







这个课程把Union-Find作为第一讲,也借助这个问题来阐述如何科学、合理的构建一个好的算法。
构建算法的主要步骤如下:
- 为问题建模
- 构建一个解决问题的算法
- 算法够快吗?存储空间是否合适?
- 如果不够快或需要很大的存储空间,寻找原因
- 尝试解决速度与存储空间问题
- 不断尝试优化直到符合要求
动态连接问题(dynamic connectivity)
有N个独立的对象,每两个对象之间有两种状态,即连接状态与非连接状态,可以对这些对象进行两个操作,一个是Union,就是把两个对象连接起来,Find,查询两个对象是否处于连接状态。
在实际问题中对象有哪些呢?
- 照片中的像素点
- 网络中的每台计算机
- 社交网络中的每个人
- 计算机芯片中的每个晶体管
- 数学集合中的每个元素
- 程序中的每个变量
- 一个整体系统中的金属部件
定义连接(Connection):
- 反身性(每个对象与自身是连接的)
- 对称性(p与q是连接的,则q与p也是连接的)
- 传递性(p与q是连接的,q与r是连接的,则p与r也是连接的)
定义连接集合(Connected Components):
连接起来的对象组成的最大的集合。
例如下面的8个对象组成3个连接集合
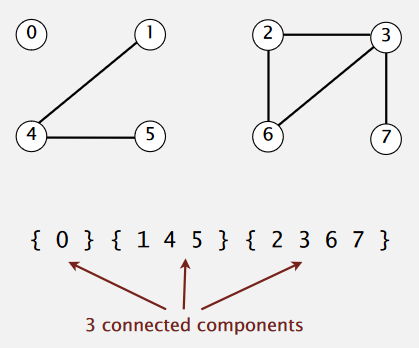
两个操作:
Find
查询两个对象是否在一个集合里。
Union
如果两个对象不在一个集合里,合并两个集合
数据类型及API
目标:为算法设计高效的数据结构
- 对象的数目N可能很大
- 操作次数M可能很大
- 查询与连接可能有交叉(例如进行连接前先进行查询操作)

你可能会想,so easy,记录每一个对象所属的连接集合,查询时直接对比,不就行了么?对,这就是Quick-find 算法,为每个对象设立一个id,记录它所属的连接集合
Find Query,如果两个对象的id是相同的,那么它们就是处于连接状态的。
Union command 连接p,q时, 将所有与p有相同id的对象的id,全部更改为q的id。
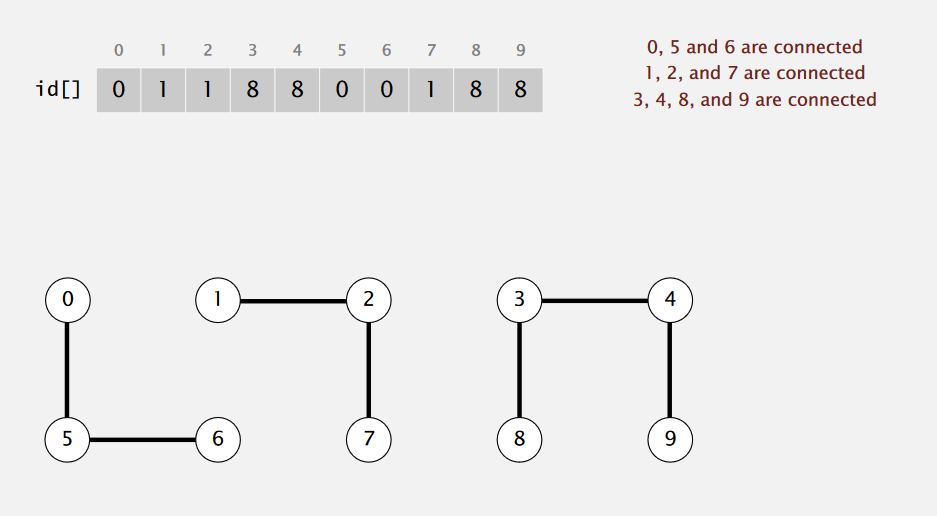
例如,把对象1连接到对象8上,就需要查询所有的对象的id,把id为1的全部改为8
可以把这种结构看作一棵深度只有一层的扁平的树,在进行连接时,把所有的子树都移到了根节点上,但它的缺点是太慢了。每次都需要遍历所有的对象来寻找与p有相同id的对象并更改它们的id。
那么你可能会想了,在进行Union时,直接把1连接到8上就可以了,查询时,只需要查询两个对象是不是有相同的根节点不就就可以了嘛。这就是Quick-union算法,把所有对象按照树结构来进行存储,依然为每个对象设立一个id,id[i]是对象i的父节点
Find Query 如果两个对象的根节点是相同的,那么它们就是处于连接状态的。
Union command 如果连接p,q, 那么将p的id改为q的id,即id[p]= id[q]。
但这样又带来一个新的问题,就是树可能长的很高,当树很高的时候,查询一个对象的根节点就很耗时。
那么能不能想个办法让树不要长高呢?看下面这个图,如果两个树合并的话,大树作为小树的子树,样子难看,效果肯定也很差嘛,那就加个判断吧,多用一个数组存储每个树所包含的对象数目,在进行树的合并的时候,把小的树(对象少的)作为大的树(对象多的)的子树,这就是Weighted Quick-Union算法。
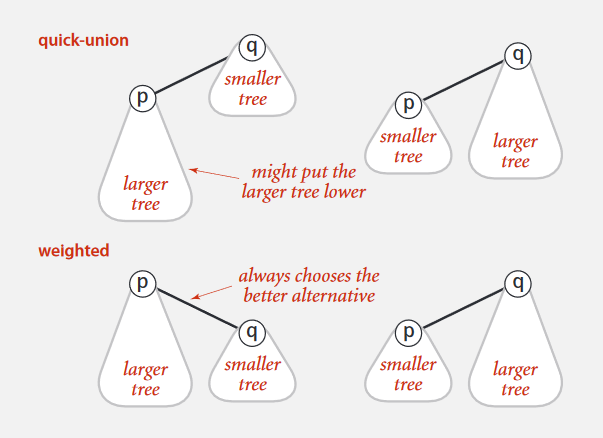
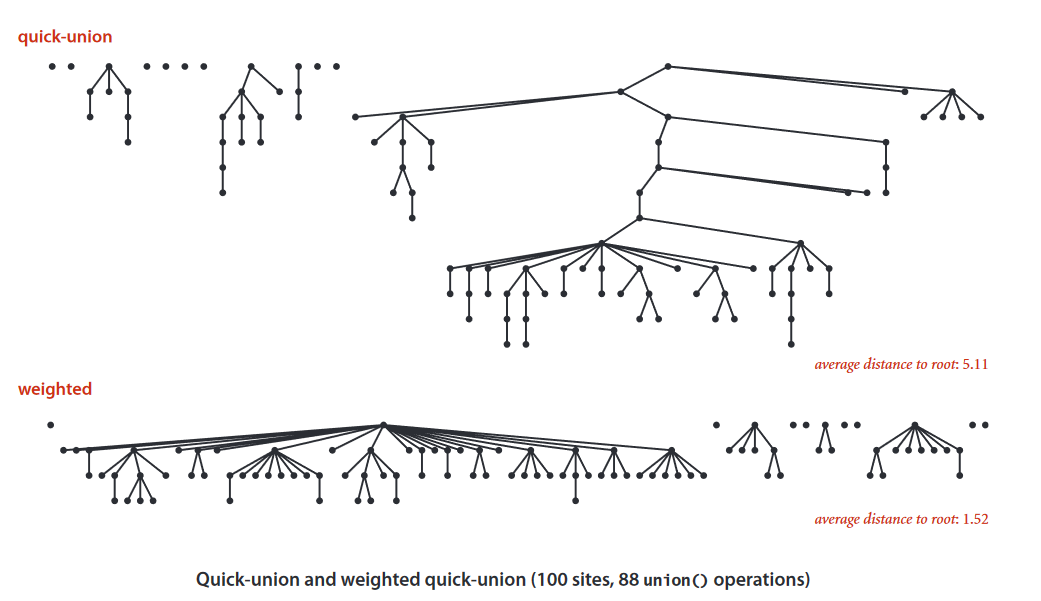
从上图可以看到,Weighted Quick-Union 得到的树就扁平的多。
Weighted Quick-Union中,任意一个节点的深度<=lgN。
思考一下什么时候一个节点的深度会增加呢?当它处于较小的树的时候,
因为 N1<=N2,
所以 lg(N1+N2) >= lg(N1+N1) = 1+lg(N1) >= 1+depth(x) = new_depth(x)
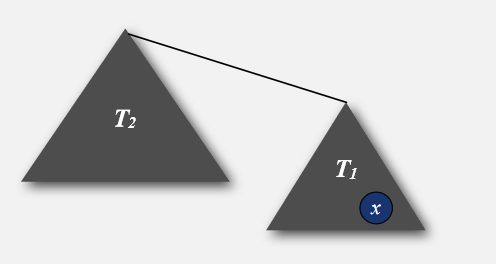
说白了,就是Weighted Quick-Union 就是在Quick-Union的基础上压缩了路径(树高)嘛!能不能进一步再压缩一下呢?
课上介绍了两种方式,
一是在查询时,增加一个循环,将每一个查询路径上的节点都直接连接到根上。
另一个是将每个查询路径上的节点直接连接到它的祖父节点上。
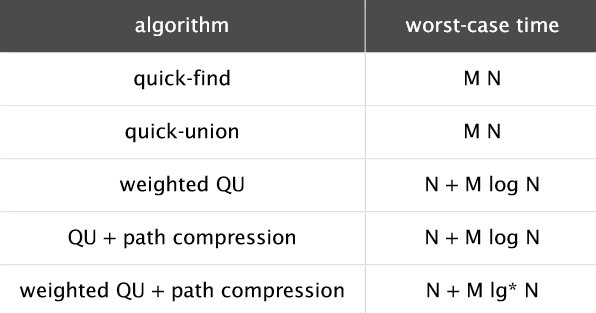
最终各个算法效率的比较见下图。
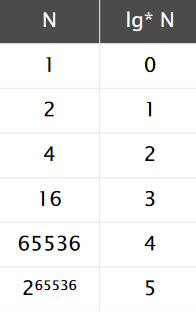
理论上,WQUPC不是线性的,但从实际使用中来看,可以认为是线性的。
















 2446
2446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









