







在人工智能的星空中,大型语言模型就像一艘满载知识的飞船,人们长期以来相信“越多数据,越好”——预训练过程中投入的每一点标记(token)都能转化为更好的基础性能,最终在微调(后训练)中表现得更为卓越。然而,最新研究却揭示了一个耐人寻味的悖论:扩展预训练规模不仅不能确保下游任务能力的提升,反而可能使得模型在微调阶段变得更加脆弱,最终呈现出性能下降的“灾难性过训练”现象。正如登山者在不断累积装备后,由于负重过大反而难以攀登陡峭山巅,这一现象引发了我们对预训练设计方法的深思与重新审视。
———————————————————————
🌍 大局观:预训练与下游适应性的矛盾
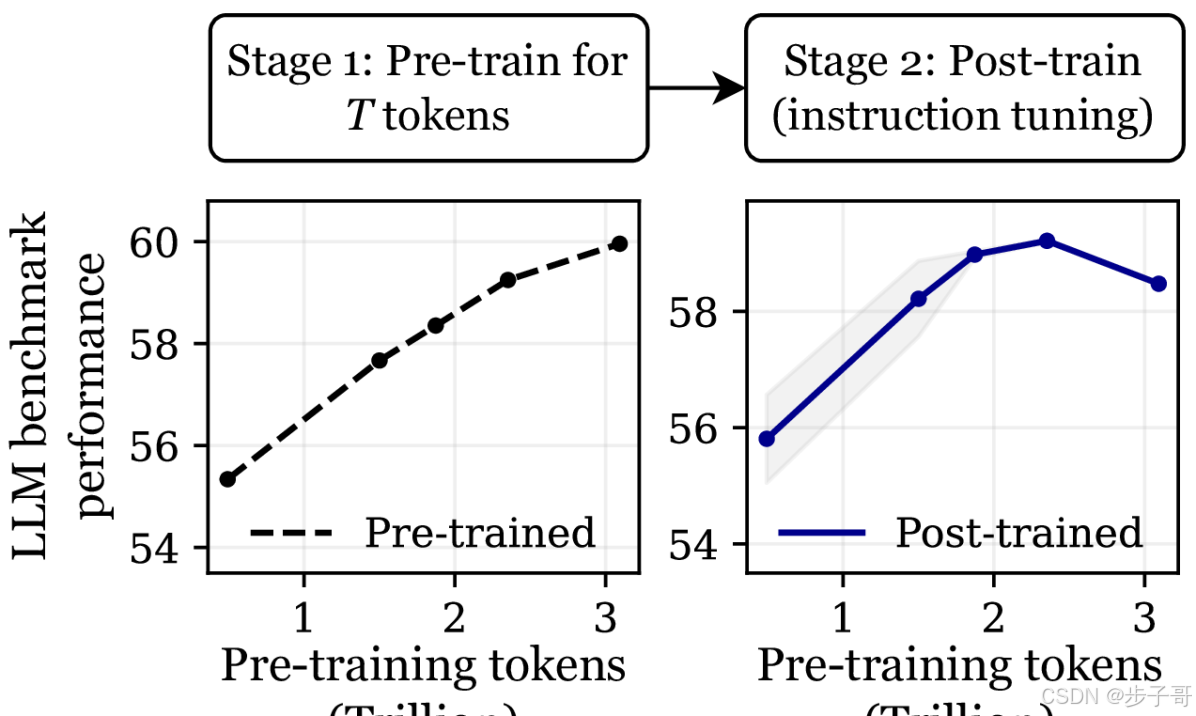
传统观点认为,大规模预训练能使模型在语言理解、知识提取和推理等方面得以提升。正如图 1 所示,随着预训练 token 数量不断增加,模型在原始任务上的表现持续改进,困惑度(perplexity)越来越低。但是,实际实验却发现,当我们用这些基础模型进行指令微调或多模态微调后,情况却并非一帆风顺。举例来说,预训练了 3T token 的 OLMo-1B 模型在多个标准基准测试上(如 AlpacaEval、ARC 等)的微调后表现竟比仅预训练 2.3T token 的对应模型低超过 2%!这正是“灾难性过训练”的真实写照。
研究者们将这个现象归结为两个核心原因:
① 随着预训练过程延长,模型不断累积新特征,然而与此同时,预训练参数对修改(例如微调更新或噪声扰动)的敏感性不断增强。
② 当这种所谓“渐进敏感性”(progressive sensitivity)的幅度超过了预训练获得改进的收益时,下游任务的性能便会反转性下降,从而形成了一个“拐点”:扩展预训练数据超出该拐点后,微调后模型表现会急剧恶化。
———————————————————————
🔍 实验的探照灯:从现实到受控的细致观察
🚦 实验观察:现实世界的“灾难性过训练”
在实际环境中,研究者们对多种模型(例如 OLMo-1B、OLMo-2-7B 以及 LLM360-Amber-7B)进行了详细的实验。通过在 Anthropic-HH、TULU 等指令数据集上进行微调,以及在 LLaVA 框架下进行多模态微调,他们发现:
-
指令微调中的悖论
在 Anthropic-HH 数据集上,对 OLMo-1B 模型进行指令微调后,预训练 token 预算超过 2.5T 时,无论是在 ID 任务(例如 AlpacaEval 上的响应率)还是在 OOD 基准(ARC-Easy、ARC-Challenge、PIQA、HellaSwag 等)上,模型的表现均出现明显下降。实际上,基于 3T token 的模型表现不仅比 2.3T 模型低,甚至其最终性能下降至与仅用 1.5T token 预训练的模型相当。 -
多模态微调中的例外
在多模态设置中,扩展预训练仍然带来了 VLM 分数上较为连续的提升,但在某些 OOD 任务中(例如 PIQA),扩展预训练同样导致了明显的性能遗忘和下降——这意味着模型在学习视觉信息时,其下游通用能力并未同步受益。
这些实验数据表明,虽然在预训练阶段引入更多数据可以让基础模型不断进步,但其带来的“隐性成本”便是对后续微调过程中参数更新的过度敏感性,从而使得模型最终效果受到损害。
🎲 预热试验:高斯噪声的启示
为了更直观理解这一现象的内在机理,研究者设计了另一组实验,使用高斯噪声来模拟参数变动或“微调”过程。具体步骤如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











