






在 GitHub 上发现一篇教程,作者详细介绍了如何使用 Python 语言,从零开始构建一个文本到视频生成模型。
涵盖了从理解理论概念到架构编码,最终实现输入文本提示即可生成视频的全过程。
相关链接
GitHub:github.com/FareedKhan-dev/AI-text-to-video-model-from-scratch
内容介绍

OpenAI 的 Sora、Stability AI 的 Stable Video Diffusion 以及许多其他已经问世或未来将出现的文本转视频模型,是继大型语言模型 (LLM) 之后 2024 年最流行的 AI 趋势之一。在本博客中,我们将从头开始构建一个小规模的文本转视频模型。我们将输入一个文本提示,我们训练过的模型将根据该提示生成视频。本博客将涵盖从理解理论概念到编码整个架构并生成最终结果的所有内容。
由于我没有高端的 GPU,因此我编写了小规模架构。以下是在不同处理器上训练模型所需时间的比较:
我们正在建设什么
我们将采用与传统机器学习或深度学习模型类似的方法,即在数据集上进行训练,然后在未见过的数据上进行测试。在文本转视频的背景下,假设我们有一个包含 10 万个狗捡球和猫追老鼠视频的训练数据集。我们将训练我们的模型来生成猫捡球或狗追老鼠的视频。
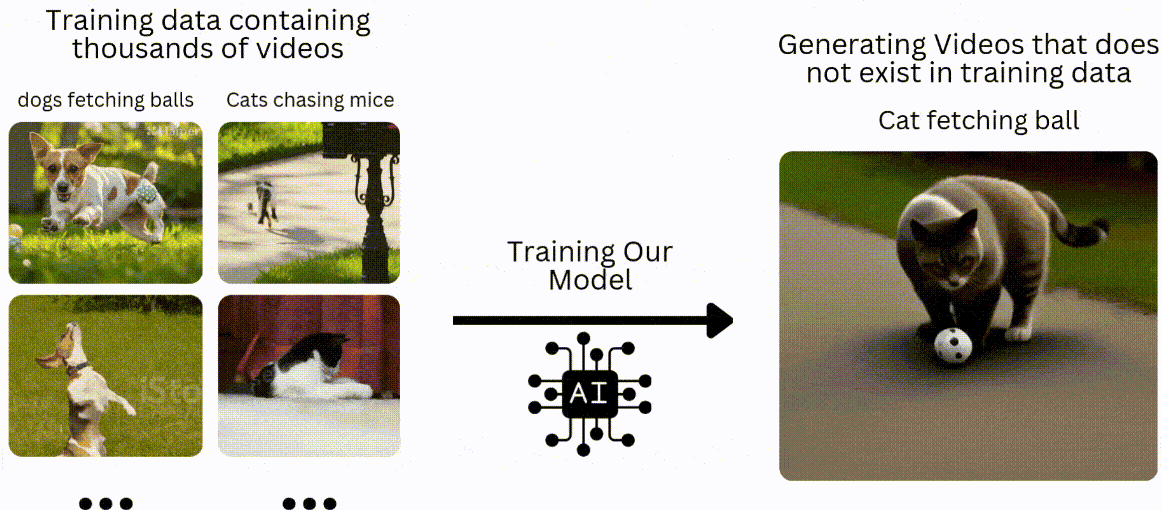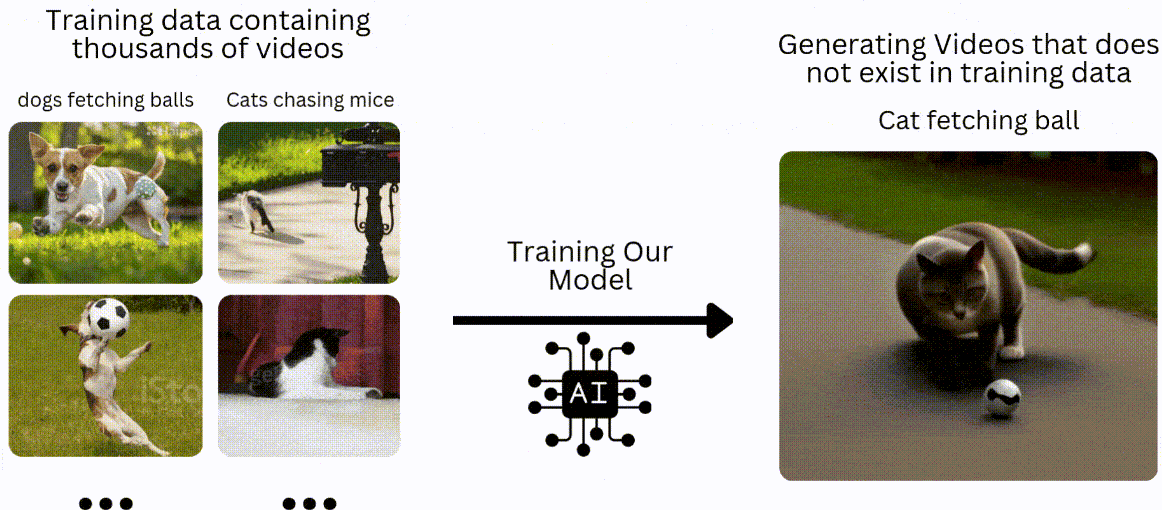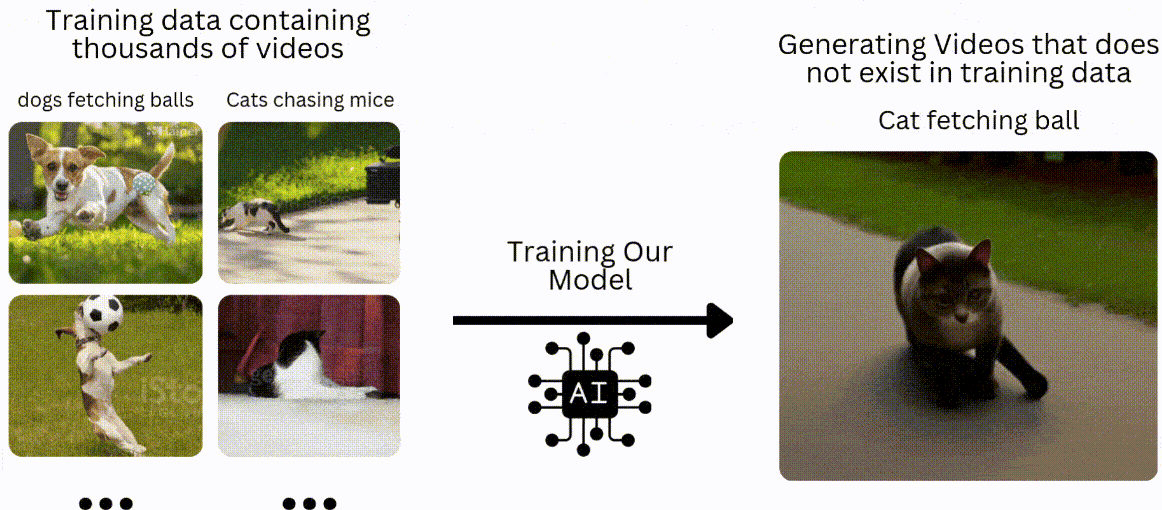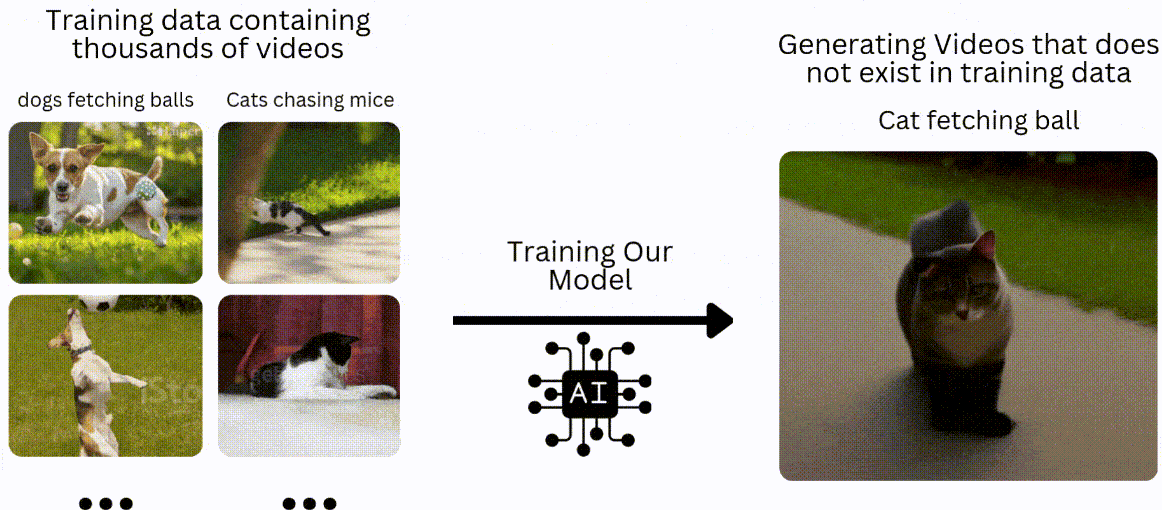
什么是 GAN?
生成对抗网络 (GAN) 是一种深度学习模型,其中两个神经网络相互竞争:一个根据给定的数据集创建新数据(如图像或音乐),另一个则尝试判断数据是真是假。此过程持续进行,直到生成的数据与原始数据无法区分。
实际应用
生成图像:GAN 根据文本提示创建逼真的图像或修改现有图像,例如增强分辨率或为黑白照片添加颜色。
- 数据增强:它们生成合成数据来训练其他机器学习模型,例如为欺诈检测系统创建欺诈交易数据。
- 补充缺失信息:GAN 可以填充缺失数据,例如从地形图生成用于能源应用的地下图像。
- 生成 3D 模型:将 2D 图像转换为 3D 模型,可用于医疗保健等领域,为手术规划创建逼真的器官图像。
GAN 如何工作?
它由两个深度神经网络组成:生成器和鉴别器。这两个网络在对抗设置中一起训练,其中一个网络生成新数据,另一个网络评估数据是真是假。
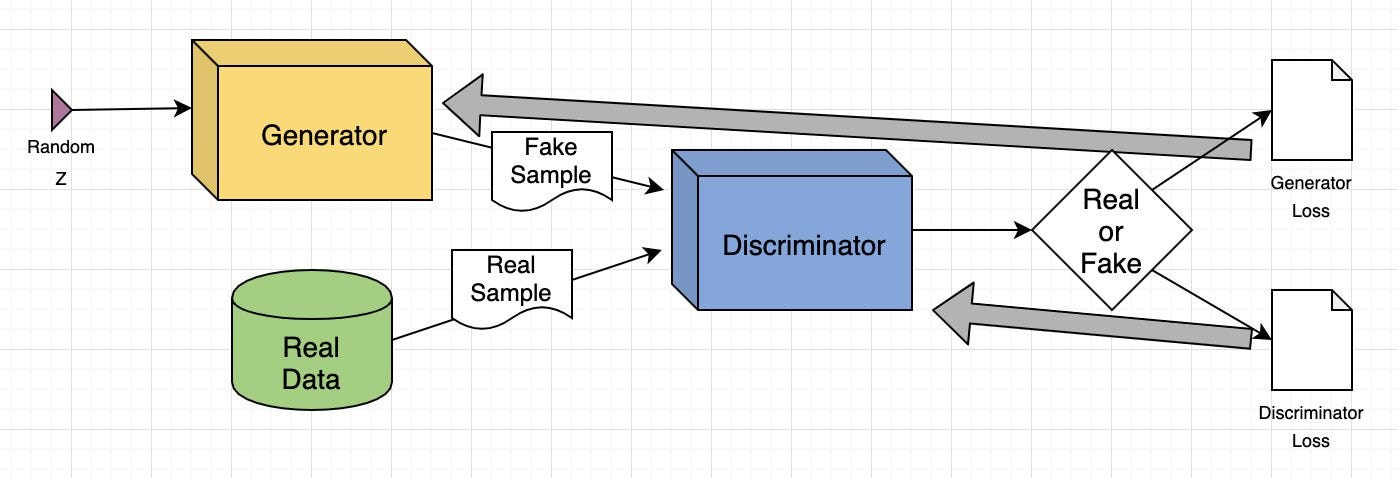
以下是 GAN 工作原理的简要概述:
- 训练集分析:生成器分析训练集以识别数据属性,而鉴别器则独立分析相同的数据以学习其属性。
- 数据修改:生成器向数据的某些属性添加噪声(随机变化)。
- 数据传递:修改后的数据被传递给鉴别器。
- 概率计算:鉴别器计算生成的数据来自原始数据集的概率。
- 反馈循环:鉴别器向生成器提供反馈,指导其在下一个周期减少随机噪声。
- 对抗性训练:生成器试图最大化鉴别器的错误,而鉴别器则试图最小化自己的错误。通过多次训练迭代,两个网络都会得到改进和发展。
- 平衡状态:训练持续进行,直到鉴别器无法再区分真实数据和合成数据,这表明生成器已成功学会生成真实数据。此时,训练过程已完成。
GAN 训练示例
让我们用图像到图像转换的例子来解释 GAN 模型,重点是修改人脸。
- 输入图像:输入是人脸的真实图像。
- 属性修改:生成器修改脸部的属性,例如在眼睛上添加太阳镜。
- 生成的图像:生成器创建一组添加了太阳镜的图像。
- 鉴别器的任务:鉴别器接收真实图像(戴太阳镜的人)和生成的图像(添加了太阳镜的脸部)的混合。
- 评估:鉴别器试图区分真实图像和生成的图像。
- 反馈循环:如果鉴别器正确识别了假图像,生成器就会调整其参数以生成更令人信服的图像。如果生成器成功欺骗了鉴别器,鉴别器就会更新其参数以改进其检测能力。
通过这种对抗过程,两个网络都在不断改进。生成器在创建逼真图像方面越来越好,而鉴别器在识别假图像方面也越来越好,直到达到平衡,鉴别器再也无法区分真实图像和生成的图像。此时,GAN 已成功学会生成逼真的修改。

















 1317
1317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









