








曾梦想执剑走天涯,我是程序猿【AK】
简述概要
了解无监督学习之层次聚类
知识图谱
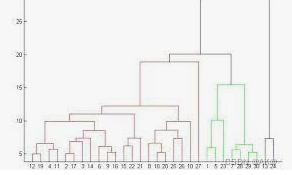
层次聚类(Hierarchical Clustering)是一种无监督学习算法,它通过构建一个层次结构来组织数据点,从而将数据点分组成不同的簇。层次聚类的结果通常以树状图(树状图)的形式表示,这种图展示了数据点之间的层次关系。
层次聚类的主要类型:
-
凝聚型(Agglomerative):
- 从每个数据点作为一个单独的簇开始,逐步合并最接近的簇对,直到所有数据点都在一个簇中或者达到预设的簇数量。
- 常用的凝聚方法包括最近邻(Single Linkage)、完全连接(Complete Linkage)、平均连接(Average Linkage)和Ward方法。
-
分裂型(Divisive):
- 从所有数据点在一个簇开始,逐步分裂簇,直到每个数据点都是一个单独的簇或者达到预设的簇数量。
- 这种方法不如凝聚型常见,且计算复杂度较高。
主要解决的问题:
- 数据结构发现:层次聚类能够揭示数据的内在层次结构,有助于理解数据的组织方式。
- 簇数量的灵活性:与K-Means等需要预先设定簇数量的算法不同,层次聚类不需要预先指定簇的数量,可以通过分析树状图来确定合适的簇数。
- 任意形状的簇:层次聚类能够发现任意形状的簇,不受簇形状的限制。
应用场景:
- 生物信息学:在基因表达数据分析中,层次聚类用于发现具有相似表达模式的基因或蛋白质。
- 社交网络分析:分析社交网络中的用户关系,发现社区结构或社交圈子。
- 文本挖掘:对文档集合进行层次聚类,以便发现文档的层次化主题结构。
- 市场细分:在商业分析中,层次聚类可以帮助识别不同层次的消费者群体。
- 图像分割:在图像处理中,层次聚类可以用于图像分割,识别图像中的不同区域。
- 组织结构分析:在组织管理中,层次聚类可以帮助分析组织结构,如员工关系、部门结构等。
层次聚类的优点在于它能够提供数据的层次结构视图,并且不需要预先设定簇的数量。然而,它也有一些局限性,如计算复杂度较高,尤其是对于大型数据集,且一旦合并或分裂操作完成,就无法逆转,这可能导致错误的聚类结果。此外,层次聚类对于噪声和异常值也比较敏感。在实际应用中,可能需要结合其他方法来优化聚类结果。在Java中,可以使用如Weka等库来实现层次聚类。
推荐链接:
层次聚类算法原理总结(阿里云天池)
利用 k 阶空间邻近图的空间层次聚类方法(武 汉 大 学 学 报 信 息 科 学 版)
---- 永不磨灭的番号:我是AK
















 452
452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











