







数字人播报
前言
文本转视频模型是一种基于人工智能技术的模型,它可以将给定的文字描述或提示转换成相应的视频内容。这些模型可以通过学习大量的文本和视频数据来理解语义和视觉关系,并生成与输入文本相符合的视频。
这类模型通常由两个主要组件组成:文本理解模块和视频生成模块。
文本理解模块:这个模块负责理解输入的文本或提示。它可以采用自然语言处理技术,将文本转换成计算机可以理解的表示形式。这个过程可能包括词嵌入、语法分析、语义理解等方法,以从文本中提取出关键信息。
视频生成模块:这个模块利用文本理解模块提取的信息,生成相应的视频内容。它使用计算机视觉技术和深度学习模型,根据输入文本绘制场景、选择角色、设置动作和动画效果等。生成的视频可以是2D或3D动画、虚拟现实场景、图像序列等形式。
文本转视频模型的训练需要大量的文本和视频数据,其中文本与视频之间有明确的对应关系。通过训练,模型学习到了如何将文本描述转化为与之对应的视频内容,使得模型在生成视频时能够根据文本提示产生准确、连贯且具有创造力的结果。
这种模型具有广泛的应用潜力,比如在电影制作、广告创意、教育培训等领域可以帮助人们快速生成视觉内容。然而,需要注意的是,由于版权和伦理等问题,使用文本转视频模型时需要遵守相关法律法规,并确保生成的内容符合道德准则。
提示:以下是本篇文章正文内容,下面案例可供参考
一、dqnapi是什么?
DQNAPI 是一个综合平台,旨在将程序、接口、数据和模型等资源集成到一个统一的环境中。我们为每个资源编写了一个独特的数字标识符,即 DQNAPI 号,用户可以通过这个号码快速查找并访问所需资源。
通过 DQNAPI,您可以方便地注册和管理您使用过的各种资源。无论是程序代码、API 接口、数据集还是模型,只要您注册了相应的 DQNAPI 号,您就可以轻松地回顾和再次使用这些资源。这种整合和统一的方式极大地简化了资源的查找和获取过程,为所有用户提供了更加便捷和高效的体验。
在 DQNAPI 官网,您可以浏览各类资源的详细介绍,并随时搜索和获取您需要的资源。我们不仅提供了齐全的资源库,还为用户提供了交流和分享的平台,让用户们能够互相学习和共享经验。
无论您是开发者、数据科学家还是研究人员,DQNAPI 都将是您不可或缺的伙伴。加入我们,让 DQNAPI 帮助您更好地整合和管理资源,让创新变得更加简单和高效!
dqnapi查询地址
本文使用的dqnapi 号:100.35395/2023.150_v1
二、使用步骤
1.文本生成模型下载
详细参考dqnapi号:100.35395/2023.150_v1
2.模型使用
stable-diffusion-webui 下载stable-diffusion-webui
代码如下(示例):
使用text2video扩展时:
1.下载zs2_576w文件夹中的文件。
将相应文件替换到'stable-diffusion-webui\models\ModelScope\t2v'目录中。
放大建议:
对于放大操作,建议使用zeroscope_v2_XL和vid2vid结合使用。在1024x576分辨率下,且去噪强度在0.66至0.85之间效果最佳。记得使用与生成原始剪辑时相同的提示。
2.在🧨 Diffusers中的用法:
首先安装所需的库:
$ pip install diffusers transformers accelerate torch
然后生成视频:
python
import torch
from diffusers import DiffusionPipeline, DPMSolverMultistepScheduler
from diffusers.utils import export_to_video
pipe = DiffusionPipeline.from_pretrained("cerspense/zeroscope_v2_576w", torch_dtype=torch.float16)
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
prompt = "Darth Vader is surfing on waves"
video_frames = pipe(prompt, num_inference_steps=40, height=320, width=576, num_frames=24).frames
video_path = export_to_video(video_frames)
总结
提示:这里对文章进行总结:
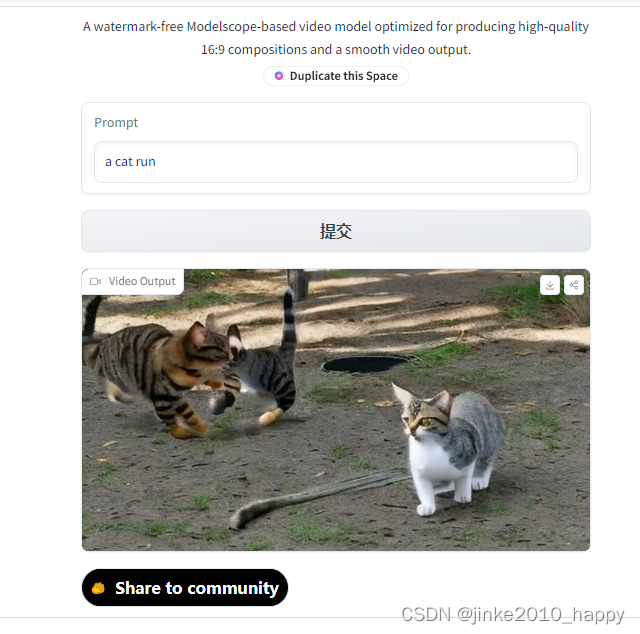
zeroscope_v2 576w是一种基于Modelscope的视频模型,经过优化,可产生高质量的16:9组合和平滑的视频输出。该模型是使用9,923个剪辑和29,769个标记过的帧以24帧、576x320分辨率训练得到的。
zeroscope_v2_576w可以与1111 text2video扩展中的zeroscope_v2_XL一起使用,通过vid2vid进行放大处理。利用这个模型作为初步步骤,可以在zeroscope_v2_XL中以更高的分辨率获得优秀的整体组合效果,允许在576x320分辨率下更快地进行探索,然后再转换到高分辨率渲染。以下是使用zeroscope_v2_XL将一些示例输出放大到1024x576的结果(由dotsimulate提供)。
当以576x320分辨率渲染30帧时,zeroscope_v2_576w使用7.9GB的显存。
以下是一些结果:a cat run















 404
404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









