孩子开始,遍历前缀树。同时匹配字符矩阵
for(auto &&[ch, node] : root->children) {
for(auto &&[c, r] : indexs[ch]) {
if(dfsFindWord(board, c, r, node)) {
break;
}
}
}
return result;
}
};















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











