






ViLLa(Video Reasoning Segmentation with Large Language Model)焦于视频理解中的一个新颖而具有挑战性的任务——视频推理分割。传统视频感知模型往往受限于对显式文本描述或预定义类别的依赖,缺乏理解用户隐含意图的能力,尤其是在处理复杂物体运动的视频场景中。为此,论文提出了视频推理分割任务,旨在根据复杂的文本查询输出视频中目标实例的分割掩码序列。不同于常规的参照视频对象分割,该任务要求模型能够处理复杂的实例描述,涉及深层次的推理和世界知识,以及物体运动信息的捕捉。为推动这一领域的研究进展,作者们构建了一个视频推理分割基准,并开发了ViLLa模型,该模型融合了大型语言模型的语言生成能力,同时具备检测、分割和跟踪视频中多个实例的能力。通过引入时间感知上下文聚合模块和视频帧解码器,ViLLa成功地建立了文本与视觉信息间的关联,展示了其在复杂推理和参照视频分割上的卓越性能,以及在不同时间理解指标上的优秀表现。

1 模型设计
ViLLa模型通过融合预训练视觉编码器、文本编码器、大语言模型以及创新的上下文注意力模块和视频帧交互解码器,实现了从视频内容到文本描述的有效转换,其中视觉编码器捕捉视频帧特征,文本编码器理解用户指令,而上下文注意力模块则精确定位并聚合关键视觉信息,最终由视频帧交互解码器综合生成连贯的描述。
(1)视觉编码器和文本编码器的集成
视觉编码器从输入帧𝑉𝑡中抽取多尺度特征:
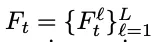
,其中𝐿表示选择的层数。
文本编码器接收用户指令和视觉嵌入:
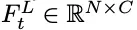
,其中𝑁=𝐻/𝑝×𝑊/𝑝表示帧补丁数量,𝐶表示嵌入通道数,输出文本嵌入
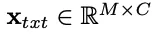
,其中𝑀是查询的数量。使用QFormer作为文本编码器以保持跨模态对齐和交互。
(2)大语言模型的使用
大型语言模型接收带有视觉特征的文本嵌入,通过视觉到语言的投影层𝑃𝑟𝑜𝑗𝑉→𝐿对视觉信息进行编码,使其与语言空间对齐。
(3)上下文注意力模块
上下文注意力模块(Context agrregation Module,CAM)模块的目标是聚集与文本相关的视觉特征,并将其注入生成的文本嵌入中,以表示当前帧。使用公式
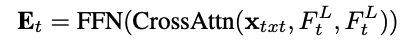
来实现这一目标,其中𝐶𝑟𝑜𝑠𝑠𝐴𝑡𝑡𝑛是交叉注意力机制,𝐹𝐹𝑁是前馈神经网络。
(4)视频帧交互解码器
视频帧交互解码器利用视频尺度的分割token与帧级token交互,生成最终精炼的完整分割token,这些token同时包含视频级和帧级信息。这一步骤对于生成预测掩码至关重要,它结合了多尺度视频特征。
2 结语
ViLLa是一种结合大语言模型能力的视频推理分割方法,旨在根据复杂的文本指令对视频中的动态对象进行理解、推理和像素级分割,同时提出了一项新任务和评估基准以推动该领域的发展。
论文题目:ViLLa: Video Reasoning Segmentation with Large Language Model
论文链接:https://arxiv.org/abs/2407.14500
PS: 欢迎大家扫码关注公众号_,我们一起在AI的世界中探索前行,期待共同进步!

精彩回顾
1. 大语言模型稀疏水印技术















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









