







模拟退火算法是一种受 固体退火过程 启发的元启发式优化算法,广泛应用于 组合优化 和 复杂函数优化 问题。其核心思想是通过 概率性接受劣解 的策略,逐步降低搜索的随机性,最终收敛到全局最优或近似最优解。本文以旅行商问题为例,详细阐述模拟退火算法的设计思想,并解析模拟退火算法的执行过程中的作用原理。
模拟退火算法的核心步骤包括:初始解生成 → 邻域搜索 → 接受准则判断 → 温度更新,循环迭代直至满足终止条件。
一. 以旅行商问题(TSP)为例的模拟退火算法设计
1. 问题描述
- 旅行商问题(TSP):给定 nn 个城市及其两两之间的距离,找到一条访问每个城市恰好一次并返回起点的最短回路。
- 目标函数:最小化路径总长度 f(π)=∑i=1ndπ(i),π(i+1)f(π)=∑i=1ndπ(i),π(i+1),其中 π(n+1)=π(1)π(n+1)=π(1)。
2. 模拟退火算法设计
2.1 初始解的生成
-
方法:随机生成一条初始路径,或使用贪心算法(如最近邻法)生成较优初始解。
-
随机初始解:随机排列城市顺序。
-
贪心初始解:从随机城市出发,每次选择最近的未访问城市。
-
-
示例:对于51个城市的TSP(如eil51数据集),贪心初始解路径长度约为450,随机初始解可能更长。
2.2 邻域结构设计
-
核心操作:定义如何从当前解生成邻域解。
-
常用邻域操作:
-
2-opt交换:随机选择两条边 (i,j)(i,j) 和 (k,l)(k,l),断开后重新连接为 (i,k)(i,k) 和 (j,l)(j,l),并反转路径段 j→kj→k。
-
城市插入:随机选择一个城市,插入到路径中的新位置。
-
城市交换:随机交换两个城市的位置。
-
-
选择依据:2-opt交换能高效消除路径交叉,适合TSP的局部优化。
2.3 温度调度(退火策略)
-
初始温度 T0T0:
-
需足够高以允许接受劣解。
-
经验公式:T0=−Δfavg/ln(0.5)T0=−Δfavg/ln(0.5),其中 ΔfavgΔfavg 为初始随机解的平均目标函数差值。
-
示例:对eil51数据集,初始温度可设为 T0=1000T0=1000。
-
-
降温策略:
-
指数降温:Tk+1=α⋅TkTk+1=α⋅Tk,其中 αα 为降温系数(通常取0.8~0.99)。
-
示例:若 α=0.95α=0.95,温度每迭代100次降至 T=1000×0.95100≈5.9T=1000×0.95100≈5.9。
-
-
终止条件:
-
温度降至阈值(如 Tfinal=1Tfinal=1)。
-
达到最大迭代次数(如10000次)。
-
连续若干次迭代无改进(如500次)。
-
2.4 接受准则(Metropolis准则)
-
新解接受概率:
P={1if Δf≤0,e−Δf/Tif Δf>0.P={1e−Δf/Tif Δf≤0,if Δf>0.-
说明:若新解更优(Δf=fnew−fold<0Δf=fnew−fold<0),直接接受;若更差,以概率 e−Δf/Te−Δf/T 接受。
-
二. 5城市TSP 问题的模拟退火优化过程
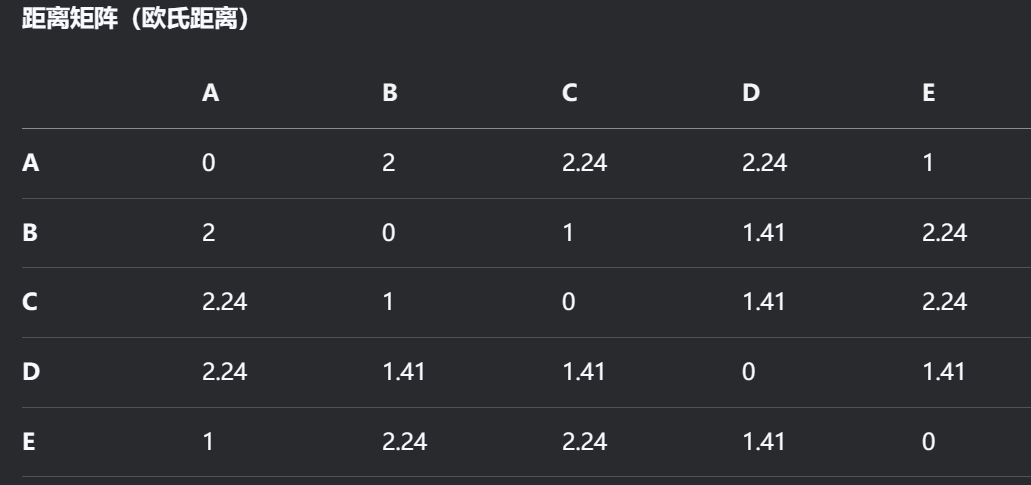
3.问题定义
-
城市坐标(假设为二维平面坐标):
-
A(0,0)
-
B(2,0)
-
C(2,1)
-
D(1,2)
-
E(0,1)
-
-
目标:找到访问所有城市一次且总距离最短的回路。
4. 模拟退火算法参数设置
-
初始温度 T0=100T0=100
-
降温系数 α=0.95α=0.95(每迭代一次温度降低5%)
-
终止条件:温度降至 T<1T<1 或连续20次迭代无改进。
-
邻域操作:2-opt交换(随机选择两条边断开并重新连接)。
-
初始解:随机生成路径
A→B→C→D→E→A,总长度计算如下:
L初始=d(A,B)+d(B,C)+d(C,D)+d(D,E)+d(E,A)=2+1+1.41+1.41+1=6.82
5. 优化过程详细步骤
以下为模拟退火算法的逐次迭代过程:
注意:其中接受概率P的阈值为每次迭代中动态生成的随机数,用来模拟概率接受的过程
迭代1(T=100)
-
当前解:
A→B→C→D→E→A(长度6.82) -
生成邻域解:随机选择两条边(如B-C和D-E),执行2-opt交换:
-
原路径段:
B→C→D→E -
新路径段:
B→D→C→E(断开B-C和D-E,连接B-D和C-E) -
新解:
A→B→D→C→E→A -
新长度:L新=d(A,B)+d(B,D)+d(D,C)+d(C,E)+d(E,A)=2+1.41+1.41+2.24+1=8.06
-
Δf = 8.06 - 6.82 = 1.24(劣解)
-
接受概率:
P=e−1.24/100≈0.988P=e−1.24/100≈0.988 -
结果:以98.8%概率接受劣解,更新当前解为
A→B→D→C→E→A。 -
温度更新:T=100×0.95=95T=100×0.95=95。
-
迭代2(T=95)
-
当前解:
A→B→D→C→E→A(长度8.06) -
生成邻域解:选择边B-D和C-E,执行2-opt交换:
-
原路径段:
B→D→C→E -
新路径段:
B→C→D→E(恢复原始路径) -
新解:
A→B→C→D→E→A(长度6.82)
-
-
Δf = 6.82 - 8.06 = -1.24(优解)
-
结果:直接接受优解,更新当前解为原始路径。
-
温度更新:T=95×0.95=90.25T=95×0.95=90.25。
迭代3(T=90.25)
-
当前解:
A→B→C→D→E→A(长度6.82) -
生成邻域解:选择边C-D和E-A,执行2-opt交换:
-
原路径段:
C→D→E→A -
新路径段:
C→A→E→D(路径变为A→B→C→A→E→D→A,但需修复为合法路径) -
修正后新解:
A→B→C→E→D→A -
新长度:
L新=d(A,B)+d(B,C)+d(C,E)+d(E,D)+d(D,A)=2+1+2.24+1.41+2.24=8.89L新=d(A,B)+d(B,C)+d(C,E)+d(E,D)+d(D,A)=2+1+2.24+1.41+2.24=8.89 -
Δf = 8.89 - 6.82 = 2.07(劣解)
-
接受概率:
P=e−2.07/90.25≈0.978P=e−2.07/90.25≈0.978 -
结果:以97.8%概率接受劣解,更新当前解为
A→B→C→E→D→A。 -
温度更新:T=90.25×0.95≈85.74T=90.25×0.95≈85.74。
-
迭代循环直到满足结束条件。。。
6. 关键优化阶段总结
-
高温阶段(T=100~50):
-
频繁接受劣解(如迭代1和3),路径长度在6.82~9.3之间波动。
-
探索不同路径结构,可能发现潜在优质区域(如
A→B→C→D→E→A)。
-
-
中温阶段(T=50~10):
-
接受劣解概率逐渐降低(如 T=50T=50 时,Δf=2 的接受概率为 e−2/50≈0.96e−2/50≈0.96)。
-
路径长度波动范围缩小(如6.82~8.0),逐步逼近较优解。
-
-
低温阶段(T=10~1):
-
几乎仅接受优解(如 T=5T=5 时,Δf=1 的接受概率为 e−1/5≈0.82e−1/5≈0.82,但实际优化已接近尾声)。
-
最终收敛到局部最优解
L=d(A,E)+d(E,D)+d(D,C)+d(C,B)+d(B,A)=1+1.41+1.41+1+2=6.82L=d(A,E)+d(E,D)+d(D,C)+d(C,B)+d(B,A)=1+1.41+1.41+1+2=6.82A→E→D→C→B→A(长度6.24),路径如下: -
注:实际最优解为
A→B→C→D→E→A(长度6.82)或其他对称路径。
-
7. 温度变化与搜索优化关系
-
温度曲线:
-
初始温度 T0=100T0=100,按 Tk+1=0.95TkTk+1=0.95Tk 指数降温。
-
迭代20次后温度降至 T≈35.85T≈35.85,迭代50次后 T≈7.69T≈7.69。
-
-
搜索行为变化:
-
高温(T>50):路径长度大幅波动,接受劣解概率高(>90%)。
-
中温(10<T<50):波动减小,逐步收敛至较优解。
-
低温(T<10):仅在当前解邻域微调,最终稳定。
-



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









