






Elasticsearch提供了DSL ( Domain Specific Language)查询,就是以SON格式来定义查询条件
DSL查询可以分为两大类:
叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
复合查询(Compound query clauses)︰以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
在查询以后,还可以对查询的结果做处理,包括:
- 排序:按照1个或多个字段值做排序
- 分页:根据from和size做分页,类似MySQL
- 高亮:对搜索结果中的关键字添加特殊样式,使其更加醒目·聚合:对搜索结果做数据统计以形成报表
快速入门

叶子查询
叶子查询还可以进一步细分,常见的有:
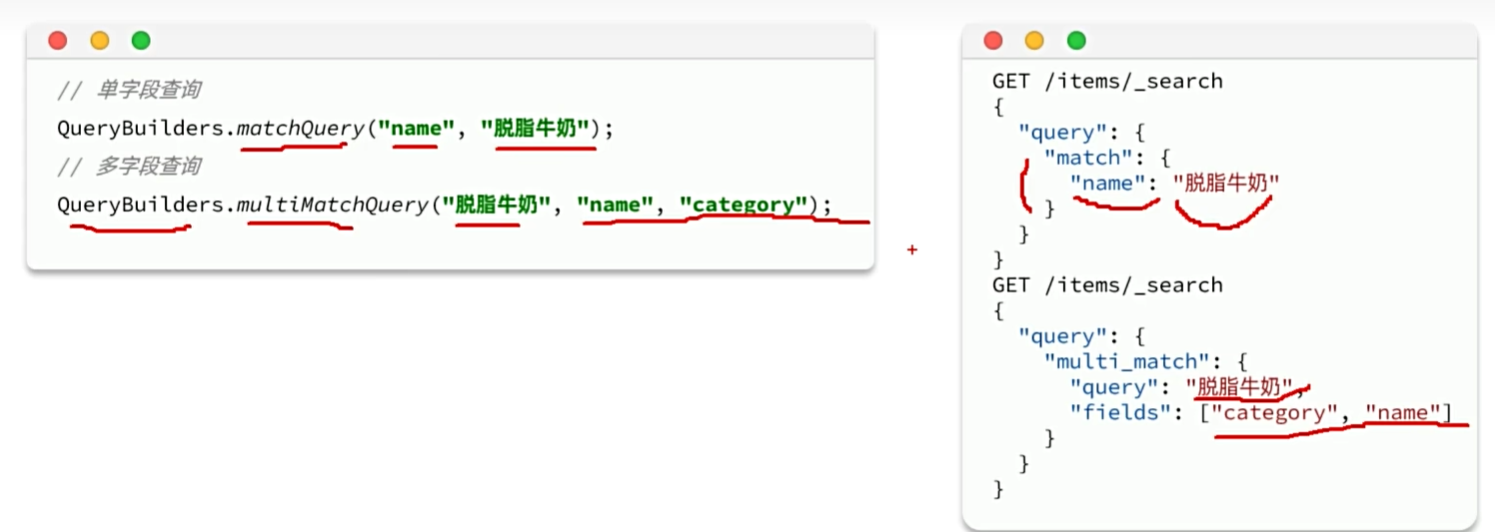
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去词条列表中匹配。例如:
- match_query
- multi_match_query
精确查询:不对用户输入内容分词,直接精确匹配,一般是查找keyword、数值、日期、布尔等类型。例如:
- ids
- range
- term
地理(geo)查询:用于搜索地理位置,搜索方式很多。例如:
- geo_distance
- geo_bounding_box
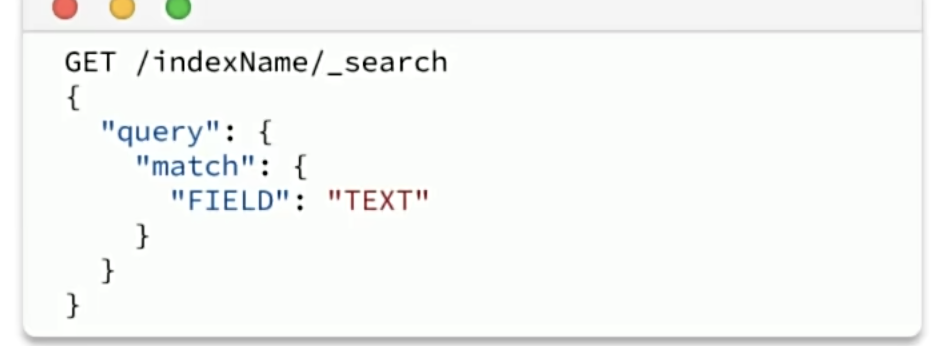
match查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索,语法:
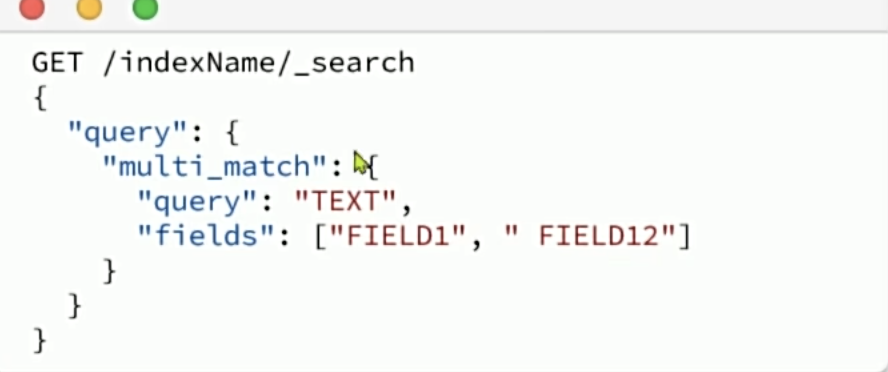
multi_match: 与match查询类似,只不过允许同时查询多个字段,语法:
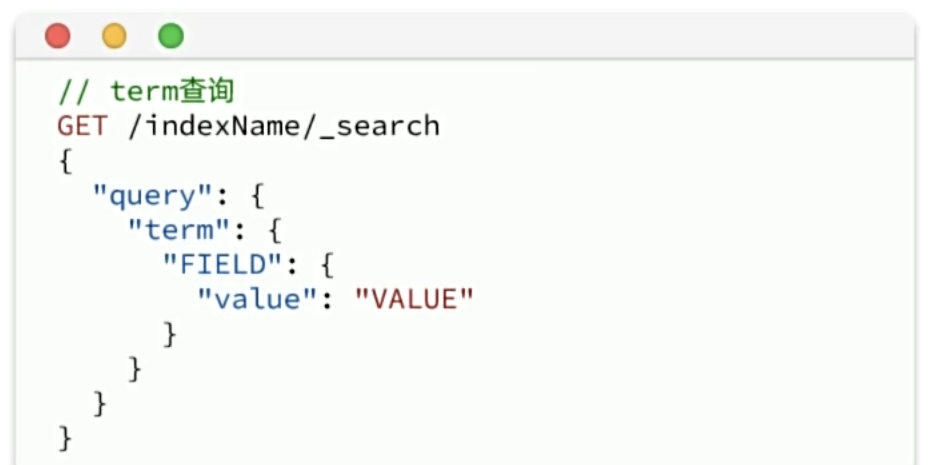
精确查询
精确查询,英文是Term-level query,顾名思义,词条级别的查询。也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配。
因此推荐查找keyword、数值、日期、boolean类型的字段。例如id、price、城市、地名、人名等作为一个整体才有含义的字段。
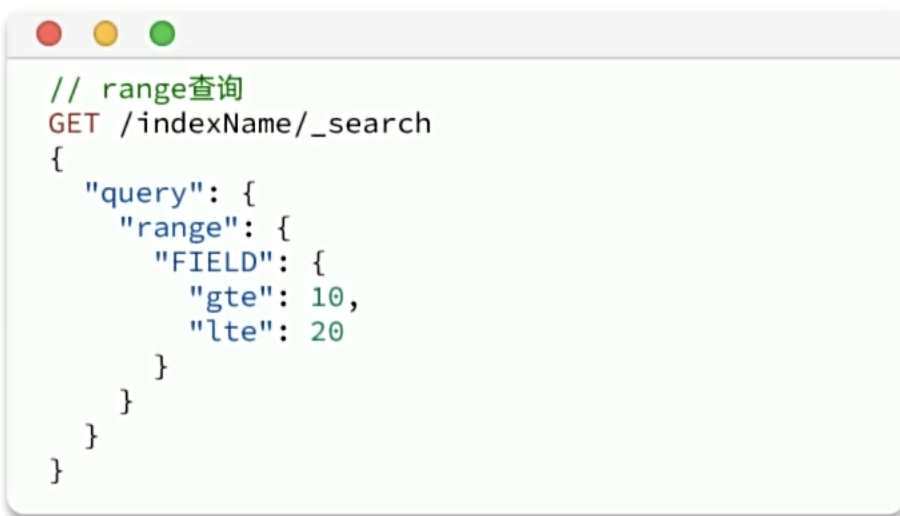
复合查询
复合查询大致可以分为两类:
第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
- bool
第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
- function_score
- dis_max
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
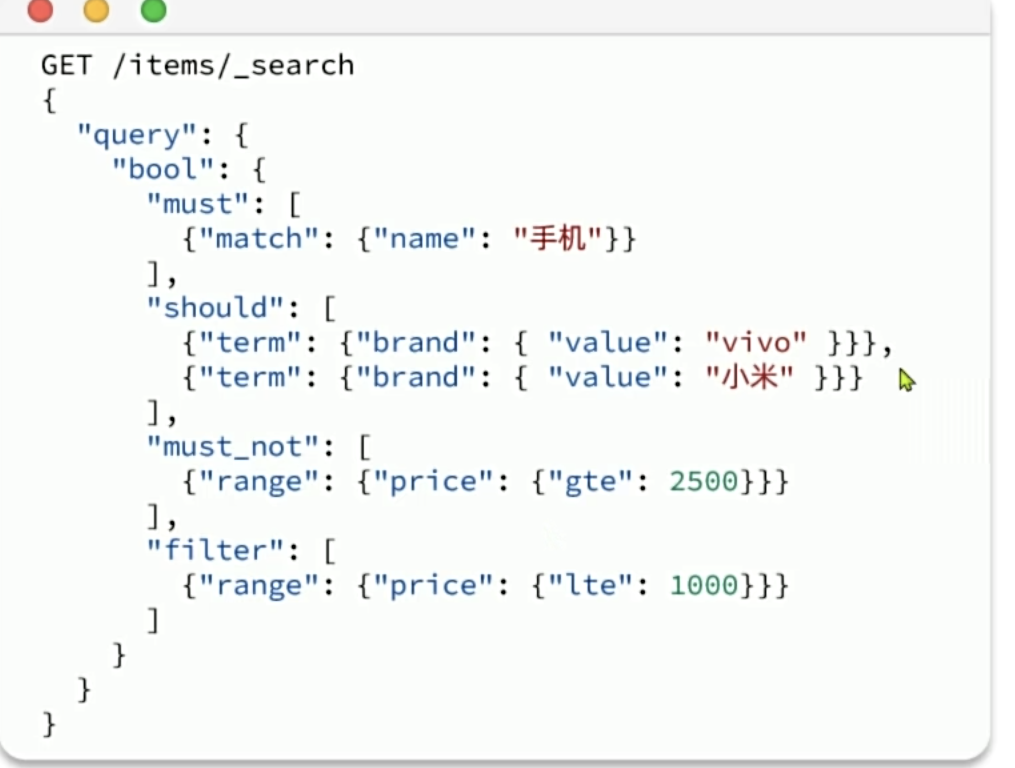
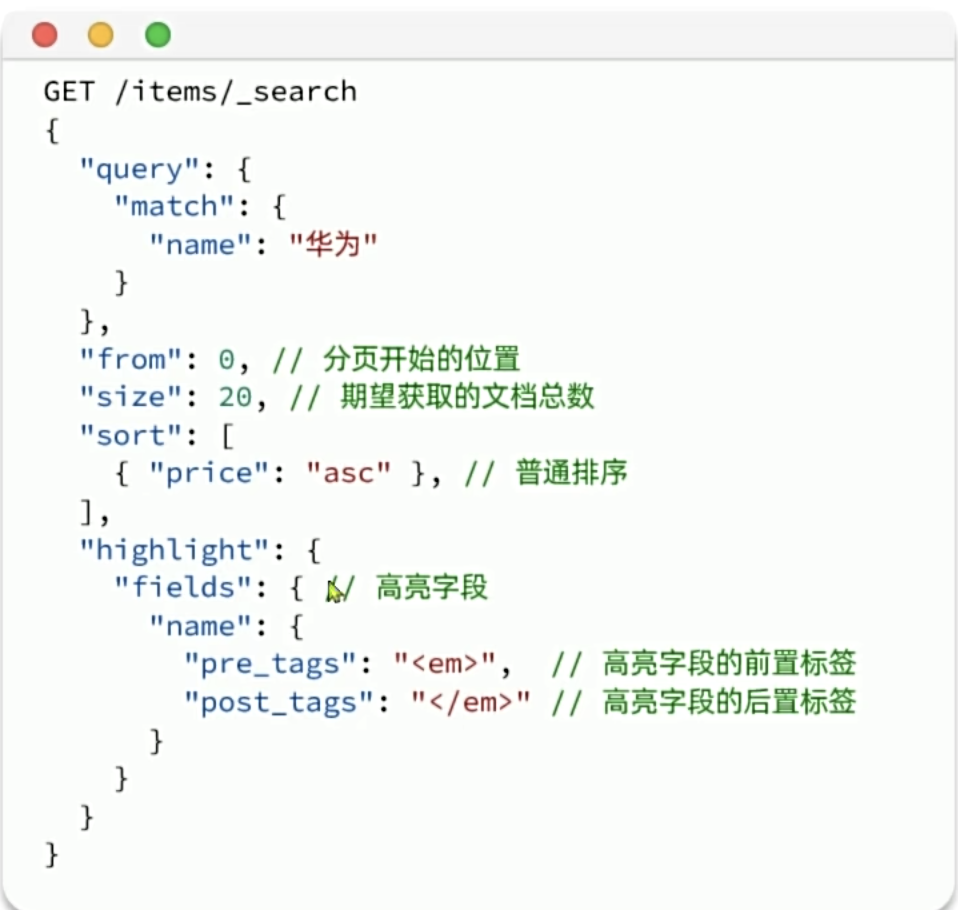
排序和分页
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序,也可以指定字段排序。可以排序字段类型有: keyword类型、数值类型、地理坐标类型、日期类型等。
排序
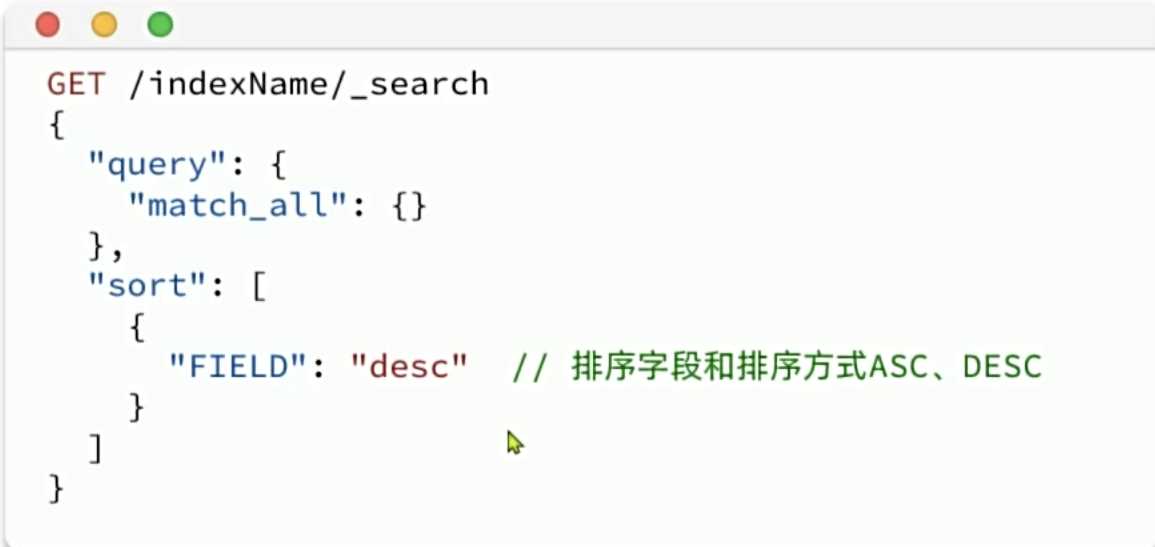
分页
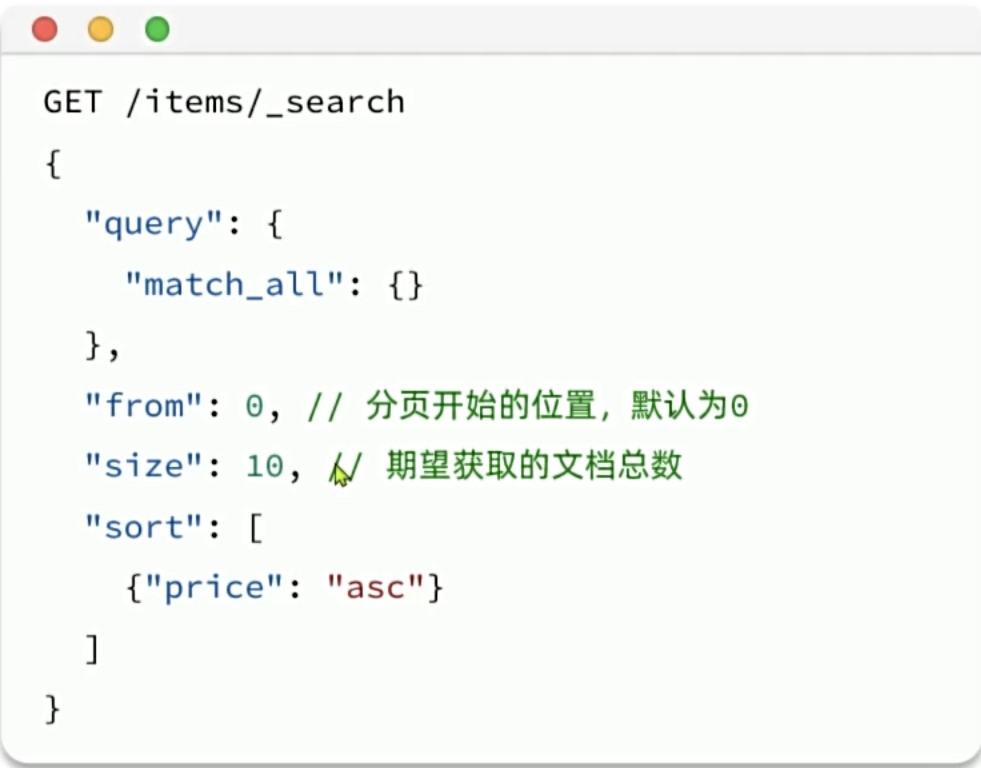
elasticsearch默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
- from:从第几个文档开始
- size:总共查询几个文档
深度分页问题
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。查询数据时需要汇总各个分片的数据。
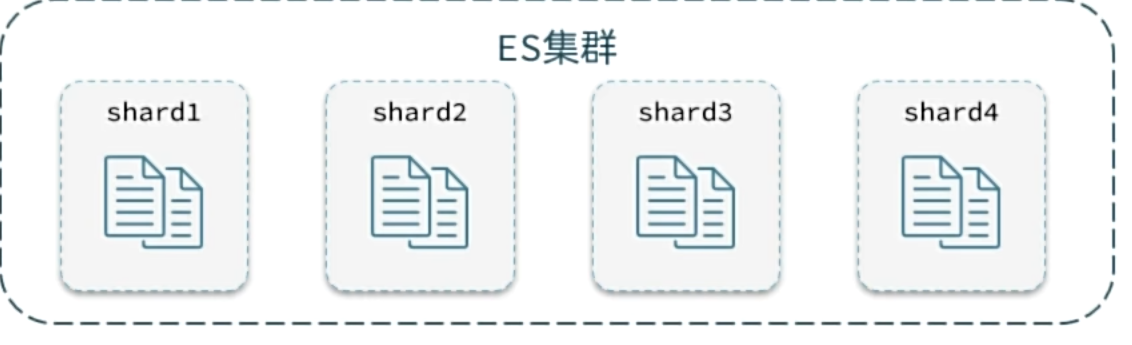
假如我们要查询第100页数据,每页查询10条:
那么实现的思路:首先对数据进行排序,然后再去找出990~1000名的数据
在底层是把每一片里的前1000个数据选出来,然后聚合重新排序选取前1000个,当我们的数据非常多并且页数非常靠后时,就会导致效率非常差
解决办法:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的式。
scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
优点:没有查询上限,支持深度分页
缺点:只能向后逐页查询,不能随机翻页
场景:数据迁移,手机滚动查询
高亮显示
就是在搜索结果中把搜索关键字突出显示


搜索的完整语法
JavaRestClient查询
快速入门
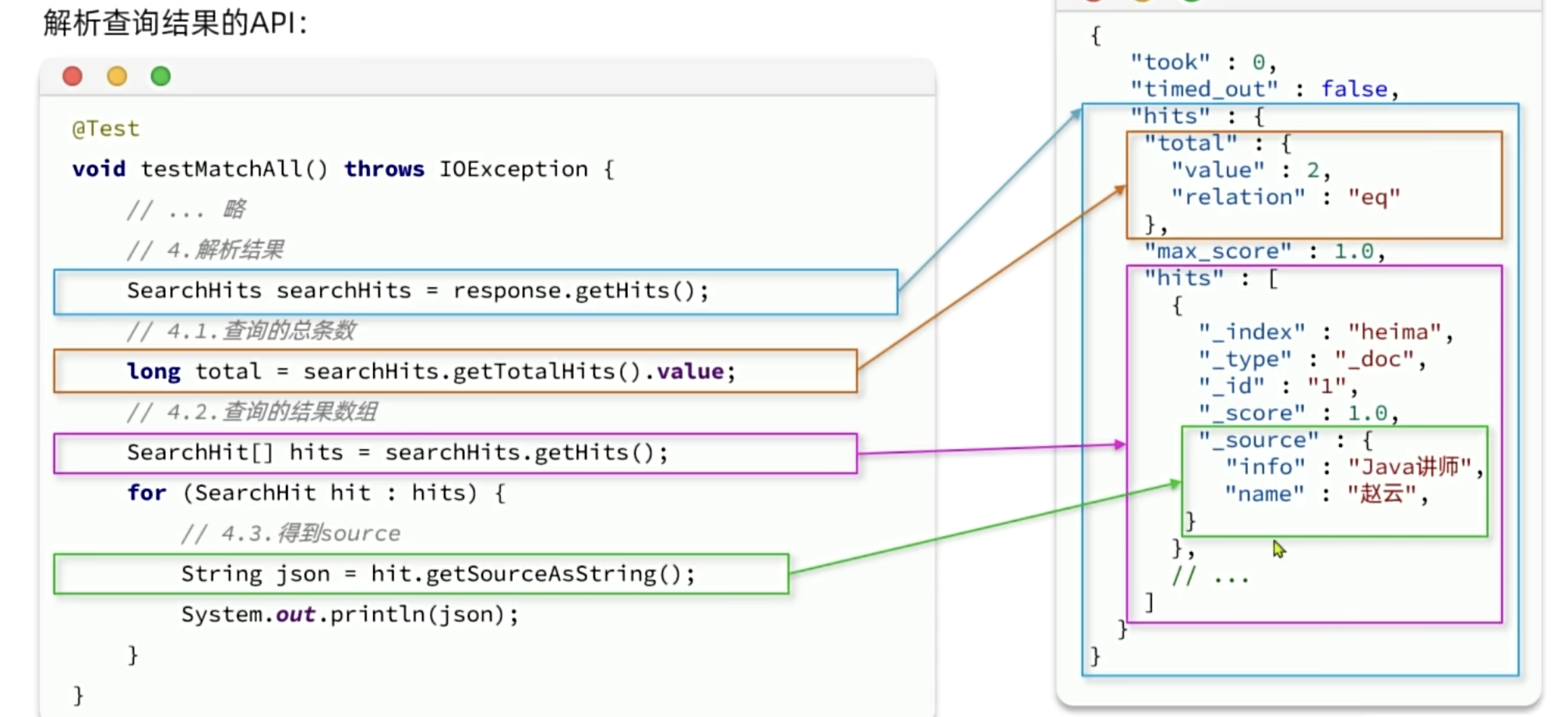
数据搜索的Java代码我们分为两部分:
- 构建并发起请求
- 解析查询结果
构建查询条件
在JavaRestAPI中,所有类型的query查询条件都是由QueryBuilders来构建的:


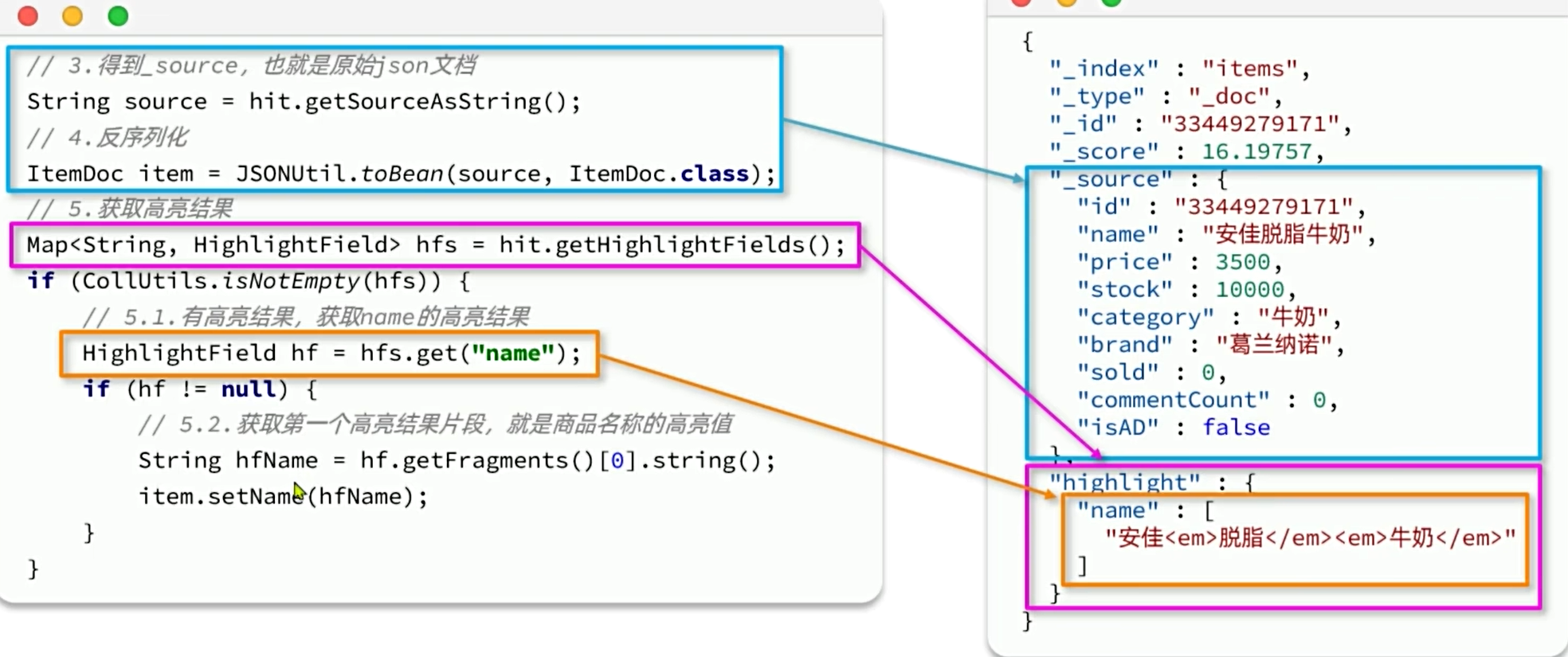
排序和分页

高亮显示

数据聚合
聚合(aggregations)可以实现对文档数据的统计、分析、运算。聚合常见的有三类:
桶( Bucket)聚合:用来对文档做分组
- TermAggregation:按照文档字段值分组
- Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
度量(Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等
- Avg:求平均值
- Max:求最大值
- Min:求最小值
- Stats:同时求max. min.ava、sum等
管道( pipeline)聚合:其它聚合的结果为基础做聚合
注意:参与聚合的字段必须是Keyword、数值、日期、布尔的类型的字段
DSL聚合
我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category值一样的放在同一组,属于Bucket聚合中的Term聚合。
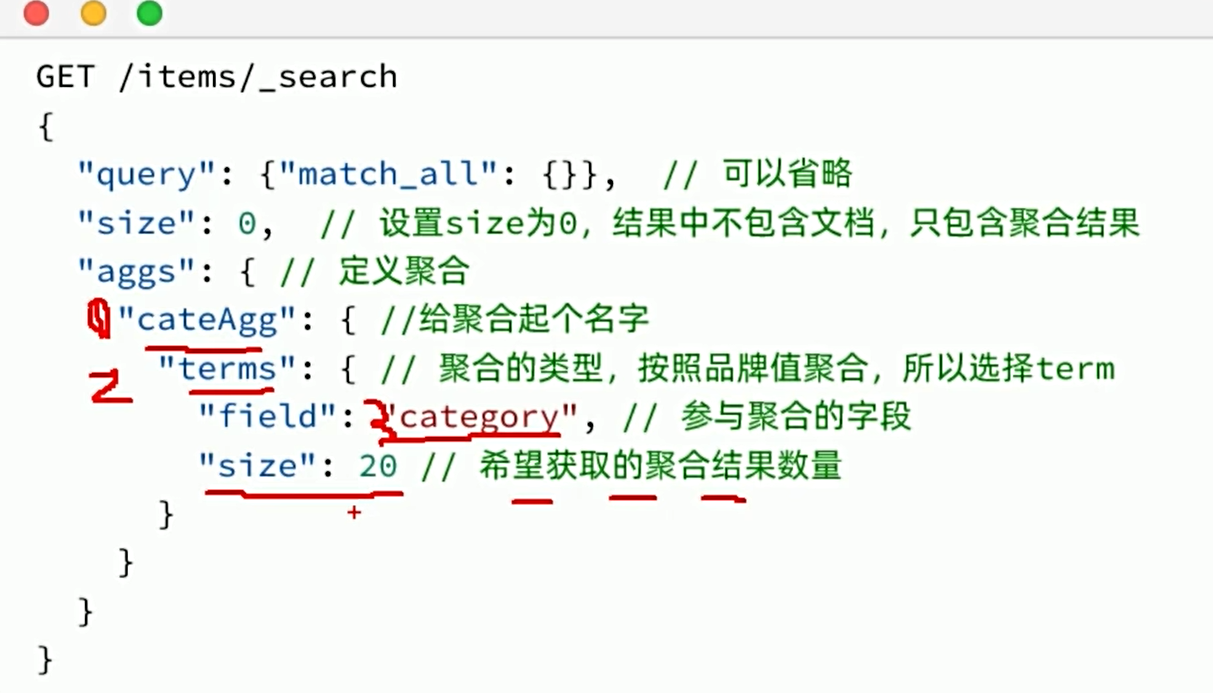
默认情况下,Bucket聚合是对索引库的所有文档做聚合,我们可以限定要聚合的文档范围,只要添加query条件即可。例如,我想知道价格高于3000元的手机品牌有哪些:
除了对数据分组(Bucket)以外,我们还可以对每个Bucket内的数据进一步做数据计算和统计。例如:我想知道手机有哪些品牌,每个品牌的价格最小值、最大值、平均值。
RestClient聚合
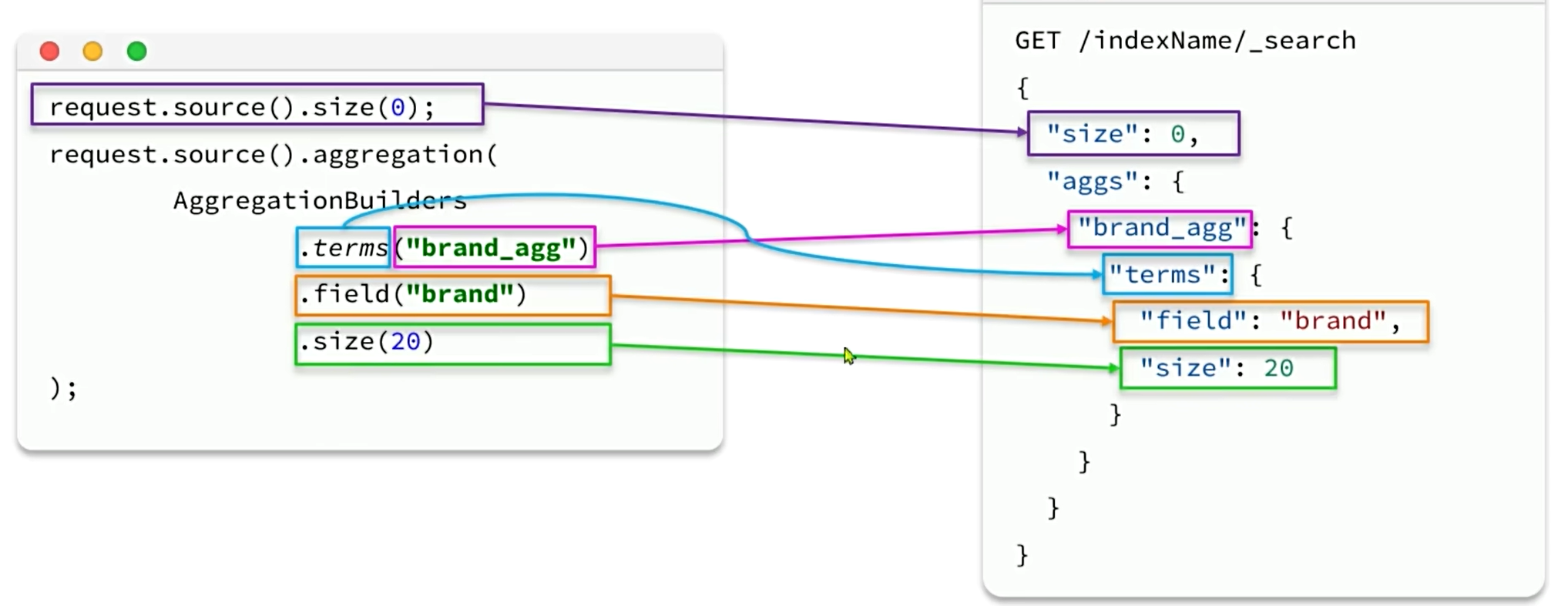
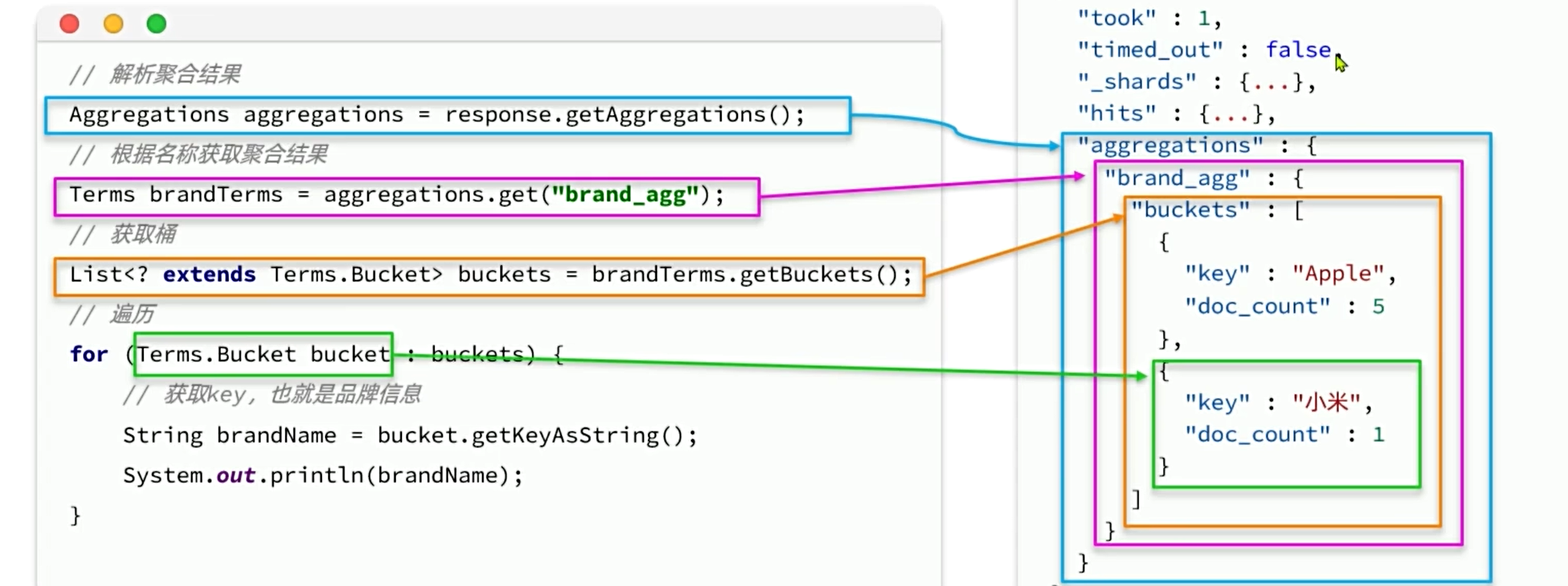















 1434
1434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









