









idea本地运行spark程序时出现winutils.exe报错
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)
at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300)
at org.apache.hadoop.util.Shell.<clinit>(Shell.java:293)
at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.setInputPaths(FileInputFormat.java:447)
at org.apache.spark.sql.execution.datasources.json.JsonFileFormat.createBaseRdd(JsonFileFormat.scala:131)
at org.apache.spark.sql.execution.datasources.json.JsonFileFormat.inferSchema(JsonFileFormat.scala:64)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$7.apply(DataSource.scala:184)
at org.apache.spark.sql.execution.datasources.DataSource$$anonfun$7.apply(DataSource.scala:184)
at scala.Option.orElse(Option.scala:289)
at org.apache.spark.sql.execution.datasources.DataSource.org$apache$spark$sql$execution$datasources$DataSource$$getOrInferFileFormatSchema(DataSource.scala:183)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:387)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:152)
at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:298)
at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:251)
原因:缺少winutils.exe程序。Hadoop都是运行在Linux系统下的,如果再Windows下运行需要安装一个插件
解决方案
下载 https://github.com/srccodes/hadoop-common-2.2.0-bin 到本地并解压
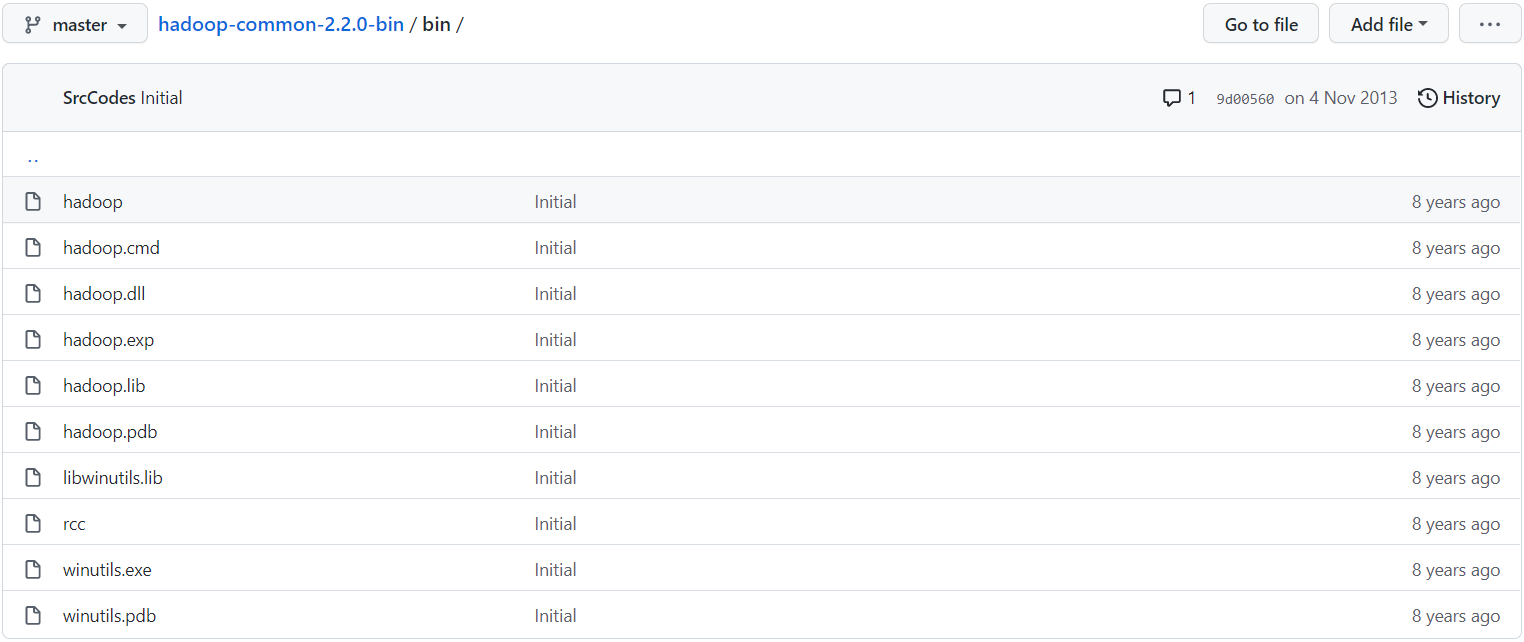
我这里将下载下来的压缩文件解压到了本地的hadoop目录(将文件解压重命名为hadoop也可)
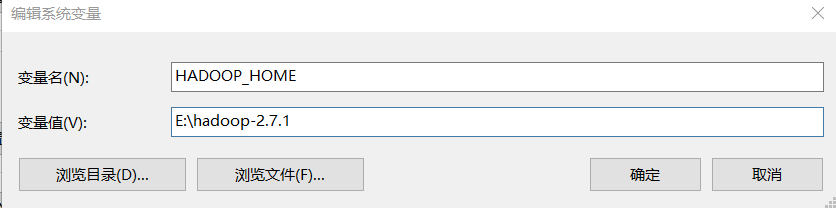
配置环境变量
添加HADOOP_HOME
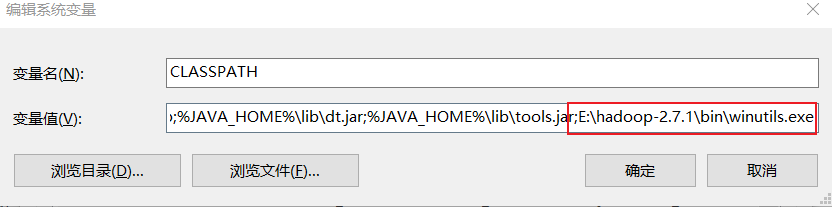
配置CLASSPATH
将;E:\hadoop-2.7.1\bin\winutils.exe添加到最后
修改Path
将%HADOOP_HOME%\bin 添加到Path中

最后重启电脑,再次执行报错即可消除。
















 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











